
 Github
Github 论文
论文PaSST: 使用Patchout高效训练音频Transformer
这是使用Patchout高效训练音频Transformer的实现
Patchout显著减少了在音频频谱图上训练Transformer所需的训练时间和GPU内存需求,同时提高了它们的性能。

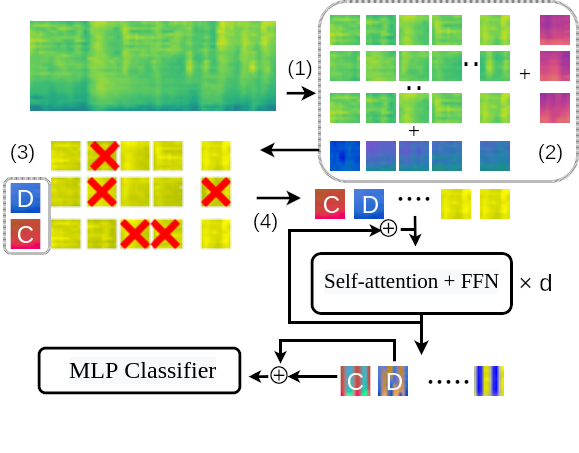
Patchout通过在训练过程中丢弃一些输入块来实现。 可以是非结构化方式(随机丢弃,类似于dropout), 也可以是提取的块的整个时间帧或频率bin(类似于SpecAugment), 这对应于下图步骤3中的行/列。
目录
用于推理和提取嵌入的预训练模型
如果你只想使用预训练模型生成的嵌入,使用自己的微调框架,或只需要进行推理,可以在这里找到该repo的精简版本。 该包遵循HEAR 2021 NeurIPS Challenge API,可以通过以下方式安装:
pip install hear21passt
这个repo是一个完整的框架,用于训练模型并在下游任务上微调Audioset的预训练模型。
从预训练模型获取logits
from hear21passt.base import get_basic_model,get_model_passt
import torch
# 获取PaSST模型包装器,包括Melspectrogram和默认预训练的transformer
model = get_basic_model(mode="logits")
print(model.mel) # 从原始波形中提取mel频谱图
print(model.net) # transformer网络
# 推理示例
model.eval()
model = model.cuda()
with torch.no_grad():
# audio_wave的形状为[batch, seconds*32000],采样率为32k
# 示例:batch=3,10秒的音频
audio = torch.ones((3, 32000 * 10))*0.5
audio_wave = audio.cuda()
logits=model(audio_wave)
获取用于微调的预训练模型
from hear21passt.base import get_basic_model,get_model_passt
import torch
# 获取PaSST模型包装器,包括Melspectrogram和默认预训练的transformer
model = get_basic_model(mode="logits")
print(model.mel) # 从原始波形中提取mel频谱图
# 可选:将transformer替换为具有所需类别数的transformer,例如50个类别
model.net = get_model_passt(arch="passt_s_swa_p16_128_ap476", n_classes=50)
print(model.net) # transformer网络
# 现在model包含mel + 预训练的transformer模型,可以进行微调
# 它仍然期望输入的形状为[batch, seconds*32000],采样率为32k
model.train()
model = model.cuda()
开发环境
如果你想使用与论文中相同的环境,可以按照以下说明进行操作。
设置开发实验环境
对于从头开始训练模型或使用与论文相同的设置进行微调:
- 如果需要,创建一个新的Python 3.8环境并激活它:
conda create -n passt python=3.8
conda activate passt
- 安装适合你系统的PyTorch版本。例如:
conda install pytorch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0 cudatoolkit=11.3 -c pytorch
- 安装requirements:
pip install -r requirements.txt
使用导出的conda环境进行设置
或者,你可以使用导出的conda环境environment.yml来创建环境。
建议使用Mamba进行设置,因为它比conda工作得更快:
conda install mamba -n base -c conda-forge
现在你可以从environment.yml导入环境
mamba env create -f environment.yml
现在你有了一个名为ba3l的环境。
检查环境
为了检查你的环境是否与我们在运行中使用的环境匹配,请查看environment.yml和pip_list.txt文件,这些文件是使用以下命令导出的:
conda env export --no-builds | grep -v "prefix" > environment.yml
pip list > pip_list.txt
入门
如果你想使用自己的设置,只使用这个repo中的模型,你可以如上所述用于推理和提取嵌入的预训练模型获取模型,从头开始训练或在自己的数据集上进行微调。本节的其余部分解释了如何使用这个repo来训练和微调模型。为此,首先需要按照上面的说明设置开发环境。
一般信息
该存储库使用sacred进行实验管理和配置,使用pytorch-lightning进行训练,使用wandb进行日志记录。
每个数据集都有一个主要的实验文件,如ex_audioset.py和ex_openmic.py,以及一个数据集文件夹。实验文件包含主要的训练和验证逻辑。数据集文件夹包含下载、预处理和加载数据集进行训练所需的特定代码。
通常,你可以通过以下命令获取实验文件的帮助信息,这将打印可用的命令和基本选项:
python ex_audioset.py help
配置实验
每个实验都有一组默认的配置选项,定义在实验文件中,例如ex_audioset.py。你可以使用sacred语法覆盖任何配置。你可以使用print_config命令打印配置值,而不训练模型:
python ex_audioset.py print_config
然后你可以使用命令行界面覆盖任何配置选项(sacred语法),使用with,例如:
python ex_audioset.py with trainer.precision=16
这将使用16位精度在Audioset上进行训练。
整体配置如下所示:
...
seed = 542198583 # 此实验的随机种子
slurm_job_id = ''
speed_test_batch_size = 100
swa = True
swa_epoch_start = 50
swa_freq = 5
use_mixup = True
warm_up_len = 5
weight_decay = 0.0001
basedataset:
base_dir = 'audioset_hdf5s/' # 数据集的基础目录,更改它或创建一个链接
eval_hdf5 = 'audioset_hdf5s/mp3/eval_segments_mp3.hdf'
wavmix = 1
....
roll_conf:
axis = 1
shift = None
shift_range = 50
datasets:
test:
batch_size = 20
dataset = {CMD!}'/basedataset.get_test_set'
num_workers = 16
validate = True
training:
batch_size = 12
dataset = {CMD!}'/basedataset.get_full_training_set'
num_workers = 16
sampler = {CMD!}'/basedataset.get_ft_weighted_sampler'
shuffle = None
train = True
models:
mel:
freqm = 48
timem = 192
hopsize = 320
htk = False
n_fft = 1024
n_mels = 128
norm = 1
sr = 32000
...
net:
arch = 'passt_s_swa_p16_128_ap476'
fstride = 10
in_channels = 1
input_fdim = 128
input_tdim = 998
n_classes = 527
s_patchout_f = 4
s_patchout_t = 40
tstride = 10
u_patchout = 0
...
trainer:
accelerator = None
accumulate_grad_batches = 1
amp_backend = 'native'
amp_level = 'O2'
auto_lr_find = False
auto_scale_batch_size = False
...
有很多内容可以从命令行更新。 简而言之:
trainer下的所有配置选项都是pytorch lightning训练器的api。例如,要关闭cuda基准测试,在命令行中添加trainer.benchmark=False。wandb是wandb配置。例如,要更改wandb项目,在命令行中添加wandb.project="test_project"。models.net是PaSST(或选择的神经网络)的选项。例如:models.net.u_patchout、models.net.s_patchout_f、models.net.s_patchout_t控制非结构化patchout和在频率和时间上的结构化patchout。input_fdim和input_tdim是输入频谱图在频率和时间上的维度。models.net.fstride和models.net.tstride是输入patches在频率和时间上的步幅,将这些设置为16意味着没有patch重叠。models.mel是预处理选项(梅尔频谱图)。mel.sr是采样率,mel.hopsize是STFT窗口的跳跃大小,mel.n_mels是梅尔滤波器组的数量,mel.freqm和mel.timem是spec-augment的频率和时间掩蔽参数。
在config_updates.py中有许多预定义的配置包(称为named_configs)。这些包括不同的模型、设置等...
你可以使用以下命令列出这些配置:
python ex_audioset.py print_named_configs
例如,passt_s_20sec是一个配置包,它将模型设置为在Audioset上预训练的PaSST-S,并接受最长20秒的片段。
在Audioset上训练
按照audioset页面中的说明下载和准备数据集。
例如,可以这样训练基础PaSST模型:
python ex_audioset.py with trainer.precision=16 models.net.arch=passt_deit_bd_p16_384 -p
例如,仅使用400的非结构化patchout:
python ex_audioset.py with trainer.precision=16 models.net.arch=passt_deit_bd_p16_384 models.net.u_patchout=400 models.net.s_patchout_f=0 models.net.s_patchout_t=0 -p
通过设置环境变量DDP可以启用多GPU训练,例如使用2个GPU:
DDP=2 python ex_audioset.py with trainer.precision=16 models.net.arch=passt_deit_bd_p16_384 -p -c "PaSST base 2 GPU"
预训练模型示例
请查看发布页面以下载预训练模型。 通常,你可以获取在Audioset上预训练的模型
from models.passt import get_model
model = get_model(arch="passt_s_swa_p16_128_ap476", pretrained=True, n_classes=527, in_channels=1,
fstride=10, tstride=10,input_fdim=128, input_tdim=998,
u_patchout=0, s_patchout_t=40, s_patchout_f=4)
这将自动下载在 Audioset 上预训练的 PaSST 模型,其 mAP 为 0.476。该模型使用 s_patchout_t=40, s_patchout_f=4 进行训练,但你可以根据你的任务或计算需求来调整这些参数。
有几个可用的预训练模型,它们具有不同的步长(重叠)并且使用/不使用 SWA:passt_s_p16_s16_128_ap468, passt_s_swa_p16_s16_128_ap473, passt_s_swa_p16_s14_128_ap471, passt_s_p16_s14_128_ap469, passt_s_swa_p16_s12_128_ap473, passt_s_p16_s12_128_ap470。
例如,在 passt_s_swa_p16_s16_128_ap473 中:p16 表示补丁大小为 16x16,s16 表示无重叠(步长=16),128 个梅尔频带,ap473 指的是该模型在 Audioset 上的性能 mAP=0.479。
通常,你可以使用以下方式获取预训练模型:
from models.passt import get_model
passt = get_model(arch="passt_s_swa_p16_s16_128_ap473", fstride=16, tstride=16)
使用该框架,你可以通过以下方式评估此模型:
python ex_audioset.py evaluate_only with trainer.precision=16 passt_s_swa_p16_s16_128_ap473 -p
这些模型的集成也已提供:
一个大型集成模型,其 mAP=.4956
python ex_audioset.py evaluate_only with trainer.precision=16 ensemble_many
一个由 stride=14 和 stride=16 的两个模型组成的集成,其 mAP=.4858
python ex_audioset.py evaluate_only with trainer.precision=16 ensemble_s16_14
还有其他集成模型 ensemble_4,ensemble_5
在下游数据集上微调的示例
- [ESC-50:环境声音分类数据集](https://github.com/kkoutini/PaSST/blob/main/esc50/
- [OpenMIC-2018 数据集](https://github.com/kkoutini/PaSST/blob/main/openmic/
- [FSD50K](https://github.com/kkoutini/PaSST/blob/main/fsd50k/
引用
引用 Interspeech 2022 接受的论文:
@inproceedings{koutini22passt,
author = {Khaled Koutini and
Jan Schl{\"{u}}ter and
Hamid Eghbal{-}zadeh and
Gerhard Widmer},
title = {Efficient Training of Audio Transformers with Patchout},
booktitle = {Interspeech 2022, 23rd Annual Conference of the International Speech
Communication Association, Incheon, Korea, 18-22 September 2022},
pages = {2753--2757},
publisher = {{ISCA}},
year = {2022},
url = {https://doi.org/10.21437/Interspeech.2022-227},
doi = {10.21437/Interspeech.2022-227},
}
联系方式
该仓库将会更新,同时如果你有任何问题或遇到任何问题,请随时在 GitHub 上开启一个 issue,或直接联系作者。











