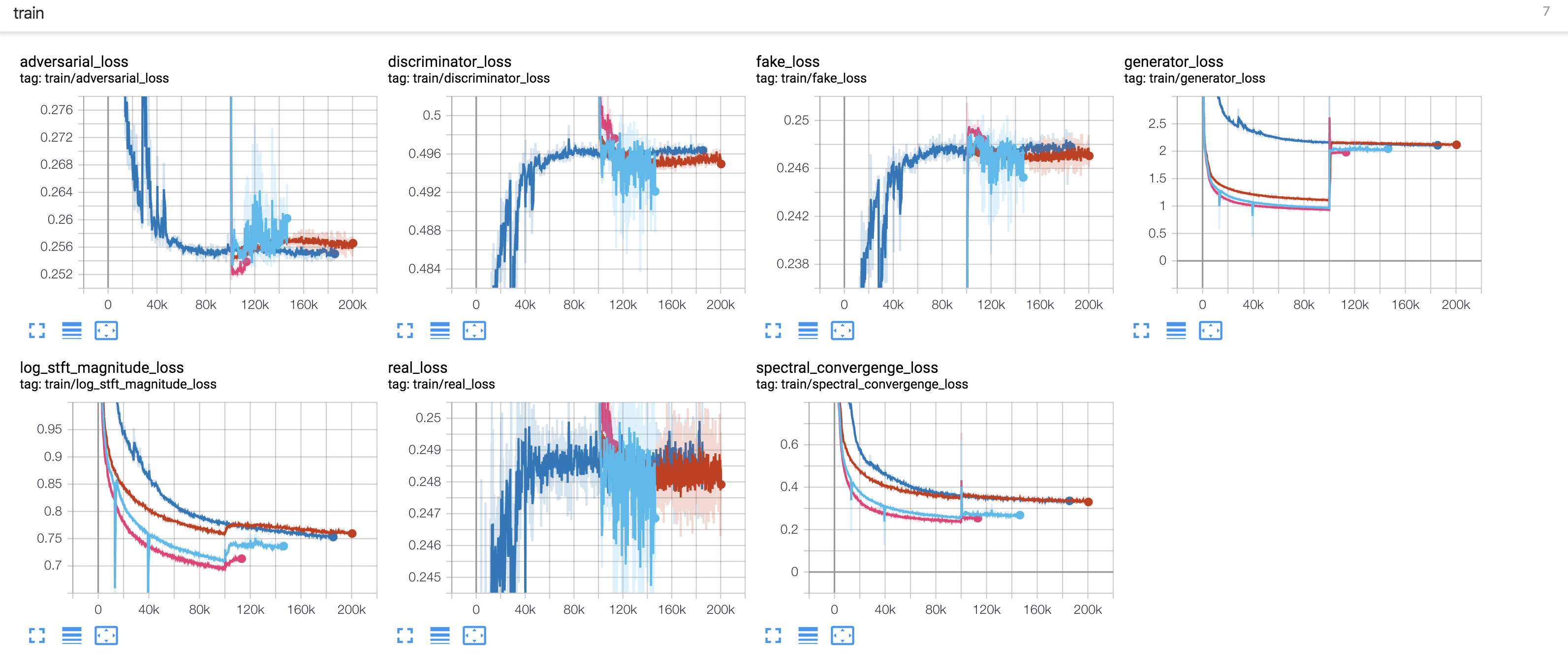
ParallelWaveGAN简介
ParallelWaveGAN是一种非自回归的神经网络声码器模型,由Yamamoto等人于2019年提出。它具有以下特点:
- 基于生成对抗网络(GAN)架构
- 非自回归设计,实现并行生成
- 同时优化多分辨率谱图和对抗损失
- 无需知识蒸馏,易于训练
- 参数量小(约1.44M),推理速度快(28.68倍实时)
- 生成语音质量高(MOS 4.16)
ParallelWaveGAN为实时神经声码器的发展做出了重要贡献,在语音合成领域得到广泛应用。
学习资源
1. 论文
这是ParallelWaveGAN的原始论文,详细介绍了模型的设计和实验结果。
2. 代码实现
这是ParallelWaveGAN的非官方PyTorch实现,包含了完整的训练和推理代码。
3. 预训练模型
可以在上述GitHub仓库的README中找到多个预训练模型的下载链接,包括不同语言和数据集上训练的版本。
4. 在线演示
这个Colab notebook提供了ParallelWaveGAN的实时端到端文本转语音演示。
5. 相关工作
这些是与ParallelWaveGAN相关的其他神经声码器模型,对比学习有助于更全面地理解这一领域。
使用指南
- 安装:
pip install parallel_wavegan
-
下载预训练模型
-
使用示例:
from parallel_wavegan import inference
model = inference.load_model("path/to/model.pkl")
wav = model.generate(mel)
更详细的使用说明请参考GitHub仓库的README文档。
ParallelWaveGAN为实现高质量实时语音合成提供了强大的解决方案。希望本文汇总的学习资料能够帮助读者快速入门并掌握这一技术。如有任何问题,欢迎在评论区讨论交流。