
ParallelWaveGAN简介
ParallelWaveGAN是一种基于生成对抗网络(GAN)的神经声码器,由日本名古屋大学的研究人员于2019年提出。它是一种非自回归的波形生成模型,可以实现快速高效的语音合成。
与传统的自回归模型相比,ParallelWaveGAN具有以下几个主要优势:
- 生成速度快,可以实现实时语音合成
- 计算复杂度低,对硬件要求不高
- 生成音质好,可以产生自然流畅的语音
ParallelWaveGAN的核心思想是使用GAN的框架来训练一个非自回归的WaveNet模型。生成器采用了类似WaveNet的dilated卷积网络结构,但去掉了自回归连接,实现了并行生成。判别器则采用多分辨率频谱图的结构,可以更好地捕捉不同时间尺度上的语音特征。
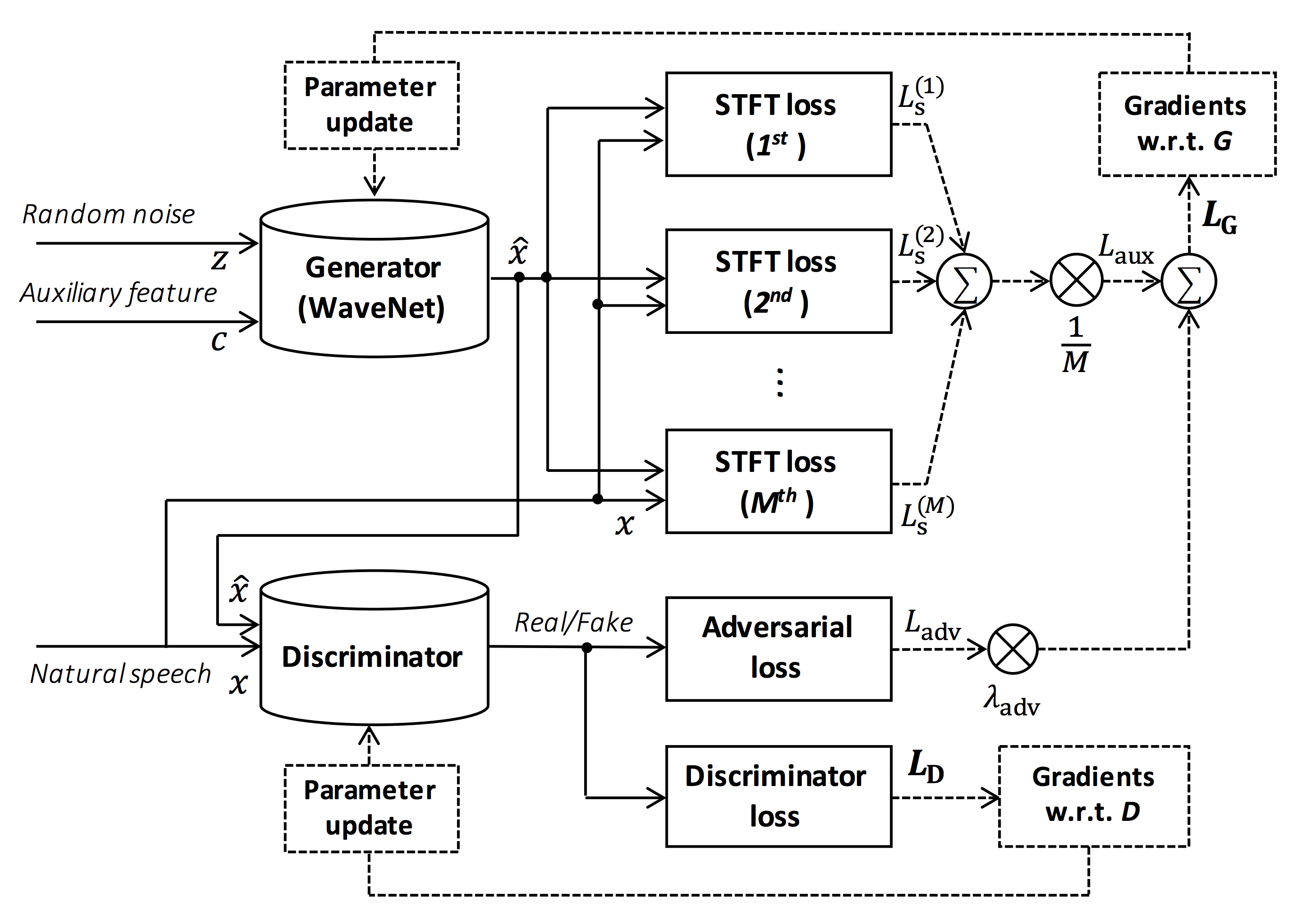
ParallelWaveGAN的工作原理
ParallelWaveGAN的训练过程包括以下几个关键步骤:
-
生成器G接收条件特征(如梅尔频谱图)作为输入,生成原始波形。
-
判别器D接收真实语音和生成的语音作为输入,判断其真伪。
-
生成器通过最小化对抗损失和多分辨率频谱图损失进行优化。
-
判别器通过最大化对抗损失进行优化。
-
交替训练生成器和判别器,直到收敛。
在推理阶段,只需要使用训练好的生成器即可。给定条件特征,生成器可以一次性并行生成整个语音波形,实现了快速高效的语音合成。
ParallelWaveGAN的主要特点
ParallelWaveGAN具有以下几个突出的特点:
- 非自回归结构
ParallelWaveGAN采用了非自回归的生成器结构,可以并行生成整个语音波形。这大大提高了生成速度,使其能够实现实时语音合成。
- 多分辨率频谱图损失
除了GAN的对抗损失外,ParallelWaveGAN还引入了多分辨率频谱图损失。这有助于生成器学习不同时间尺度上的语音特征,提高合成语音的质量。
- 小型网络结构
相比传统的WaveNet模型,ParallelWaveGAN的网络结构更加轻量化。这降低了计算复杂度,使其可以在CPU上实现实时推理。
- 端到端训练
ParallelWaveGAN可以直接从频谱图到波形进行端到端训练,无需复杂的预处理和后处理步骤。这简化了训练流程,提高了模型的灵活性。
ParallelWaveGAN的应用
ParallelWaveGAN作为一种高效的神经声码器,在语音合成领域有着广泛的应用前景:
- 文本转语音(TTS)
ParallelWaveGAN可以作为TTS系统的声码器模块,将生成的声学特征转换为高质量的语音波形。它的快速推理速度使得TTS系统可以实现实时响应。
- 语音转换
在语音转换任务中,ParallelWaveGAN可以将源说话人的声学特征转换为目标说话人的语音波形,实现声音风格的转换。
- 语音增强
ParallelWaveGAN还可以应用于语音增强任务,如去噪、去混响等。通过训练模型学习从含噪语音到清晰语音的映射,可以实现语音质量的提升。
- 歌声合成
除了说话声音,ParallelWaveGAN也可以用于歌声合成。通过训练特定的歌声数据集,可以生成自然流畅的歌声。
ParallelWaveGAN的实现
ParallelWaveGAN已经有多个开源实现,其中比较知名的是GitHub上的kan-bayashi/ParallelWaveGAN项目。该项目提供了PyTorch版本的ParallelWaveGAN实现,包括模型训练、推理等完整功能。
以下是使用该项目训练ParallelWaveGAN模型的基本步骤:
-
准备数据集,包括音频文件和对应的梅尔频谱图。
-
配置模型参数,如网络结构、训练超参数等。
-
运行训练脚本,开始模型训练:
python train.py --config config.yml --train-dir data/train --dev-dir data/dev
- 训练完成后,使用训练好的模型进行推理:
python decode.py --checkpoint path/to/checkpoint --outdir outputs
该项目还提供了多个预训练模型,覆盖了不同语言和说话人的数据集。用户可以直接使用这些预训练模型进行语音合成。
ParallelWaveGAN的性能
ParallelWaveGAN在生成速度和音质方面都表现出色。根据原论文的实验结果:
- 生成速度
在NVIDIA Tesla V100 GPU上,ParallelWaveGAN可以达到28.68倍实时的生成速度。即1秒的音频只需要约35毫秒即可生成。
- 音质评分
在平均意见得分(MOS)测试中,ParallelWaveGAN的得分为4.06,接近真实语音的4.46分,优于其他多种神经声码器。
- 模型大小
ParallelWaveGAN的模型参数量约为1.44M,远小于WaveNet的5.9M,可以更好地适应资源受限的场景。
ParallelWaveGAN的发展与改进
自ParallelWaveGAN提出以来,研究人员对其进行了多方面的改进和扩展:
- Multi-band MelGAN
Multi-band MelGAN在ParallelWaveGAN的基础上引入了多频带处理,进一步提高了生成速度和音质。
- HiFi-GAN
HiFi-GAN改进了生成器和判别器的结构,在保持高音质的同时,进一步降低了计算复杂度。
- StyleMelGAN
StyleMelGAN引入了风格控制机制,可以更灵活地控制生成语音的风格特征。
这些改进使得ParallelWaveGAN系列模型在各种语音合成任务中表现越来越出色。
总结与展望
ParallelWaveGAN作为一种高效的神经声码器,在语音合成领域发挥着重要作用。它实现了高质量语音的快速生成,为实时语音交互系统提供了有力支持。未来,ParallelWaveGAN还有以下几个可能的发展方向:
-
进一步提高音质,缩小与真实语音的差距。
-
降低模型复杂度,使其能在更多设备上实现实时推理。
-
增强对多说话人、多语言的支持能力。
-
探索在更多语音处理任务中的应用。
随着深度学习技术的不断发展,我们有理由相信,ParallelWaveGAN及其改进版本将在语音合成和处理领域发挥越来越重要的作用,为人机语音交互带来更好的体验。










