
模型优化技术:提升深度学习模型性能的关键方法
在深度学习领域,模型优化是一个至关重要的话题。随着神经网络模型变得越来越复杂,如何在有限的计算资源下提高模型的性能和效率成为了研究人员和工程师们面临的一大挑战。本文将深入探讨模型优化技术,介绍几种主要的优化方法及其应用,帮助读者全面了解这一关键领域。
模型优化的重要性
深度学习模型在图像识别、自然语言处理等多个领域取得了突破性进展,但同时也带来了巨大的计算开销。例如,GPT-3这样的大型语言模型包含1750亿个参数,训练和推理都需要海量的计算资源。因此,如何在保证模型性能的同时,降低计算复杂度、减少内存占用,成为了一个亟待解决的问题。
模型优化的目标主要包括以下几个方面:
-
提高推理速度:通过优化模型结构和计算流程,减少推理时的计算量,加快模型响应速度。
-
降低内存占用:减少模型参数量和中间计算结果的存储需求,使模型能够在资源受限的设备上运行。
-
减少能耗:降低模型的计算复杂度,减少能源消耗,特别是对于移动设备和边缘计算设备来说非常重要。
-
保持或提高精度:在进行优化的同时,确保模型的预测精度不会显著下降,甚至可能通过某些优化技术提高模型性能。
主要的模型优化技术
1. 量化(Quantization)
量化是一种将模型参数和激活值从高精度(如32位浮点数)转换为低精度表示(如8位整数)的技术。这种方法可以显著减少模型的存储空间和计算复杂度,同时在许多情况下对模型精度的影响很小。
量化主要有以下几种类型:
- 训练后量化(Post-Training Quantization, PTQ):在模型训练完成后进行量化,不需要重新训练,实现简单快速。
- 量化感知训练(Quantization-Aware Training, QAT):在训练过程中就考虑量化的影响,通过模拟量化操作来优化模型,通常可以获得更好的精度。
- 动态范围量化(Dynamic Range Quantization):在推理时动态确定量化参数,可以更好地适应不同的输入数据分布。

以上图为例,展示了模型压缩工具包(MCT)中的量化流程。它包括模型分析、量化参数搜索、图优化等步骤,最终输出一个优化后的量化模型。
量化的优势在于:
- 大幅减少模型大小,通常可以将模型体积压缩到原来的1/4左右。
- 加快推理速度,特别是在支持低精度运算的硬件上效果更为显著。
- 降低能耗,对于移动设备和边缘计算设备尤其重要。
然而,量化也面临一些挑战:
- 精度损失:虽然在许多情况下量化对精度影响不大,但在某些敏感的模型或任务中可能会导致明显的性能下降。
- 硬件支持:并非所有硬件都对低精度运算有良好的支持,需要根据目标平台选择合适的量化策略。
2. 剪枝(Pruning)
剪枝是通过移除神经网络中不重要的连接或神经元来减小模型规模的技术。这种方法基于这样一个观察:在大型神经网络中,并非所有参数对最终输出都有同等重要的影响。
剪枝主要有两种类型:
- 非结构化剪枝:直接移除权重矩阵中的单个元素。
- 结构化剪枝:移除整个卷积核、神经元或层,可以直接减少模型的计算量。
剪枝的过程通常包括以下步骤:
- 训练一个过参数化的大模型
- 评估参数重要性
- 移除不重要的参数
- 微调剪枝后的模型
剪枝的优势包括:
- 显著减少模型参数量和计算复杂度
- 可以与其他优化技术(如量化)结合使用
- 在某些情况下,适度的剪枝甚至可以提高模型泛化能力
然而,剪枝也面临一些挑战:
- 确定最优剪枝策略较为困难,需要在模型大小和性能之间权衡
- 对于已经比较紧凑的模型,剪枝可能会导致明显的性能下降
- 非结构化剪枝虽然可以大幅减少参数量,但可能无法直接转化为推理速度的提升
3. 知识蒸馏(Knowledge Distillation)
知识蒸馏是一种将复杂模型(教师模型)的知识迁移到简单模型(学生模型)的技术。这种方法的核心思想是,大模型不仅学习到了正确的类别预测,还捕获了类别之间的相似性关系,这些"软标签"包含了比硬标签更丰富的信息。
知识蒸馏的基本流程如下:
- 训练一个大型、高性能的教师模型
- 使用教师模型的输出(通常是softmax后的概率分布)作为软标签
- 训练一个更小的学生模型,同时学习原始的硬标签和教师模型提供的软标签
知识蒸馏的优势包括:
- 可以显著减小模型大小,同时保持较高的性能
- 学生模型可以从教师模型学到更细粒度的知识,有时甚至可以超越教师模型的性能
- 适用于各种类型的模型和任务
然而,知识蒸馏也面临一些挑战:
- 需要额外的计算资源来训练教师模型
- 选择合适的教师模型和学生模型架构可能需要大量实验
- 在某些复杂任务中,可能难以将大模型的全部知识迁移到小模型中
模型优化的实践案例
为了更好地理解模型优化技术的应用,我们来看几个具体的实例:
案例1: MobileNetV2的量化优化
MobileNetV2是一个专为移动设备设计的轻量级卷积神经网络。研究人员对其进行了量化优化,结果如下:
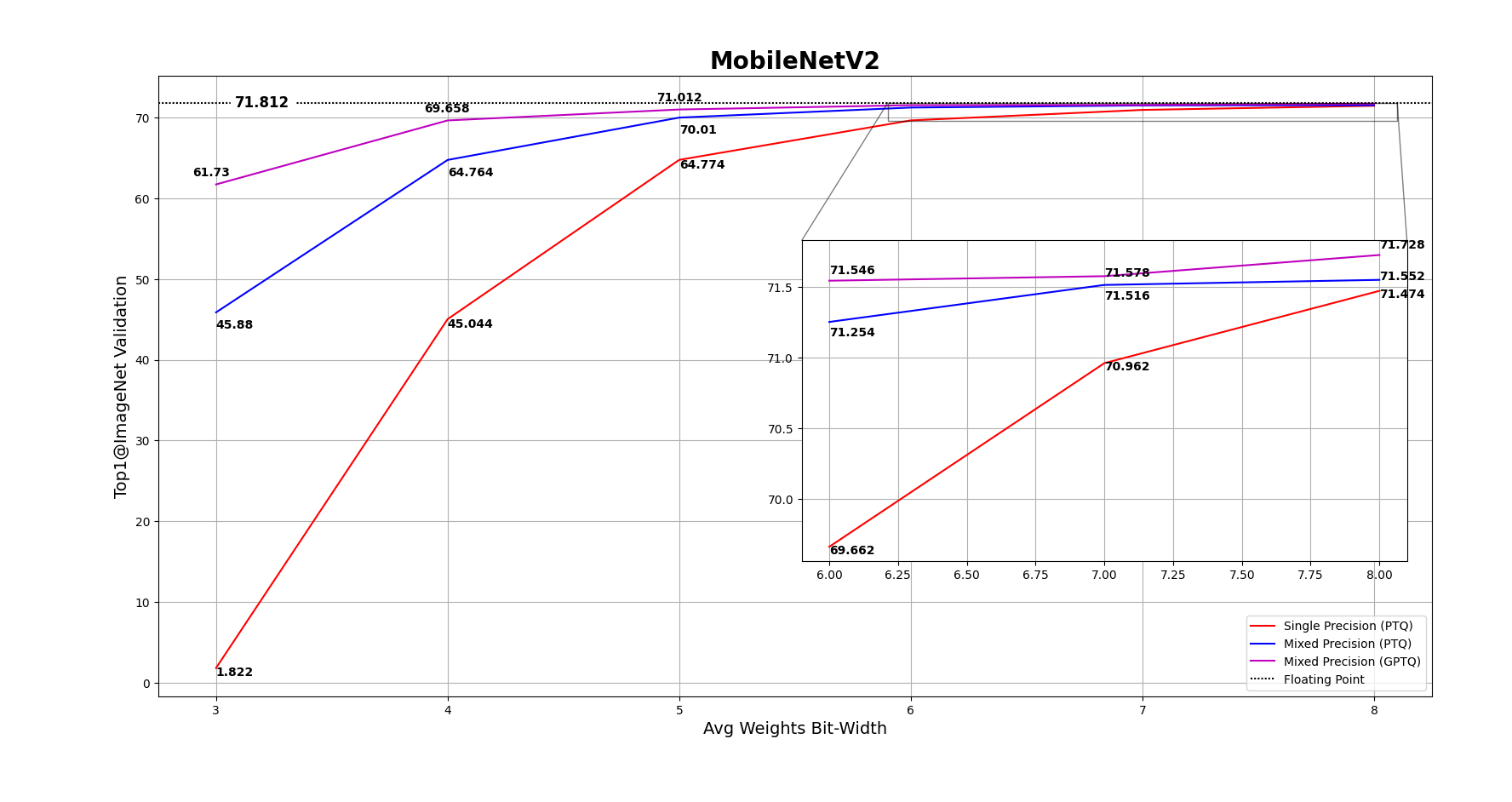
从图中可以看出:
- 单精度量化(蓝线)在bit宽度降低时,精度下降较为明显。
- 混合精度量化(橙线)能够在低bit宽度下保持较高的精度。
- 结合梯度的混合精度量化(绿线)在各个bit宽度下都能获得最佳性能。
这个案例说明,通过合适的量化策略,可以在大幅减少模型大小的同时,将精度损失控制在可接受的范围内。
案例2: ResNet50的结构化剪枝
研究人员对ResNet50模型进行了结构化剪枝,目标是将模型参数减少50%。结果如下:
- 原始模型精度: 75.1%
- 剪枝后模型精度: 72.4%
这个结果表明,即使移除了一半的参数,模型仍然保持了相当高的精度。这种优化可以大大减少模型的存储和计算需求,使其更适合在资源受限的环境中部署。
案例3: BERT模型的知识蒸馏
BERT是一个强大但计算复杂度高的自然语言处理模型。研究人员通过知识蒸馏,将BERT的知识迁移到了一个更小的模型中:
- 教师模型(BERT-base): 110M参数
- 学生模型(DistilBERT): 66M参数
- 性能保持: 学生模型在多个NLP任务上达到了教师模型95%的性能
这个案例展示了知识蒸馏在压缩大型语言模型方面的潜力,使得在计算资源有限的场景下也能部署强大的NLP模型。
模型优化的未来趋势
随着深度学习技术的不断发展,模型优化领域也在不断演进。以下是一些值得关注的未来趋势:
-
自动化优化:开发更智能的自动优化工具,能够根据具体任务和硬件约束自动选择最佳的优化策略。
-
硬件协同设计:将模型优化与硬件设计结合,开发专门针对优化后模型的高效芯片。
-
动态优化:根据运行时的资源情况和任务需求,动态调整模型结构和精度。
-
联邦学习中的模型优化:在保护隐私的前提下,研究如何在分布式环境中进行高效的模型优化。
-
可解释性与优化的权衡:研究如何在进行模型优化的同时,保持或提高模型的可解释性。
结论
模型优化是深度学习落地应用的关键环节。通过量化、剪枝、知识蒸馏等技术,我们可以显著提高模型的效率,使其能够在各种计算环境下高效运行。然而,模型优化并非一蹴而就,它需要在模型性能、计算效率和硬件兼容性之间寻找平衡。
随着研究的深入和新技术的出现,我们有理由相信,未来会涌现出更多创新的优化方法。这些进展将推动深度学习技术在更广泛的领域得到应用,为人工智能的发展注入新的动力。
对于研究人员和工程师而言,深入理解和灵活运用各种模型优化技术,将成为构建高效AI系统的重要技能。通过不断学习和实践,我们可以为AI的可持续发展贡献自己的力量。
参考资料
- Model Compression Toolkit (MCT)
- Han, S., Pool, J., Tran, J., & Dally, W. (2015). Learning both Weights and Connections for Efficient Neural Network. Advances in Neural Information Processing Systems, 28.
- Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the Knowledge in a Neural Network. arXiv preprint arXiv:1503.02531.
- Jacob, B., Kligys, S., Chen, B., Zhu, M., Tang, M., Howard, A., ... & Kalenichenko, D. (2018). Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 2704-2713).
- TensorFlow Model Optimization Toolkit
模型优化是一个富有挑战性且不断发展的领域。希望本文能为读者提供一个全面的概览,激发进一步探索和实践的兴趣。让我们共同努力,推动AI技术向着更高效、更智能的方向发展!









