
PaSST:音频Transformer的高效训练方法
近年来,Transformer模型在计算机视觉和自然语言处理领域取得了巨大成功。然而,将Transformer应用于音频分类等任务仍面临着训练时间长、GPU内存需求大等挑战。为了解决这些问题,研究人员提出了一种名为PaSST (Patchout Audio Spectrogram Transformer)的新方法,通过创新的Patchout技术大幅提高了音频Transformer的训练效率和性能。
Patchout技术:PaSST的核心创新
PaSST的核心创新在于Patchout技术。在训练过程中,Patchout会随机丢弃部分输入音频频谱图的patch,包括:
- 非结构化Patchout:随机丢弃单个patch,类似于dropout。
- 结构化Patchout:丢弃整个时间帧或频率bin对应的patch,类似于SpecAugment。
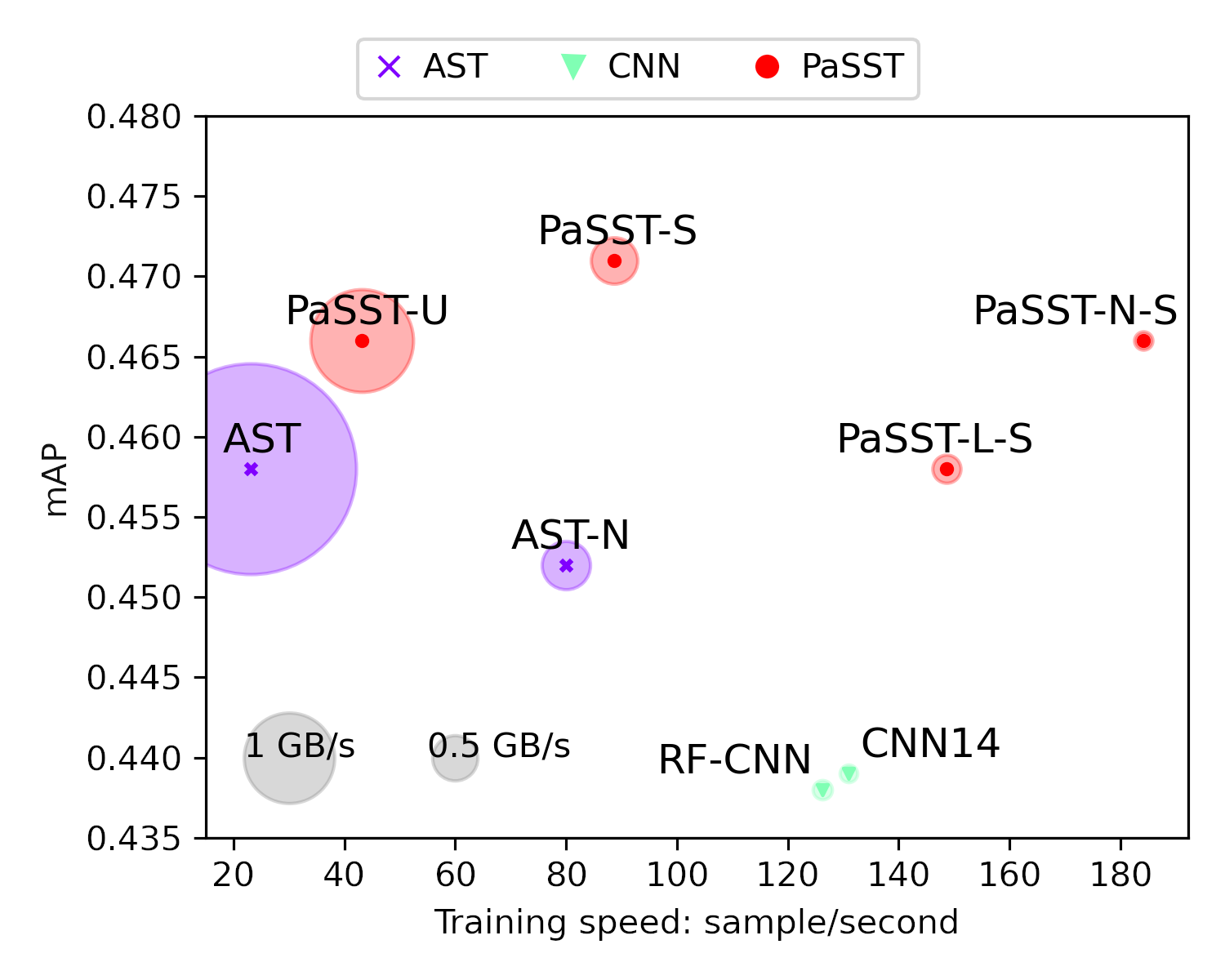
通过Patchout,PaSST显著减少了训练时间和GPU内存需求,同时提高了模型性能。下图直观展示了PaSST相比其他方法在训练速度和内存消耗上的优势:
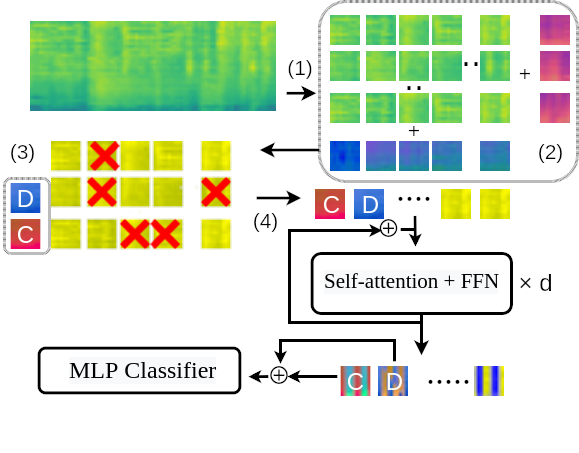
PaSST模型架构
PaSST的整体架构如下:
- 输入层:将原始音频波形转换为梅尔频谱图。
- Patch嵌入:将频谱图划分为多个patch并进行线性投影。
- Transformer编码器:使用多层自注意力机制对patch特征进行编码。
- 分类头:将编码后的特征映射到最终的类别预测。
在训练过程中,Patchout会作用于步骤2的patch嵌入层,随机丢弃部分patch信息。
PaSST的实现与使用
PaSST的官方实现基于PyTorch,并使用了PyTorch Lightning框架来简化训练流程。主要特点包括:
- 支持多种预训练模型,如passt_s_swa_p16_128_ap476等。
- 提供了在AudioSet等数据集上的预训练权重。
- 可以方便地进行微调和迁移学习。
以下是使用预训练PaSST模型的示例代码:
from models.passt import get_model
model = get_model(arch="passt_s_swa_p16_128_ap476",
pretrained=True,
n_classes=527,
in_channels=1,
fstride=10,
tstride=10,
input_fdim=128,
input_tdim=998,
u_patchout=0,
s_patchout_t=40,
s_patchout_f=4)
这将加载一个在AudioSet上预训练的PaSST模型,mAP为0.476。用户可以根据具体任务调整Patchout参数等配置。
PaSST在音频分类任务中的应用
PaSST在多个音频分类基准数据集上取得了优异成绩:
- AudioSet:达到0.4956 mAP,优于之前的最佳结果。
- ESC-50:准确率达到96.75%,接近人类水平。
- OpenMIC-2018:PR-AUC达到0.9325,显著超过其他方法。
- FSD50K:mAP达到0.601,创造新的最佳记录。
这些结果充分证明了PaSST在通用音频分类、环境声音分类、音乐乐器识别等任务中的强大性能。
PaSST的优势与局限性
PaSST的主要优势包括:
- 训练效率高:Patchout技术显著减少了训练时间和GPU内存需求。
- 性能优异:在多个音频分类任务中达到了最先进的水平。
- 灵活性强:支持多种预训练模型和微调策略。
但PaSST也存在一些局限性:
- 计算复杂度仍然较高,在资源受限的设备上部署可能存在挑战。
- 对于非频谱图表示的音频数据,如原始波形,可能需要额外的预处理。
结论与展望
PaSST为音频Transformer的高效训练提供了一种新的范式。通过创新的Patchout技术,PaSST不仅提高了训练效率,还在多个音频分类任务中取得了最先进的性能。未来,PaSST有望在更广泛的音频处理任务中发挥作用,如音频生成、音频增强等。同时,Patchout技术的思想也可能启发其他领域Transformer模型的改进。
研究人员和开发者可以通过GitHub上的PaSST官方仓库了解更多细节,并尝试在自己的项目中应用这一强大的音频处理工具。随着深度学习在音频领域的不断发展,像PaSST这样的创新方法将继续推动着音频人工智能技术的进步。









