
 访问官网
访问官网 Github
Github 文档
文档



基于神经网络库构建的深度强化学习库
nnablaRL 是一个基于神经网络库构建的深度强化学习库,旨在用于研究、开发和生产。
安装
安装 nnablaRL 非常简单!
$ pip install nnabla-rl
nnablaRL 仅支持 Python 版本 >= 3.8 和 nnabla 版本 >= 1.17。
启用 GPU 加速(可选)
nnablaRL 算法默认在 CPU 上运行。要在 GPU 上运行算法,首先按如下方式安装 nnabla-ext-cuda。 (根据您机器上安装的 CUDA 版本替换 [cuda-version]。)
$ pip install nnabla-ext-cuda[cuda-version]
# 安装示例。假设您的机器上安装了 CUDA 11.0。
$ pip install nnabla-ext-cuda110
安装 nnabla-ext-cuda 后,通过算法的配置设置要运行的 GPU ID。
import nnabla_rl.algorithms as A
config = A.DQNConfig(gpu_id=0) # 使用 GPU 0。如果为负数,将在 CPU 上运行。
dqn = A.DQN(env, config=config)
...
特性
友好的 API
nnablaRL 具有友好的 Python API,只需 3 行 Python 代码即可开始训练。 (注意:以下代码将在 CPU 上运行。请参阅上述说明以在 GPU 上运行。)
import nnabla_rl.algorithms as A
from nnabla_rl.utils.reproductions import build_classic_control_env
# 先决条件:
# 运行以下命令以启用渲染!
# $ pip install nnabla-rl[render]
env = build_classic_control_env("Pendulum-v1", render=True) # 1
ddpg = A.DDPG(env, config=A.DDPGConfig(start_timesteps=200)) # 2
ddpg.train(env) # 3
要获取有关 nnablaRL 的更多详细信息,请参阅文档和示例。
众多内置算法
nnablaRL 实现了大多数著名/最先进的深度强化学习算法,如 DQN、SAC、BCQ、GAIL 等。已实现的算法经过仔细测试和评估。您可以轻松地使用这些经过验证的实现开始训练您的代理。
有关已实现算法的列表,请参见此处。
您还可以在此处找到每种算法的复现和评估结果。 请注意,在您的计算机上运行复现代码时,可能无法获得完全相同的结果。结果可能会根据您的机器、nnabla/nnabla-rl 的包版本等略有变化。
在线和离线训练的无缝切换
在强化学习中,有两种主要的训练程序来训练智能体:在线训练和离线训练。
在线训练是一种交替执行数据收集和网络更新的训练程序。相反,离线训习是一种仅使用现有数据更新网络的训练程序。使用nnablaRL,您可以无缝切换这两种训练程序。例如,如下所示,您可以轻松地使用模拟环境在线训练机器人控制器,然后使用真实机器人数据集离线微调它。
import nnabla_rl
import nnabla_rl.algorithms as A
simulator = get_simulator() # 这只是一个示例。假设模拟器存在
dqn = A.DQN(simulator)
# 在线训练100万次迭代
dqn.train_online(simulator, total_iterations=1000000)
real_data = get_real_robot_data() # 这也是一个示例。假设您有真实机器人数据
# 使用真实数据离线微调智能体1万次迭代
dqn.train_offline(real_data, total_iterations=10000)
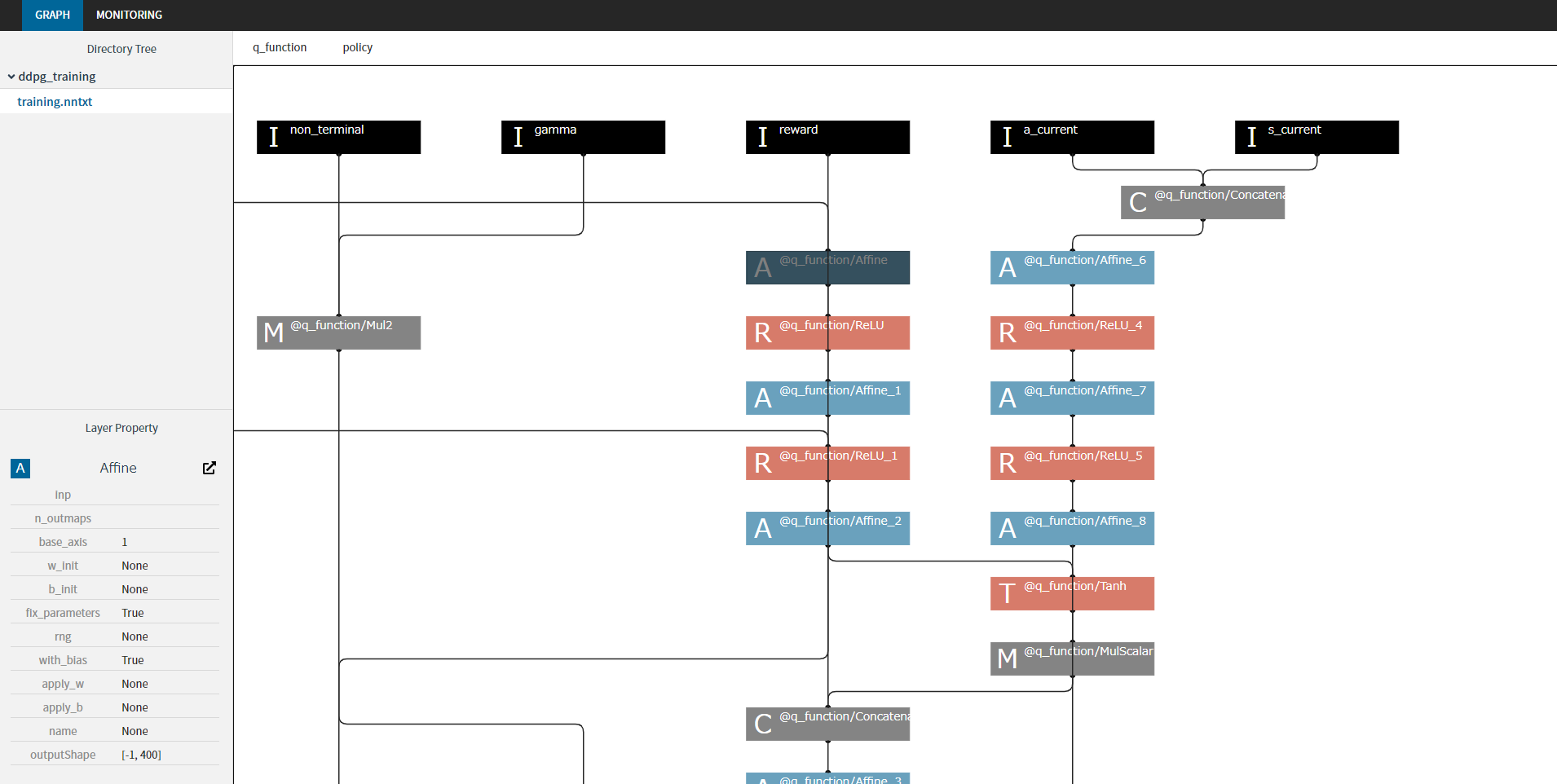
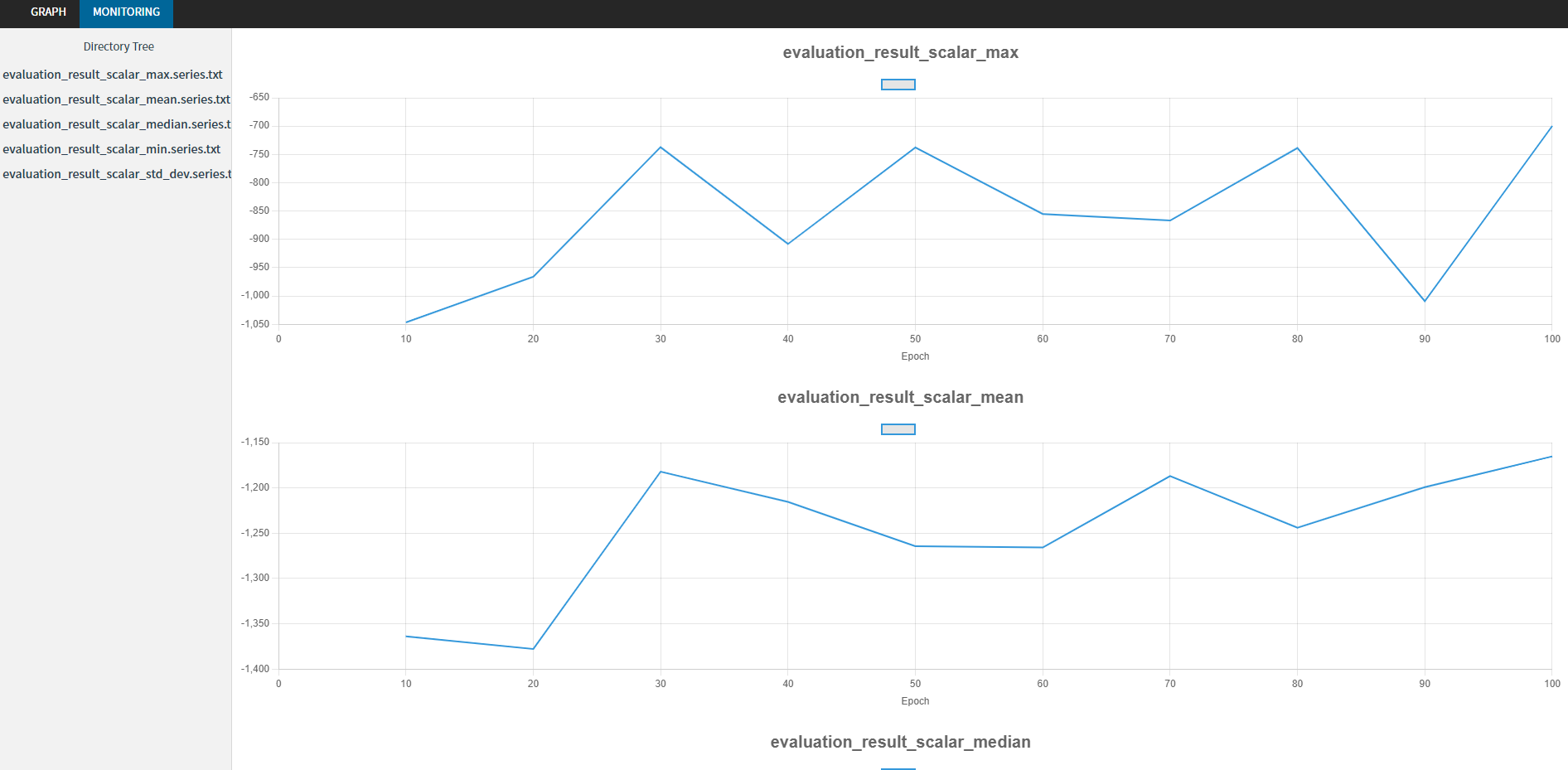
训练图和训练进度的可视化
nnablaRL支持使用nnabla-browser可视化训练图和训练进度!
import gym
import nnabla_rl.algorithms as A
import nnabla_rl.hooks as H
import nnabla_rl.writers as W
from nnabla_rl.utils.evaluator import EpisodicEvaluator
# 保存训练计算图
training_graph_hook = H.TrainingGraphHook(outdir="test")
# 使用nnabla的Monitor进行评估钩子
eval_env = gym.make("Pendulum-v0")
evaluator = EpisodicEvaluator(run_per_evaluation=10)
evaluation_hook = H.EvaluationHook(
eval_env,
evaluator,
timing=10,
writer=W.MonitorWriter(outdir="test", file_prefix='evaluation_result'),
)
env = gym.make("Pendulum-v0")
sac = A.SAC(env)
sac.set_hooks([training_graph_hook, evaluation_hook])
sac.train_online(env, total_iterations=100)
入门
尝试以下交互式演示来开始。
您可以直接在Colab上从下表的链接运行它。
| 标题 | 笔记本 | 目标强化学习任务 |
|---|---|---|
| 入门简单强化学习训练 |  | 倒立摆 |
| 学习如何使用训练算法 | | 倒立摆 |
| 学习如何使用自定义网络模型进行训练 | | 山地车 |
| 学习如何使用不同的网络求解器进行训练 | | 倒立摆 |
| 学习如何使用不同的回放缓冲区进行训练 | | 倒立摆 |
| 学习如何使用自己的环境进行训练 | | 自定义环境 |
| 雅达利游戏训练示例 | | 雅达利游戏 |
文档
完整文档在这里。
贡献指南
欢迎对nnablaRL进行任何形式的贡献!详情请参阅贡献指南。
许可证
nnablaRL 根据Apache License Version 2.0许可证提供。











