
Online-RLHF:从奖励建模到在线人类反馈强化学习的工作流程
在过去几年中,人类反馈强化学习(Reinforcement Learning from Human Feedback, RLHF)技术在大语言模型(LLMs)对齐方面取得了显著进展。然而,目前开源社区中的RLHF项目大多局限于离线学习设置。为了填补这一空白,本文将详细介绍在线迭代RLHF的完整工作流程,并提供易于复现的实践指南。
背景与意义
RLHF技术旨在通过人类反馈来优化语言模型,使其输出更符合人类偏好。与传统的离线RLHF相比,在线迭代RLHF可以不断从新生成的数据中学习,从而获得更好的性能。然而,现有的开源RLHF项目大多停留在离线学习阶段,缺乏完整的在线迭代RLHF实现方案。
本项目的主要目标是:
- 提供从奖励建模到在线RLHF的端到端工作流程
- 设计易于复现的实践方案,降低实施门槛
- 仅使用开源数据,实现与LLaMA3-8B-instruct相当甚至更优的性能
工作流程概述
在线迭代RLHF的完整工作流程主要包括以下几个关键步骤:
- 监督微调(Supervised Fine-tuning, SFT):对预训练语言模型进行初步微调
- 奖励建模(Reward Modeling):构建能够评估文本质量的奖励模型
- 数据生成:使用当前模型生成新的文本样本
- 数据标注:利用奖励模型对生成的样本进行评分
- 强化学习训练:基于标注数据对模型进行优化
- 迭代优化:重复步骤3-5,不断提升模型性能
关键技术详解
1. 监督微调(SFT)
监督微调是RLHF流程的第一步,旨在让预训练语言模型初步适应目标任务。本项目使用了标准格式的数据集进行SFT,可以根据计算资源调整批次大小等超参数。
SFT训练命令示例:
accelerate launch ./sft/sft.py
2. 奖励建模
奖励模型是RLHF的核心组件,用于评估生成文本的质量。本项目训练了多个先进的开源奖励模型,如sfairXC/FsfairX-LLaMA3-RM-v0.1和RLHFlow/pair-preference-model-LLaMA3-8B。
3. 数据生成
为了加速数据生成过程,本项目采用了VLLM技术。提供了两种方式使用VLLM进行推理:
- 初始化多个VLLM进程,将提示集分割到不同的代理上
- 使用API服务器生成新的响应
数据生成脚本示例:
bash test_gen.sh
4. 数据标注
使用步骤2中训练的奖励模型对生成的响应进行排序和评分。
标注命令示例:
accelerate launch ./annotate_data/get_rewards.py --dataset_name_or_path ./data/gen_data.json --output_dir ./data/data_with_rewards.json --K 4
5. 强化学习训练
本项目采用Direct Preference Optimization (DPO)算法进行强化学习训练。DPO是一种直接优化策略的方法,无需显式构建奖励模型。
训练命令示例:
accelerate launch --config_file ./configs/zero2.yaml ./dpo_iteration/run_dpo.py --run_name rlhflow_iter1 --output_dir ./models/rlhflow_iter1 --model_name_or_path $model_path --ref_model $initial_model --learning_rate 2e-7 --max_steps 1200 --choose_type max_min --train_dir ./data/data_with_rewards.json --eval_dir ./data/data_with_rewards.json --loss_type sigmoid --lr_scheduler_type cosine
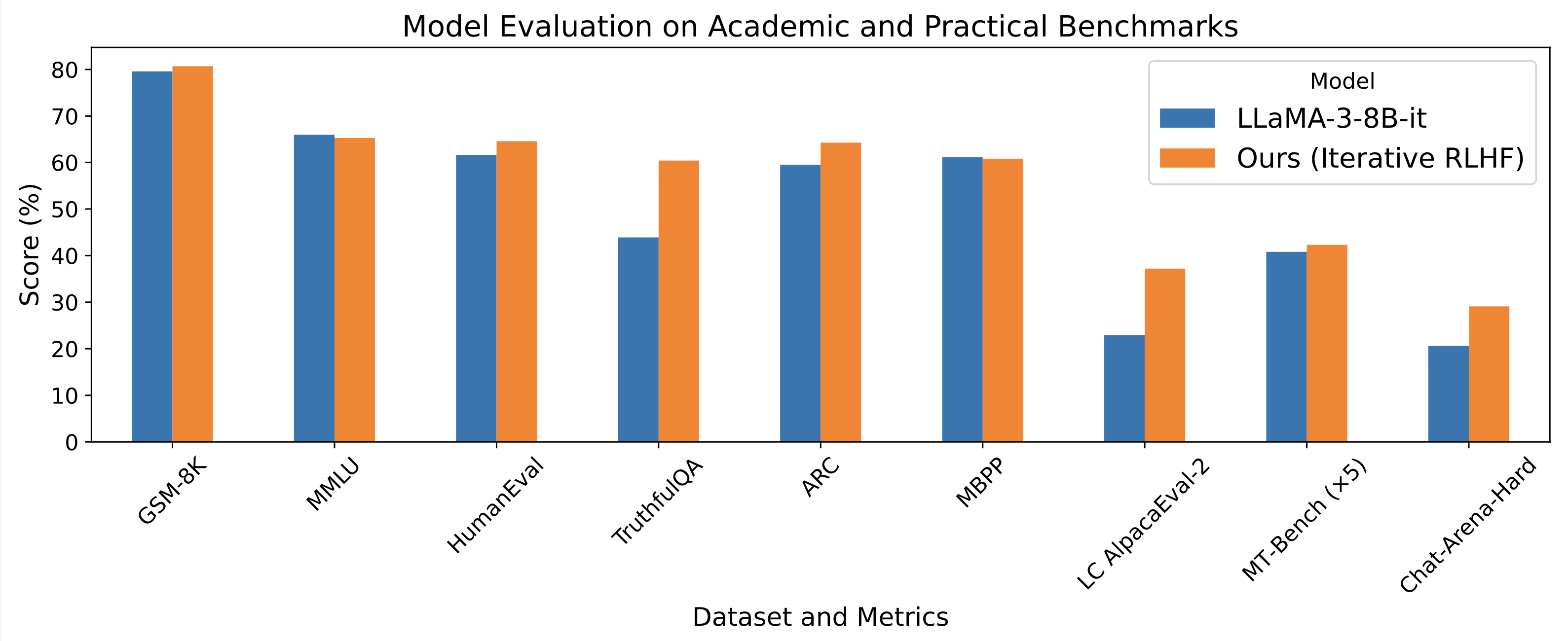
实验结果与分析
通过在线迭代RLHF训练,本项目在多个评估基准上取得了出色的表现:
- AlpacaEval-2
- Arena-Hard
- MT-Bench
- HumanEval
- TruthfulQA
实验结果表明,仅使用开源数据集进行监督微调和迭代RLHF,就能达到与闭源模型相当的性能水平。这为开源社区在大语言模型对齐方面的研究提供了有力支持。
未来展望
尽管本项目在推动开源RLHF研究方面取得了显著进展,但仍存在一些值得进一步探索的方向:
- 探索更多的奖励建模技术,提高评估的准确性和稳定性
- 研究更高效的数据生成和标注策略,降低计算资源需求
- 改进强化学习算法,提升模型优化效果
- 扩展到更大规模的语言模型,如200B以上参数量的模型
- 探索在线RLHF在特定领域任务中的应用
结论
本文详细介绍了从奖励建模到在线人类反馈强化学习的完整工作流程,并提供了可复现的实践指南。通过仅使用开源数据和模型,我们实现了与封闭源模型相当甚至更优的性能。这一工作为开源社区在大语言模型对齐研究方面提供了有力支持,也为未来在这一领域的进一步探索奠定了基础。
我们希望本项目能够推动RLHF技术的普及和发展,促进更多研究者参与到这一重要领域中来。同时,我们也呼吁开源社区继续关注并贡献于RLHF相关研究,共同推动大语言模型向着更加智能、安全和有益于人类的方向发展。










