nnabla-rl: 强大而灵活的深度强化学习框架
nnabla-rl是由Sony开发的一款功能强大、使用灵活的深度强化学习框架。它建立在Sony的神经网络库nnabla之上,为研究人员和开发者提供了一个全面的工具包,用于探索和应用最新的强化学习技术。
框架特点
nnabla-rl的设计理念是"简单易用,功能强大"。它具有以下几个突出特点:
- 友好的API:仅需几行代码即可开始训练。例如:
import nnabla_rl.algorithms as A
from nnabla_rl.utils.reproductions import build_classic_control_env
env = build_classic_control_env("Pendulum-v1", render=True)
ddpg = A.DDPG(env, config=A.DDPGConfig(start_timesteps=200))
ddpg.train(env)
-
丰富的算法库:内置了大量经典和前沿的强化学习算法,如DQN、SAC、BCQ、GAIL等。这些算法都经过了仔细的测试和评估。
-
在线和离线训练无缝切换:支持在线交互训练和离线批量训练,可以轻松地在两种模式间切换。这对于从仿真环境到真实环境的迁移学习非常有用。
-
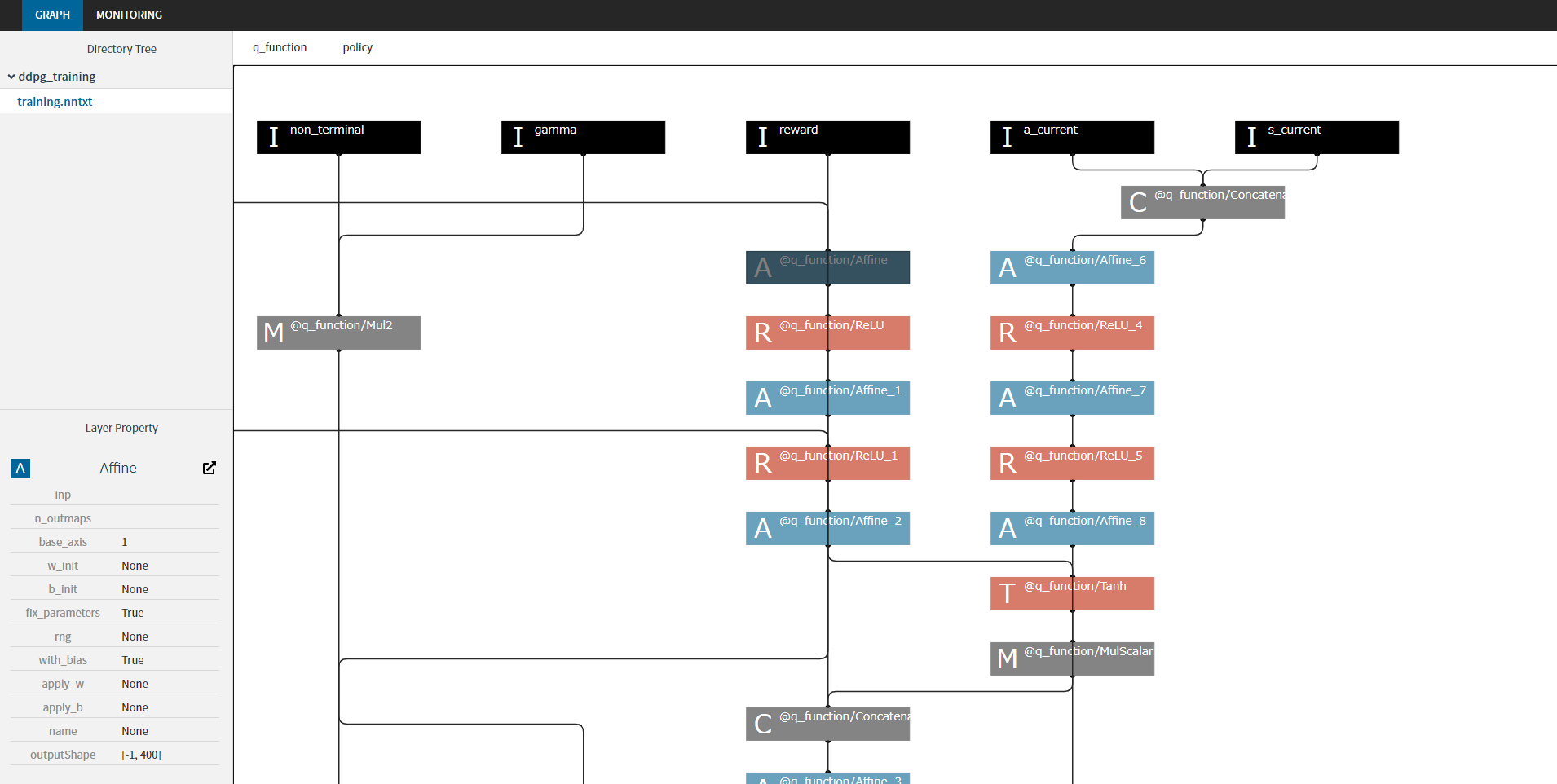
可视化支持:集成了nnabla-browser,可以方便地可视化训练过程和计算图。
安装和使用
nnabla-rl支持Python 3.8及以上版本,安装非常简单:
pip install nnabla-rl
如果需要GPU加速,还需要安装nnabla-ext-cuda:
pip install nnabla-ext-cuda[cuda-version]
快速入门
nnabla-rl提供了一系列交互式的Colab notebook,帮助用户快速上手:
- 简单的强化学习训练入门
- 学习如何使用训练算法
- 学习如何使用自定义网络模型进行训练
- 学习如何使用不同的网络求解器进行训练
- 学习如何使用不同的回放缓冲区进行训练
- 学习如何使用自定义环境进行训练
- Atari游戏训练示例
这些教程涵盖了从基础概念到高级应用的各个方面,是入门和深入学习nnabla-rl的绝佳资源。
高级特性
-
多种环境支持:除了经典的OpenAI Gym环境,nnabla-rl还支持Atari游戏等复杂环境。
-
自定义模型:用户可以轻松定义和使用自定义的神经网络模型。
-
灵活的配置:大多数算法参数都可以通过配置对象进行调整,方便进行实验。
-
丰富的回放缓冲区选项:提供多种回放缓冲区实现,适应不同的训练需求。
-
钩子机制:允许用户在训练过程中插入自定义逻辑,如日志记录、模型保存等。
应用案例
nnabla-rl在多个领域都有潜在的应用:
- 机器人控制:利用强化学习算法训练机器人执行复杂任务。
- 游戏AI:在Atari等游戏中训练智能体。
- 推荐系统:使用强化学习优化推荐策略。
- 自动驾驶:训练车辆在模拟环境中学习驾驶策略。
- 金融交易:开发基于强化学习的交易策略。
社区和贡献
nnabla-rl是一个开源项目,欢迎社区贡献。贡献方式包括但不限于:
- 报告bug和提出改进建议
- 提交新的算法实现
- 改进文档和示例
- 分享使用经验和应用案例
详细的贡献指南可以在项目的GitHub仓库中找到。
总结
nnabla-rl作为一个全面而灵活的深度强化学习框架,为研究人员和开发者提供了强大的工具。无论是进行学术研究还是开发实际应用,nnabla-rl都是一个值得考虑的选择。随着强化学习技术的不断发展,我们可以期待看到更多基于nnabla-rl的创新应用出现。