
 访问官网
访问官网 Github
Github 文档
文档 论文
论文




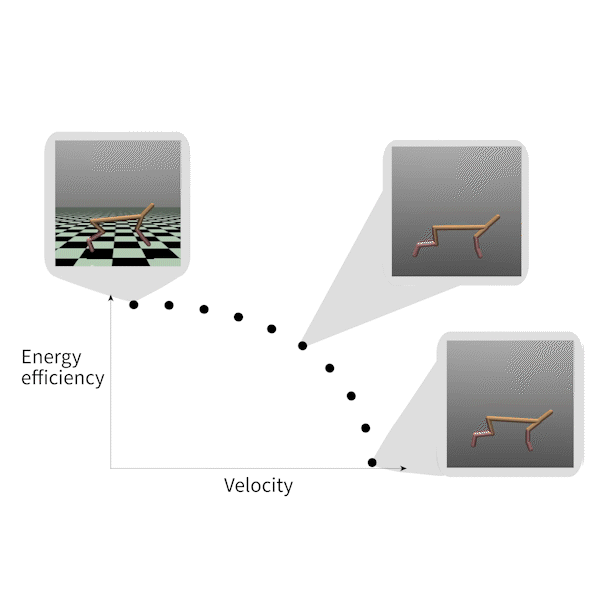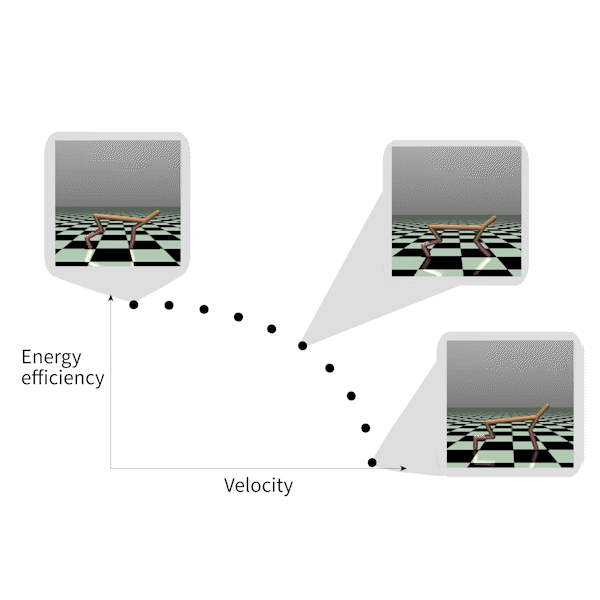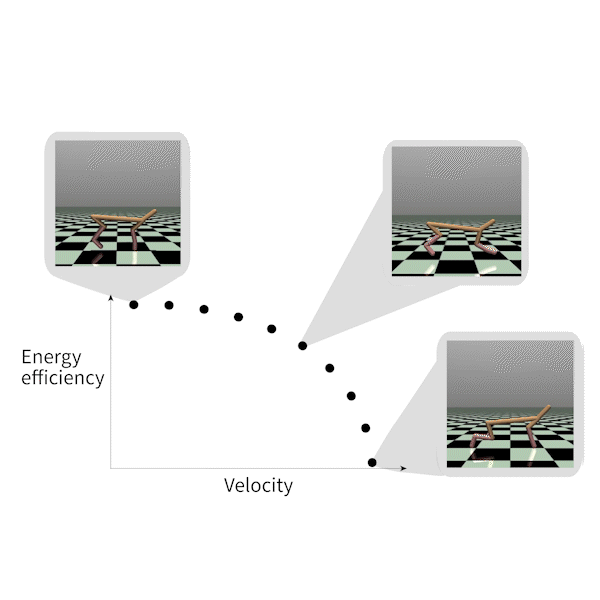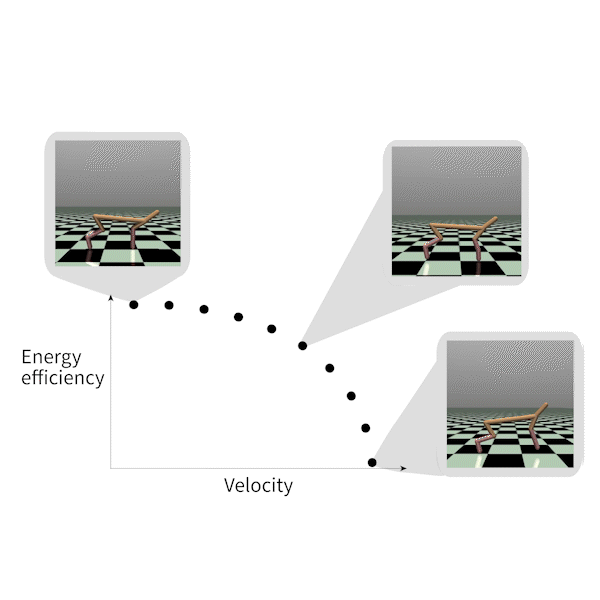
MORL-基准
MORL-基准是一个多目标强化学习(MORL)算法库。该仓库旨在使用PyTorch提供可靠的MORL算法实现。
它严格遵循MO-Gymnasium的API,该API与标准GymnasiumAPI的唯一区别在于环境返回一个numpy数组作为奖励。
关于多目标MDP(MOMDP)和其他MORL定义的详细信息,我们建议阅读多目标强化学习和规划的实用指南。基于分解的多目标强化学习:分类和框架中还提供了各种MORL算法中使用的一些技术概述。
MO-Gymnasium和MORL-基准的教程也可用:
特性
- 实现了SER和ESR标准下的单策略和多策略算法。
- 所有算法都遵循MO-Gymnasium的API。
- 性能自动报告在Weights and Biases仪表板上。
- 通过预提交钩子强制执行代码检查和格式化。
- 代码有良好的文档。
- 所有算法都经过自动测试。
- 提供实用函数,如帕累托修剪、经验缓冲等。
- 性能已经过测试并以可重现的方式报告。
- 提供超参数优化。
已实现的算法
| 名称 | 单策略/多策略 | ESR/SER | 观察空间 | 动作空间 | 论文 |
|---|---|---|---|---|---|
| GPI-LS + GPI-PD | 多策略 | SER | 连续 | 离散 / 连续 | 论文和补充材料 |
| MORL/D | 多策略 | / | / | / | 论文 |
| 包络Q学习 | 多策略 | SER | 连续 | 离散 | 论文 |
| CAPQL | 多策略 | SER | 连续 | 连续 | 论文 |
| PGMORL 1 | 多策略 | SER | 连续 | 连续 | 论文 / 补充材料 |
| 帕累托条件网络 (PCN) | 多策略 | SER/ESR 2 | 连续 | 离散 / 连续 | 论文 |
| 帕累托Q学习 | 多策略 | SER | 离散 | 离散 | 论文 |
| 多目标Q学习 | 单策略 | SER | 离散 | 离散 | 论文 |
| MPMOQLearning (外循环 MOQL) | 多策略 | SER | 离散 | 离散 | 论文 |
| 乐观线性支持 (OLS) | 多策略 | SER | / | / | 论文 第3.3节 |
| 期望效用策略梯度 (EUPG) | 单策略 | ESR | 离散 | 离散 | 论文 |
:warning: 部分算法功能有限。
1: 目前,PGMORL 仅限于具有2个目标的环境。
2: PCN 假设环境具有确定性转换。
基准测试
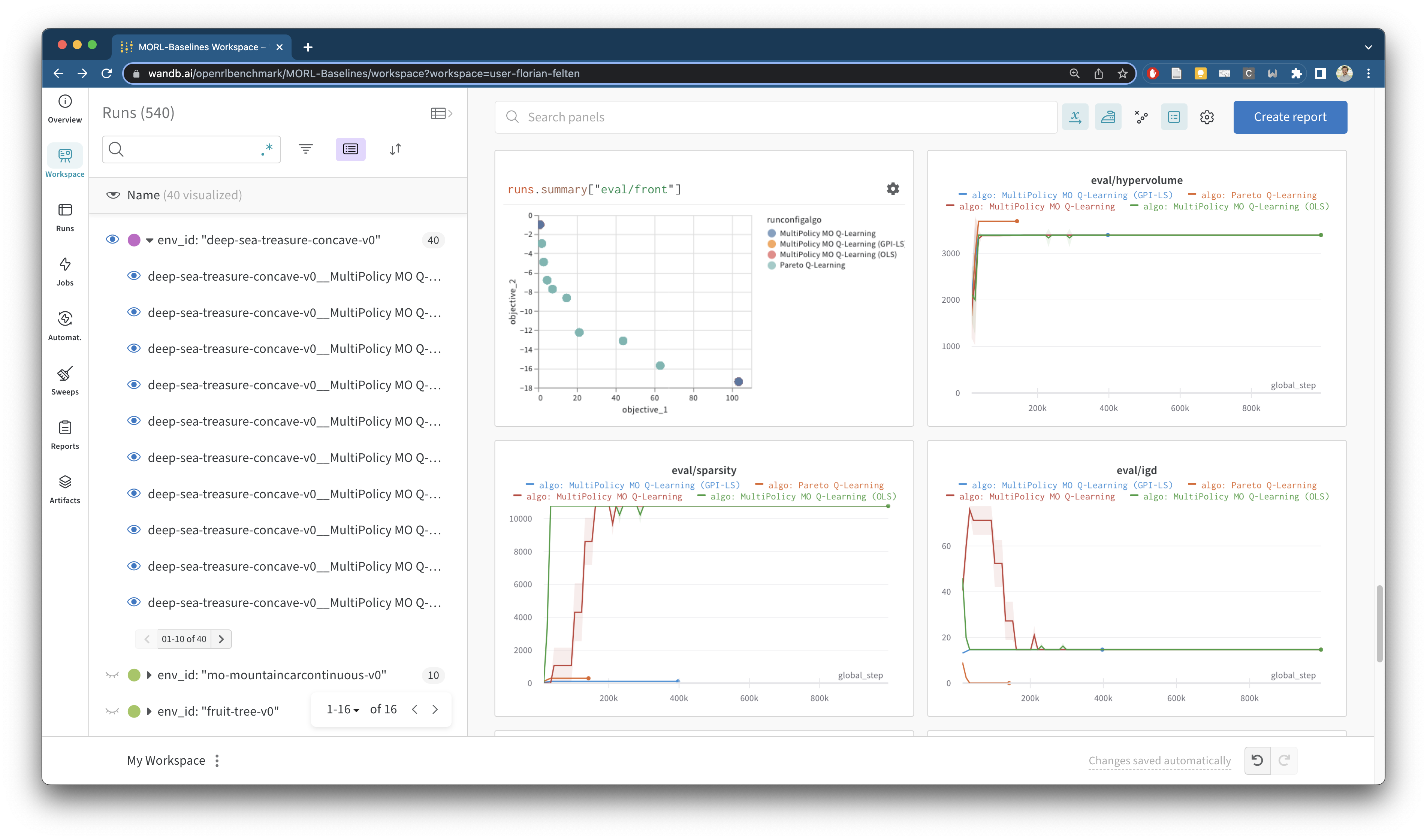
MORL-Baselines 参与了 Open RL Benchmark,该基准包含来自流行的强化学习库(如 cleanRL 和 Stable Baselines 3)的追踪实验。
我们已经在 MO-Gymnasium 的各种环境中运行了我们算法的实验。结果可以在这里找到:https://wandb.ai/openrlbenchmark/MORL-Baselines。追踪所有设置的问题可在 #43 中找到。实验协议的一些设计文档也可在我们的文档网站上找到。
下面展示了我们带有帕累托支持的仪表板可视化示例:
结构
这个仓库尽可能遵循所有算法的单文件实现规则。仓库的结构如下:
examples/包含一组使用 MO-Gymnasium 环境的 MORL Baselines 示例。common/包含常见概念的实现:重放缓冲区、神经网络等。更多详情请参阅文档。multi_policy/包含多策略算法的实现。single_policy/包含单策略算法的实现(ESR 和 SER)。
引用项目
如果您在研究中使用 MORL-Baselines,请引用我们的 NeurIPS 2023 论文:
@inproceedings{felten_toolkit_2023,
author = {Felten, Florian and Alegre, Lucas N. and Now{\'e}, Ann and Bazzan, Ana L. C. and Talbi, El Ghazali and Danoy, Gr{\'e}goire and Silva, Bruno Castro da},
title = {A Toolkit for Reliable Benchmarking and Research in Multi-Objective Reinforcement Learning},
booktitle = {Proceedings of the 37th Conference on Neural Information Processing Systems ({NeurIPS} 2023)},
year = {2023}
}
维护者
MORL-Baselines 目前由 Florian Felten (@ffelten) 和 Lucas N. Alegre (@LucasAlegre) 维护。
贡献
该仓库欢迎贡献,我们总是很高兴收到新的算法、错误修复或功能。如果您想贡献,可以加入我们的 Discord 服务器 并与我们讨论您的想法。您也可以直接开启一个问题或提交拉取请求。
致谢
- Willem Röpke,为他实现的帕累托 Q 学习 (@wilrop)
- Mathieu Reymond,为提供给我们 PCN 的原始实现。
- Denis Steckelmacher 和 Conor F. Hayes,为提供给我们 EUPG 的原始实现。











