
PDF-Extract-Kit:突破PDF内容提取的壁垒
在当今信息爆炸的时代,PDF(便携式文档格式)作为一种通用的文档格式,承载着海量的知识和信息。然而,从PDF中精确提取高质量内容一直是一个具有挑战性的任务。为了解决这一问题,OpenDataLab团队开发了PDF-Extract-Kit,这是一个旨在实现高质量PDF内容提取的综合性工具包。
全面的功能模块
PDF-Extract-Kit通过将PDF内容提取任务分解为多个关键组件,实现了对PDF文档的深度解析:
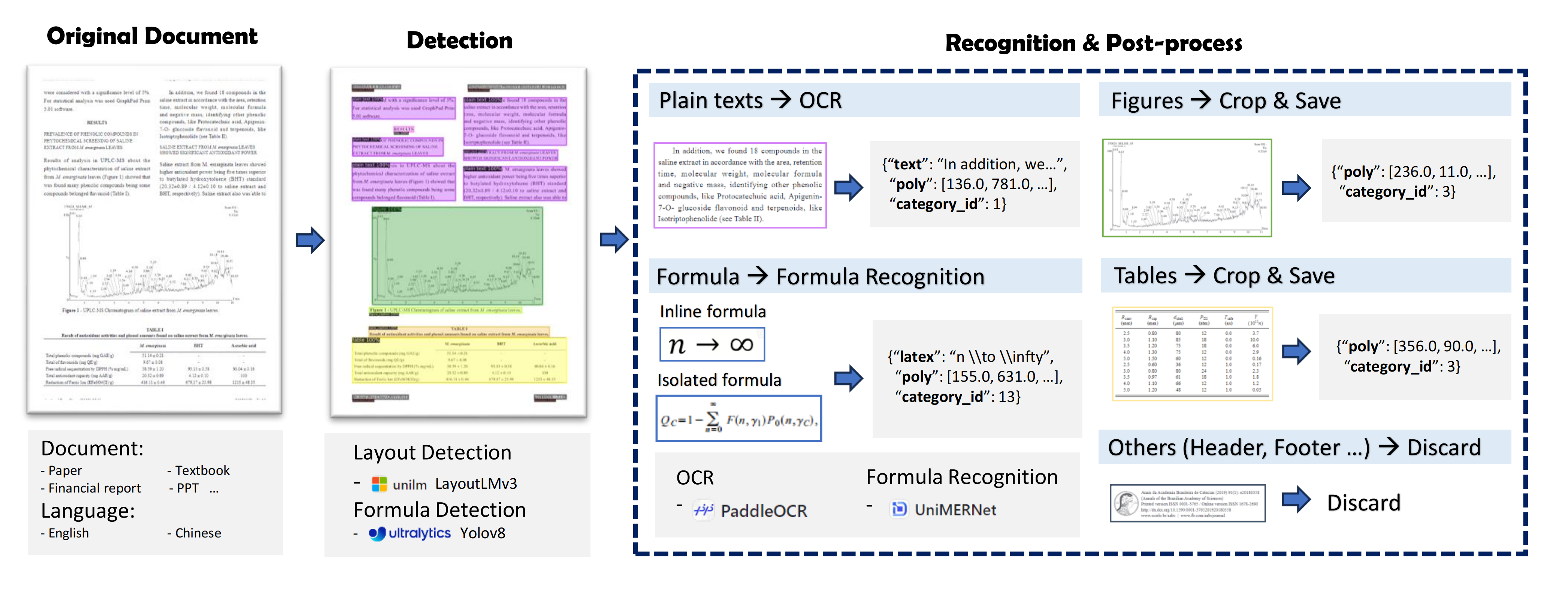
- 版面检测: 利用LayoutLMv3模型进行区域检测,包括图像、表格、标题、正文等。
- 公式检测: 采用YOLOv8模型检测行内公式和独立公式。
- 公式识别: 使用UniMERNet模型进行公式识别。
- 表格识别: 应用StructEqTable模型进行表格识别。
- 光学字符识别(OCR): 使用PaddleOCR进行文本识别。
这种模块化的设计使得PDF-Extract-Kit能够应对各种复杂的PDF文档,从学术论文到教科书,从研究报告到财务报表,都能实现准确的内容提取。
突破性的技术创新
PDF-Extract-Kit的突出特点在于其对多样化文档类型的适应能力。传统的开源模型往往仅在arXiv论文数据上训练,面对多样化的PDF文档时表现不佳。而PDF-Extract-Kit团队通过收集多样化数据进行标注和训练,成功实现了对各种类型文档的精确检测。
在版面检测方面,PDF-Extract-Kit与现有的开源版面检测模型(如DocXchain、Surya和360LayoutAnalysis)相比,在学术论文和教科书验证集上都展现出显著优势。例如,在学术论文验证集上,PDF-Extract-Kit的mAP达到77.6,远超其他模型。
公式检测方面,与开源公式检测模型Pix2Text-MFD相比,PDF-Extract-Kit在学术论文和多源验证集上均表现出色。在学术论文验证集上,PDF-Extract-Kit的AP50和AR50分别达到87.7和89.9,大幅领先于Pix2Text-MFD。
公式识别采用的UniMERNet方法在各类公式上的识别质量与商业软件相媲美。OCR部分使用的PaddleOCR在中英文识别上都表现出色。
强大的适应性和鲁棒性
PDF-Extract-Kit的一大亮点是其对复杂文档的处理能力。通过对各种PDF文档进行标注,团队训练出了具有强大鲁棒性的版面检测和公式检测模型。即使面对扫描模糊或带有水印的文档,PDF-Extract-Kit仍能保持高精度的提取效果。

这种强大的适应性使得PDF-Extract-Kit能够广泛应用于各种场景:
- 研究人员可以利用它从学术论文中提取数据和图表。
- 学生可以从教科书中提取关键公式和概念,辅助学习。
- 数据分析师可以从财务报告中提取关键数据进行分析。
易用性和灵活性
PDF-Extract-Kit不仅功能强大,还注重用户友好性。它提供了详细的安装指南和运行说明,支持在Windows、macOS等多种操作系统上运行,甚至可以在Google Colab上体验。
运行提取脚本时,用户可以灵活设置多个参数:
--pdf: 指定要处理的PDF文件或文件夹。--output: 设置结果保存路径。--vis: 选择是否可视化检测结果。--render: 决定是否渲染识别结果。--batch-size: 设置数据加载器的批量大小。
这些选项让用户能够根据自己的需求和硬件条件调整提取过程。
开源与社区协作
PDF-Extract-Kit采用Apache-2.0许可证,体现了团队对开源精神的坚持。项目欢迎社区成员提出具体而有价值的需求,共同参与到PDF-Extract-Kit工具的持续改进中,推动科学研究和产业发展。
未来,PDF-Extract-Kit团队计划进一步扩展工具的功能:
- 开发将表格图像转换为LaTeX/Markdown格式源代码的功能。
- 实现化学方程式的自动检测。
- 开发识别和解析化学方程式和图表的模型。
- 构建确定文档中文本正确阅读顺序的模型。
结语
PDF-Extract-Kit作为一个全面的PDF内容提取工具包,通过其强大的功能、卓越的性能和灵活的设计,为解决PDF内容提取这一长期存在的技术难题提供了一个优秀的解决方案。它不仅能满足学术研究、教育学习、数据分析等多个领域的需求,还为未来的智能文档处理技术发展指明了方向。
随着人工智能和机器学习技术的不断进步,我们有理由相信,PDF-Extract-Kit将继续evolve,为用户提供更加智能、高效的PDF内容提取体验,助力知识的传播与创新。









