
MORL-Baselines: 多目标强化学习的可靠基准工具包
多目标强化学习(Multi-Objective Reinforcement Learning, MORL)是强化学习的一个重要分支,旨在解决现实世界中存在多个甚至相互矛盾目标的决策问题。与传统的单目标强化学习不同,MORL需要在多个目标之间进行权衡,找到帕累托最优解集。然而,MORL领域长期缺乏标准化的算法实现和评估基准,这在一定程度上阻碍了该领域的发展。为了解决这一问题,研究人员开发了MORL-Baselines项目,旨在为MORL研究提供可靠的算法实现和评估工具。
MORL-Baselines简介
MORL-Baselines是一个开源的多目标强化学习算法库,由Lucas N. Alegre和Florian Felten等人开发和维护。该项目的主要目标是提供可靠的MORL算法实现,并与标准化的多目标强化学习环境MO-Gymnasium无缝集成,为研究人员提供一个统一的实验平台。
MORL-Baselines具有以下主要特点:
- 实现了多种经典和前沿的MORL算法,包括单策略和多策略方法。
- 严格遵循MO-Gymnasium API,与标准化环境完全兼容。
- 提供了自动化的性能评估和报告功能,支持使用Weights and Biases进行可视化。
- 代码结构清晰,文档完善,便于理解和扩展。
- 提供了多种实用工具函数,如帕累托前沿剪枝、经验回放缓冲区等。
- 支持超参数优化,便于算法调优。
支持的算法
MORL-Baselines实现了多种MORL算法,涵盖了单策略和多策略、基于期望累积回报(SER)和基于期望效用(ESR)等不同类型:
- GPI-LS + GPI-PD: 基于广义策略迭代的多策略算法
- MORL/D: 基于分解的多目标强化学习方法
- Envelope Q-Learning: 基于凸包的多策略Q学习算法
- CAPQL (Concave-Augmented Pareto Q-Learning): 凹增强帕累托Q学习
- PGMORL: 基于策略梯度的多目标强化学习
- Pareto Conditioned Networks (PCN): 帕累托条件网络
- Pareto Q-Learning: 帕累托Q学习
- MO Q-learning: 多目标Q学习
- MPMOQLearning: 多策略多目标Q学习
- Optimistic Linear Support (OLS): 乐观线性支持算法
- Expected Utility Policy Gradient (EUPG): 期望效用策略梯度
这些算法覆盖了离散和连续动作空间、离散和连续状态空间等不同情况,为研究人员提供了丰富的选择。
使用MORL-Baselines
使用MORL-Baselines非常简单,以下是一个基本的使用示例:
import mo_gymnasium as mo_gym
from morl_baselines.multi_policy.gpi_pd import GPIPD
# 创建多目标环境
env = mo_gym.make("deep-sea-treasure-v0")
# 初始化GPIPD算法
agent = GPIPD(env)
# 训练算法
agent.train(total_timesteps=100000)
# 评估算法
agent.eval()
MORL-Baselines还提供了丰富的配置选项,允许用户根据需要调整算法参数和训练设置。
性能评估与可视化
MORL-Baselines集成了Weights and Biases (wandb)工具,可以自动记录和可视化算法的训练过程和评估结果。这包括帕累托前沿的演化、超体积指标、期望效用等关键指标。
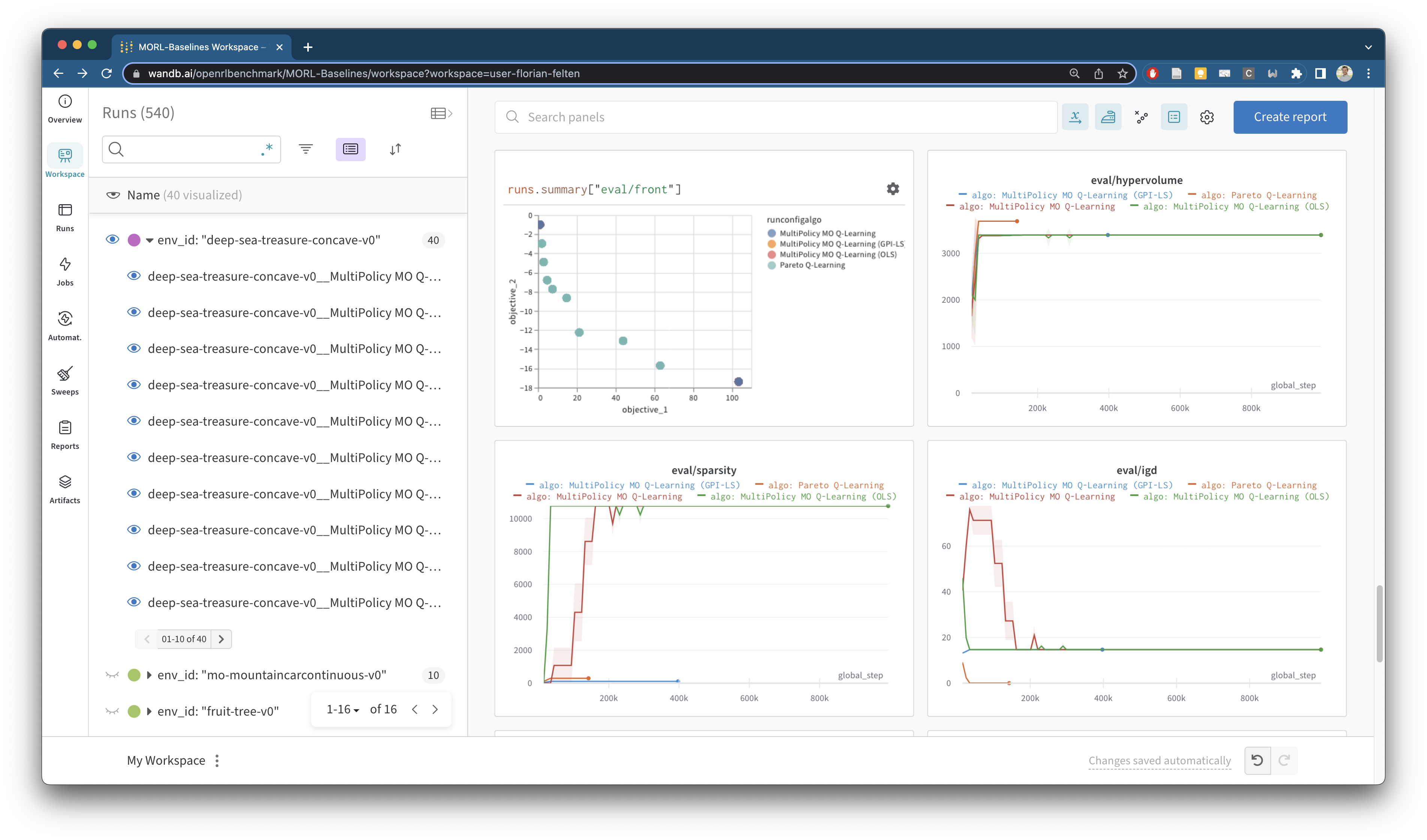
上图展示了MORL-Baselines使用wandb生成的性能仪表板,直观地展示了算法在多个目标上的权衡和收敛过程。
代码结构与扩展性
MORL-Baselines的代码结构清晰,便于理解和扩展:
examples/: 包含使用MORL-Baselines的示例代码common/: 实现了常用组件,如经验回放缓冲区、神经网络等multi_policy/: 包含多策略算法的实现single_policy/: 包含单策略算法的实现
这种结构使得研究人员可以轻松地添加新的算法或修改现有算法。
与MO-Gymnasium的集成
MORL-Baselines与MO-Gymnasium环境库紧密集成,后者提供了一系列标准化的多目标强化学习环境。这种集成确保了实验的一致性和可重复性,使不同算法的比较更加公平和可靠。
社区与贡献
MORL-Baselines是一个开源项目,欢迎社区贡献。研究人员可以通过以下方式参与:
- 提交新的算法实现
- 改进现有算法
- 添加新的功能或工具
- 报告和修复bug
- 改进文档
项目维护者鼓励通过GitHub issues或pull requests提交贡献,也可以加入项目的Discord服务器讨论想法。
总结与展望
MORL-Baselines为多目标强化学习研究提供了一个强大而灵活的工具包。通过提供标准化的算法实现和评估框架,它有望推动MORL领域的快速发展。未来,项目计划继续添加新的算法,改进性能评估方法,并扩展到更多类型的多目标问题。
对于有兴趣深入研究MORL的研究人员和实践者来说,MORL-Baselines无疑是一个值得关注和使用的重要资源。它不仅可以加速算法开发和实验过程,还为不同算法的公平比较提供了基础,有助于推动整个领域的进步。
随着人工智能在现实世界中的应用不断扩大,多目标决策问题必将变得越来越重要。MORL-Baselines的出现,为解决这类复杂问题提供了有力的工具支持。我们期待看到更多研究人员利用这一平台,在多目标强化学习领域取得突破性进展。









