
SRe2L: 大规模数据集蒸馏的突破性进展
在机器学习领域,数据集的质量和规模对模型性能至关重要。然而,随着数据集规模的不断扩大,训练和存储成本也随之上升。为了解决这一问题,研究人员提出了数据集蒸馏(Dataset Distillation)的概念,旨在从原始大规模数据集中提取出更小但同样有效的合成数据集。最近,来自Mohamed bin Zayed University of AI和Carnegie Mellon University的研究团队在这一领域取得了重大突破,提出了一种名为SRe2L (Squeeze, Recover and Relabel)的新型数据集蒸馏框架。
SRe2L框架简介
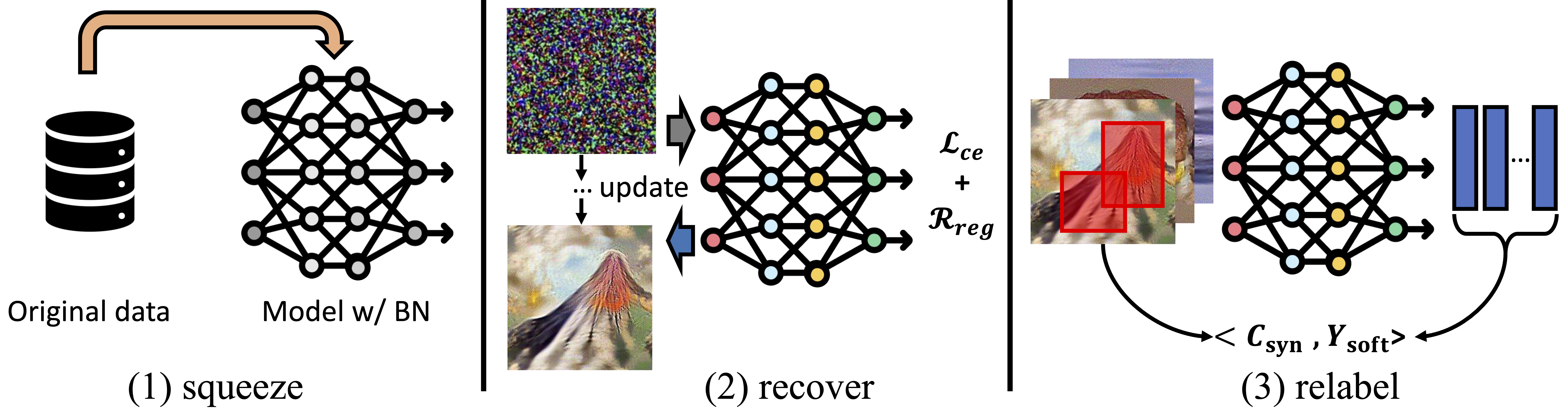
SRe2L框架由三个核心步骤组成:
- Squeeze(压缩): 将原始大规模数据集压缩成更小的表示。
- Recover(恢复): 从压缩表示中恢复出合成图像。
- Relabel(重新标注): 为合成图像生成新的软标签。
这种设计巧妙地解耦了模型和合成数据的双层优化过程,使得SRe2L能够灵活地处理不同规模的数据集、模型架构和图像分辨率。
突破性成果
SRe2L在大规模数据集蒸馏任务上取得了令人瞩目的成果:
- 在Tiny-ImageNet数据集上,使用每类50张图像(50 IPC)的设置,SRe2L达到了42.5%的验证准确率,比此前最好的方法提高了14.5个百分点。
- 在完整的ImageNet-1K数据集上,同样使用50 IPC的设置,SRe2L实现了60.8%的验证准确率,这一成绩比之前的最佳结果提高了惊人的32.9个百分点。
这些结果充分证明了SRe2L在处理大规模数据集蒸馏任务时的卓越能力。
技术优势
相比于现有方法,SRe2L具有以下显著优势:
- 高效性: 在数据合成过程中,SRe2L比MTT方法快约52倍(ConvNet-4架构)和16倍(ResNet-18架构)。
- 低内存消耗: SRe2L的内存使用量仅为MTT的1/11.6(ConvNet-4)和1/6.4(ResNet-18)。
- 灵活性: SRe2L可以生成任意分辨率的合成图像,并且能够适应不同规模的评估网络架构。
- 高分辨率训练: 得益于其低内存消耗特性,SRe2L能够实现高分辨率图像的训练,这在以往的方法中是难以实现的。
技术原理深入解析
SRe2L的核心创新在于其三步骤设计,让我们深入了解每个步骤的工作原理:
- Squeeze(压缩) 在这一步骤中,SRe2L使用自编码器网络将原始高维图像数据压缩成低维表示。这不仅大大减少了存储空间需求,还为后续的优化过程提供了一个更加紧凑的搜索空间。
- Recover(恢复) 恢复阶段使用一个生成器网络,将压缩后的低维表示重新转换为高维图像。这个过程允许模型在保留原始数据主要特征的同时,生成更加多样化和信息丰富的合成样本。
- Relabel(重新标注) 最后,SRe2L通过知识蒸馏技术为合成图像生成软标签。这些软标签不仅包含了类别信息,还编码了原始数据集中的细粒度语义知识,有助于提高合成数据集的表达能力。
实验结果与分析
研究团队在多个数据集上进行了广泛的实验,以验证SRe2L的有效性:
- Tiny-ImageNet实验
- 使用50 IPC设置,SRe2L达到42.5%的验证准确率
- 与基线方法相比,性能提升显著
- ImageNet-1K实验
- 50 IPC设置下,SRe2L实现60.8%的验证准确率
- 这一结果远超此前的最佳表现,展示了SRe2L在大规模数据集上的强大能力
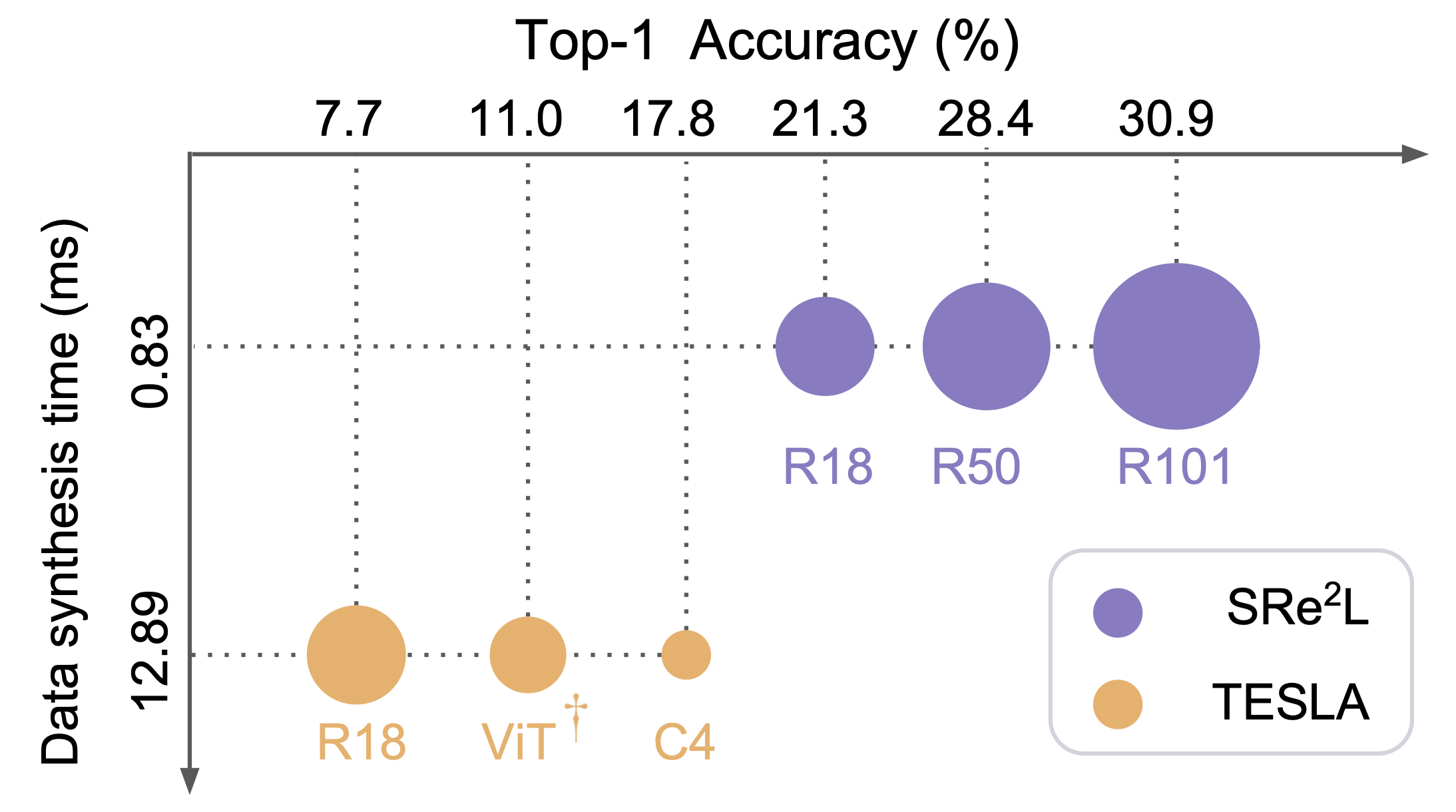
- 跨架构泛化性能
- SRe2L生成的合成数据集在不同规模的网络架构(如ResNet-18、ResNet-50、ResNet-101和ViT-T)上均表现出色
- 这证明了SRe2L具有良好的跨架构泛化能力
- 合成图像质量分析 研究者还对SRe2L生成的合成图像进行了可视化分析。结果表明,SRe2L生成的图像在语义上更加清晰,能够更好地捕捉目标类别的特征和轮廓。

潜在应用与影响
SRe2L的成功不仅是技术上的突破,还将对机器学习领域产生深远影响:
- 数据隐私保护: 通过使用合成数据集,可以在不泄露原始数据的情况下进行模型训练,有助于保护用户隐私。
- 降低计算成本: 小规模的合成数据集可以大幅减少模型训练时间和资源消耗,使得大规模机器学习任务变得更加经济实惠。
- 加速研究进程: 研究人员可以使用SRe2L生成的高质量小规模数据集快速验证新的算法和模型,加速科研进程。
- 边缘计算赋能: 小型化的数据集使得在资源受限的边缘设备上部署和更新机器学习模型成为可能。
- 提升数据质量: SRe2L的软标签技术有潜力生成比原始数据集更加"干净"的标签,有助于提高模型的鲁棒性。
未来研究方向
尽管SRe2L取得了显著成果,但研究团队指出仍有以下几个值得进一步探索的方向:
- 进一步提高合成数据的质量和多样性
- 探索在更多领域和任务上应用SRe2L技术
- 研究如何将SRe2L与其他先进的机器学习技术(如自监督学习、元学习等)结合
- 优化SRe2L在超大规模数据集上的性能和效率
结语
SRe2L的提出为大规模数据集蒸馏开辟了一条崭新的道路。它不仅在技术上实现了突破,还为解决机器学习领域中的数据规模、计算资源和隐私保护等关键问题提供了新的思路。随着这一技术的不断发展和完善,我们有理由相信,它将在推动人工智能技术更广泛应用和普及方面发挥重要作用。
对于研究人员和工程师而言,SRe2L提供了一个强大的工具,可以帮助他们更高效地开发和部署机器学习模型。对于普通用户,这项技术的发展意味着未来可能会有更多智能化的应用出现在我们的日常生活中,同时个人隐私也能得到更好的保护。
SRe2L的成功再次证明,在人工智能领域,创新的算法和框架设计能够带来质的飞跃。随着更多研究者投入到这一领域,我们期待看到更多令人兴奋的突破和应用。
参考资料
- Yin, Z., Xing, E., & Shen, Z. (2023). Squeeze, Recover and Relabel: Dataset Condensation at ImageNet Scale From A New Perspective. In Thirty-seventh Conference on Neural Information Processing Systems.
- SRe2L项目GitHub仓库: https://github.com/VILA-Lab/SRe2L
- SRe2L项目主页: https://zeyuanyin.github.io/projects/SRe2L/
通过深入了解SRe2L这一创新技术,我们不仅能够欣赏到人工智能领域的最新进展,还能够思考如何将这些技术应用到实际问题中,推动社会的进步与发展。让我们共同期待SRe2L及相关技术在未来带来的更多可能性。










