
Online-RLHF项目简介
Online-RLHF(Online Reinforcement Learning from Human Feedback)是一个开源项目,旨在通过在线迭代强化学习来改进大型语言模型(LLM)的性能。该项目由RLHFlow团队开发,提供了一套详细的工作流程,可以帮助研究人员和开发者实现在线RLHF。
与传统的离线RLHF相比,在线RLHF被报道在最新的LLM文献中表现出更好的效果。然而,现有的开源RLHF项目大多局限于离线学习设置。Online-RLHF项目填补了这一空白,为在线迭代RLHF提供了一个易于复现的详细流程。
主要特点
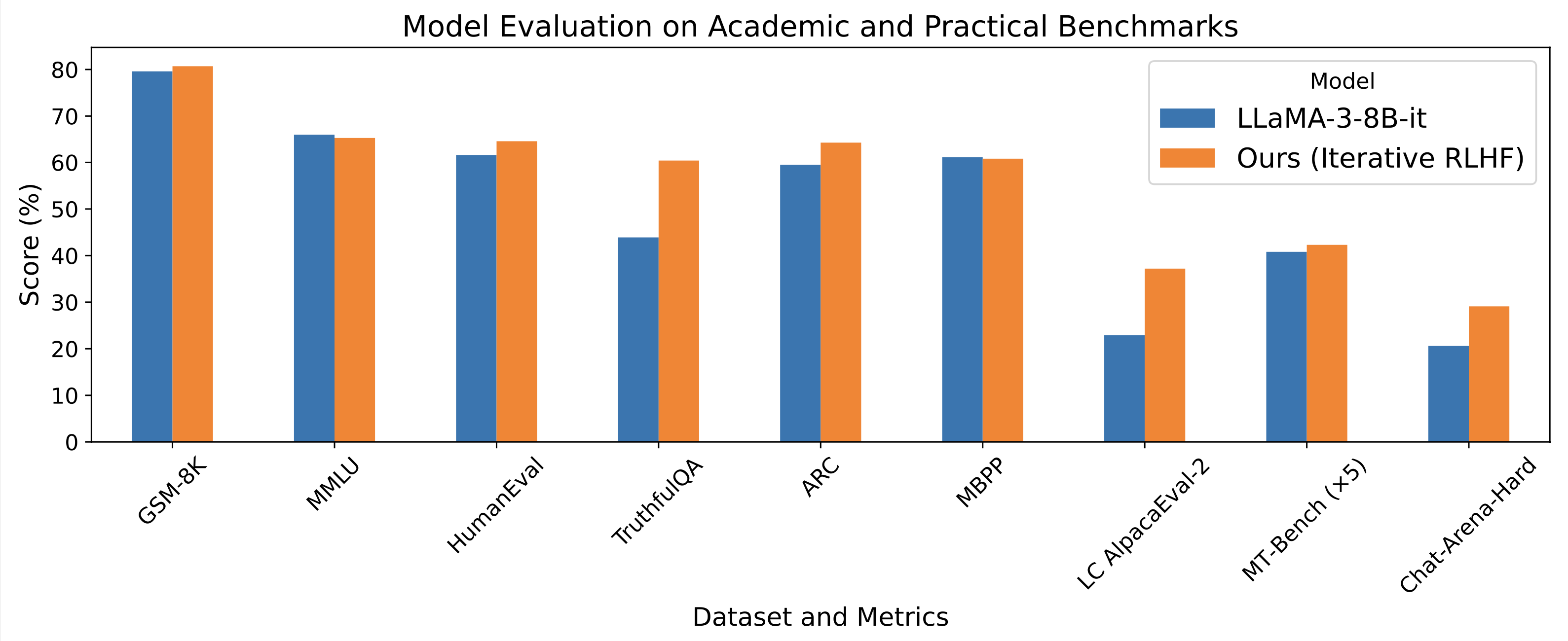
- 只使用开源数据,就能达到甚至超越LLaMA3-8B-instruct的性能
- 提供了完整的工作流程,包括监督微调、奖励建模、数据生成和注释、训练等步骤
- 开源了模型、数据集和完整的代码指南
安装和使用
项目推荐使用两个独立的环境进行推理和训练:
- 推理环境:
conda create -n vllm python=3.10.9
conda activate vllm
pip install datasets
# 安装其他依赖...
- 训练环境:
conda create -n rlhflow python=3.10.9
conda activate rlhflow
# 安装其他依赖...
具体的安装步骤和使用方法,请参考项目GitHub页面。
相关资源
项目成果
Online-RLHF在多个LLM聊天机器人基准测试中取得了令人印象深刻的性能,包括AlpacaEval-2、Arena-Hard和MT-Bench,以及其他学术基准如HumanEval和TruthfulQA。
总结
Online-RLHF项目为研究人员和开发者提供了一个强大的工具,用于改进大型语言模型的性能。通过提供详细的工作流程和开源资源,该项目使得在线RLHF技术更加易于理解和实现。无论您是AI研究人员还是对语言模型感兴趣的开发者,Online-RLHF都值得深入探索。










