
 Github
Github改进版NanoGPT
这是Andrej Karpathy的llm.c仓库中PyTorch GPT-2训练器的一个变体。它:
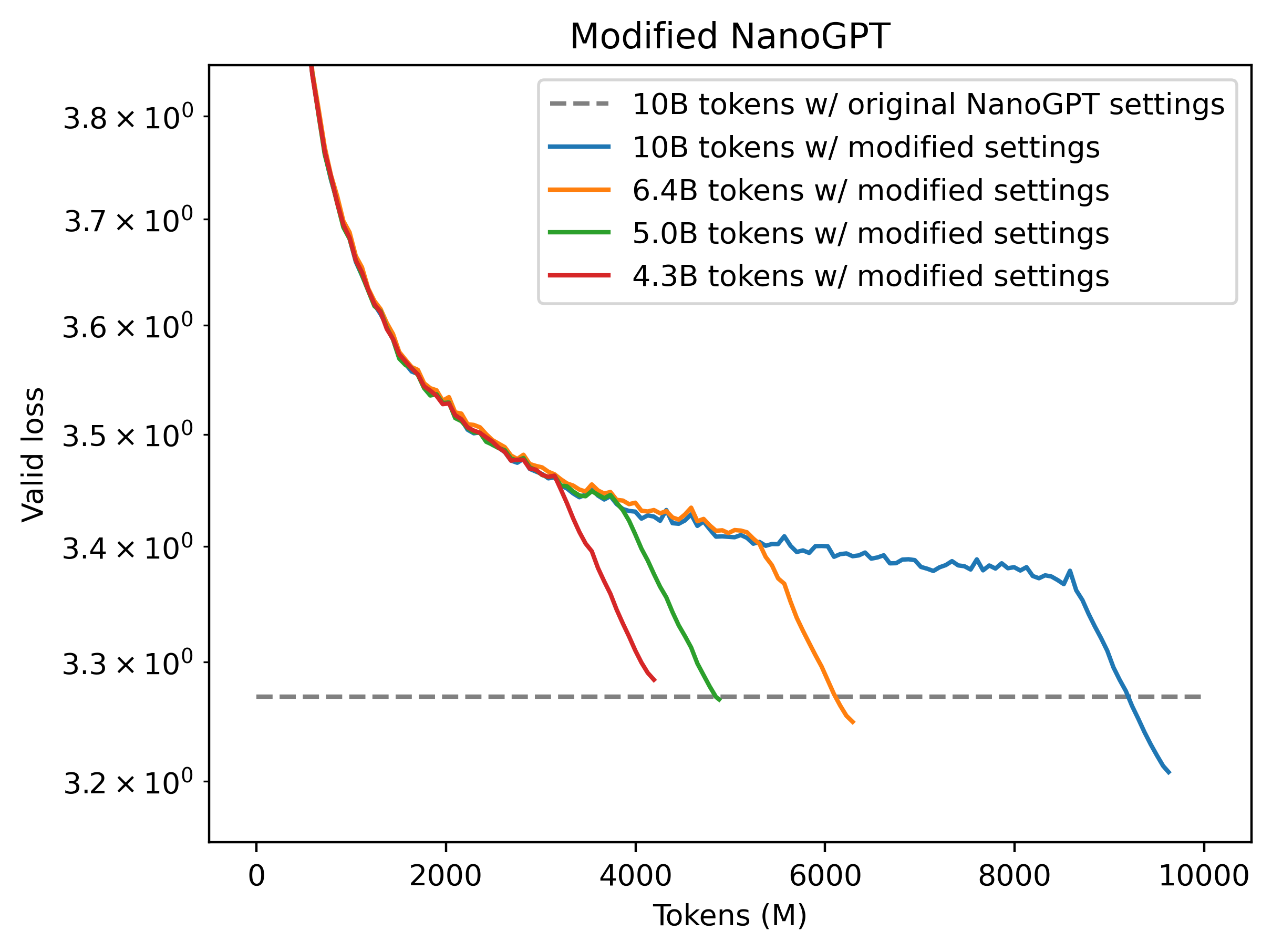
- 训练效率提高2倍(仅需5B个标记而不是10B个就能达到相同的验证损失)。
- 代码更简洁(446行而不是858行)。
- 实现了现代化改进,如旋转嵌入。
运行方法:
python data/fineweb.py
./run.sh
这将生成一个在5B个标记上训练的124M参数的transformer,在Fineweb验证集上的验证损失为3.2818。 作为对比,原始llm.c训练器在训练10B个标记后的验证损失为3.2847。
为了简化代码,一些功能已被移除,包括文本生成。为了提高训练速度,我们在架构和超参数方面与GPT-2论文的严格复现有所偏离。
速度提升归因于以下变更:
- 学习率提高3倍
- 切换到梯形学习率调度,参考2405.18392
- 切换到旋转嵌入
- 移除了残差前线性层的特殊初始化。取而代之的是,通过固定标量缩小注意力块的输出。
- 从架构中移除了所有仿射缩放和偏置参数,转而使用RMSNorm(实际上这会导致轻微的速度下降,我这样做只是为了减少代码复杂性)











