
 Github
Github Huggingface
Huggingface
 ModelScope)]
ModelScope)]概述
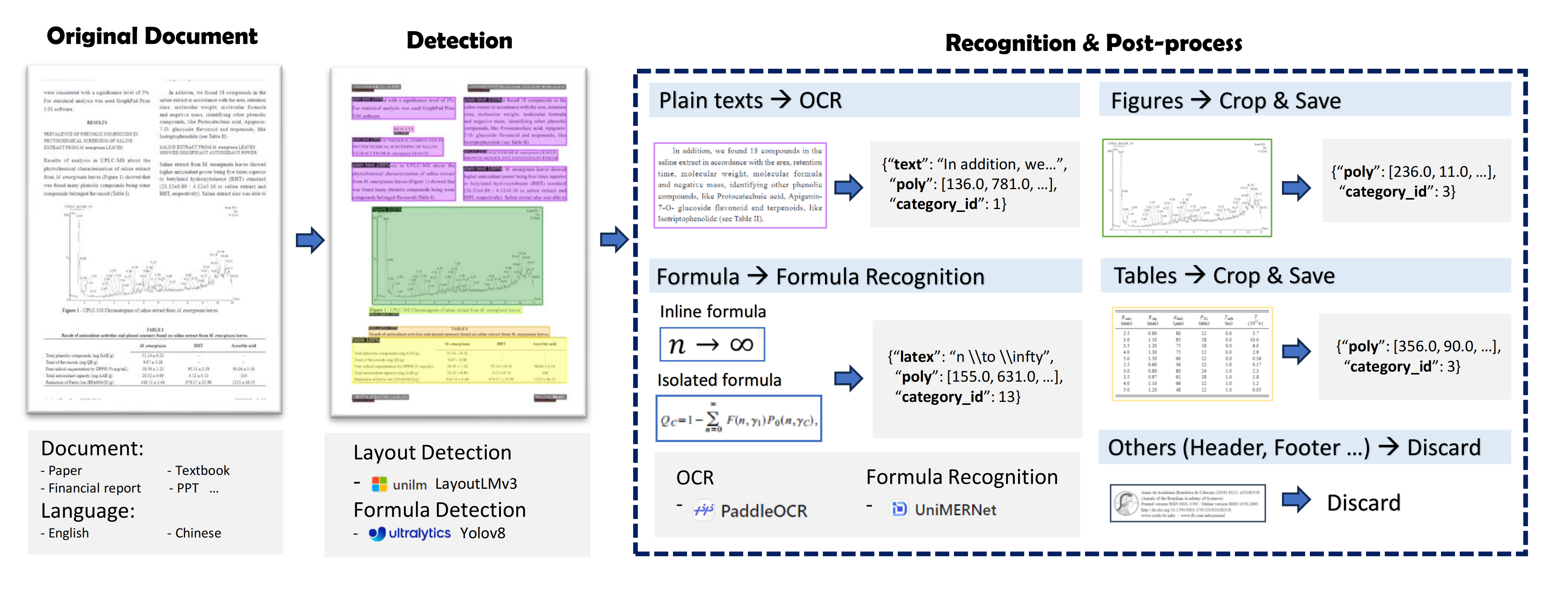
PDF文档包含丰富的知识,但从PDF中提取高质量内容并非易事。为解决这个问题,我们将PDF内容提取任务分解为以下几个组件:
- 版面检测:使用LayoutLMv3模型进行区域检测,如
图像、表格、标题、文本等; - 公式检测:使用YOLOv8检测公式,包括
行内公式和独立公式; - 公式识别:使用UniMERNet进行公式识别;
- 表格识别:使用StructEqTable进行表格识别;
- 光学字符识别:使用PaddleOCR进行文本识别;
注意: 由于文档类型的多样性,现有开源的版面和公式检测模型在处理多样化PDF文档时表现不佳。因此,我们收集了多样化数据进行标注和训练,以在各种类型的文档上实现精确的检测效果。详情请参阅版面检测和公式检测部分。对于公式识别,UniMERNet方法在各种类型的公式上的质量与商业软件相当。对于OCR,我们使用PaddleOCR,它在中英文识别方面表现良好。
PDF内容提取框架如下图所示:
PDF-Extract-Kit 输出格式
{
"layout_dets": [ # 页面上的元素
{
"category_id": 0, # 类别ID,0~9,13~15
"poly": [
136.0, # 坐标为图像格式,需要转回PDF坐标,顺序为左上、右上、右下、左下x,y坐标
781.0,
340.0,
781.0,
340.0,
806.0,
136.0,
806.0
],
"score": 0.69, # 置信度得分
"latex": '' # 公式识别结果,只有13、14类别有内容,其他为空,另外15为OCR结果,此键将被text替代
},
...
],
"page_info": { # 页面信息:提取边界框时的分辨率大小,如果涉及缩放可根据此信息对齐
"page_no": 0, # 页码
"height": 1684, # 页面高度
"width": 1200 # 页面宽度
}
}
category_id包含的类型如下:
{0: '标题', # 标题
1: '普通文本', # 文本
2: '舍弃', # 包括页眉、页脚、页码和页面注释
3: '图片', # 图像
4: '图片说明', # 图像说明
5: '表格', # 表格
6: '表格说明', # 表格说明
7: '表格脚注', # 表格脚注
8: '独立公式', # 显示公式(这是版面显示公式,优先级低于14)
9: '公式说明', # 显示公式标签
13: '行内公式', # 行内公式
14: '独立公式', # 显示公式
15: 'OCR文本'} # OCR结果
新闻与更新
2024.08.01🎉🎉🎉 增加了StructEqTable模块用于表格内容提取。欢迎使用!2024.07.01🎉🎉🎉 我们发布了PDF-Extract-Kit,这是一个用于高质量PDF内容提取的综合工具包,包括版面检测、公式检测、公式识别和OCR。
结果可视化
通过对各种PDF文档进行标注,我们训练了稳健的版面检测和公式检测模型。我们的流程在学术论文、教科书、研究报告和财务报表等多种类型的PDF文档上实现了准确的提取结果,即使在扫描模糊或有水印的情况下也表现出高度的稳健性。

评估指标
现有的开源模型通常在Arxiv论文数据上训练,在面对多样化的PDF文档时表现不佳。相比之下,我们的模型经过多样化数据训练,能够适应各种文档类型进行提取。
验证过程的介绍可以在这里查看。
版面检测
我们将我们的模型与现有的开源版面检测模型进行了比较,包括DocXchain、Surya和360LayoutAnalysis的两个模型。表中的LayoutLMv3-SFT模型指的是我们在LayoutLMv3-base-chinese预训练模型基础上使用我们的SFT数据进一步训练得到的检查点。学术论文验证集由402页组成,而教科书验证集由来自各种教科书的587页组成。
| 模型 | 学术论文验证集 | 教科书验证集 | ||||
|---|---|---|---|---|---|---|
| mAP | AP50 | AR50 | mAP | AP50 | AR50 | |
| DocXchain | 52.8 | 69.5 | 77.3 | 34.9 | 50.1 | 63.5 |
| Surya | 24.2 | 39.4 | 66.1 | 13.9 | 23.3 | 49.9 |
| 360LayoutAnalysis-Paper | 37.7 | 53.6 | 59.8 | 20.7 | 31.3 | 43.6 |
| 360LayoutAnalysis-Report | 35.1 | 46.9 | 55.9 | 25.4 | 33.7 | 45.1 |
| LayoutLMv3-SFT | 77.6 | 93.3 | 95.5 | 67.9 | 82.7 | 87.9 |
公式检测
我们将我们的模型与开源公式检测模型Pix2Text-MFD进行了比较。此外,YOLOv8-Trained是我们在YOLOv8l模型基础上进行训练后得到的权重。论文验证集由255页学术论文组成,多源验证集由789页来自各种来源的页面组成,包括教科书和书籍。
| 模型 | 学术论文验证集 | 多源验证集 | ||
|---|---|---|---|---|
| AP50 | AR50 | AP50 | AR50 | |
| Pix2Text-MFD | 60.1 | 64.6 | 58.9 | 62.8 |
| YOLOv8-Trained | 87.7 | 89.9 | 82.4 | 87.3 |
公式识别
我们使用的公式识别基于从UniMERNet下载的权重,没有进行任何进一步的SFT训练,准确性验证结果可以在其GitHub页面上获得。
表格识别
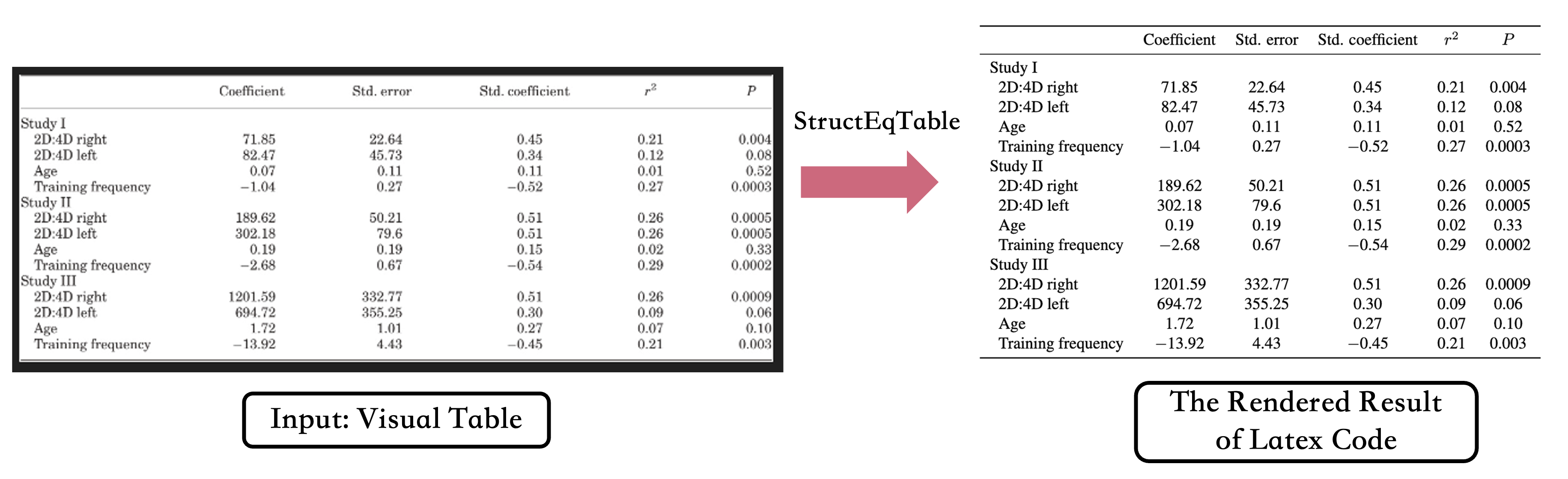
我们使用的表格识别基于从StructEqTable下载的权重,这是一个将表格图像转换为LaTeX的解决方案。与PP-StructureV2的表格识别能力相比,StructEqTable展示了更强的识别性能,即使对于复杂的表格也能提供良好的结果,这可能目前最适合研究论文中的数据。在速度方面还有很大的改进空间,我们正在不断迭代和优化。一周内,我们将更新表格识别能力为MinerU。
安装指南
conda create -n pipeline python=3.10
pip install -r requirements.txt
pip install --extra-index-url https://miropsota.github.io/torch_packages_builder detectron2==0.6+pt2.3.1cu121
安装后,您可能会遇到一些版本冲突导致的版本变更。如果遇到与版本相关的错误,可以尝试以下命令重新安装特定版本的库。
pip install pillow==8.4.0
除了版本冲突外,您可能还会遇到无法调用torch的错误。首先卸载以下库,然后重新安装cuda12和cudnn。
pip uninstall nvidia-cusparse-cu12
参考模型下载下载所需的模型权重。
在Windows上运行
如果您打算在Windows上运行此项目,请参考在Windows上使用PDF-Extract-Kit。
在macOS上运行
如果您打算在macOS上运行此项目,请参考在macOS上使用PDF-Extract-Kit。
在Google Colab上运行
如果您打算在Google Colab上体验此项目,请
运行提取脚本
python pdf_extract.py --pdf data/pdfs/ocr_1.pdf
参数说明:
--pdf:要处理的PDF文件;如果传入文件夹,则处理文件夹中的所有PDF文件。--output:结果保存路径,默认为"output"。--vis:是否可视化结果;如果是,将可视化检测结果,包括边界框和类别。--render:是否渲染识别结果,包括公式的LaTeX代码和纯文本,这些将被渲染并放置在检测框中。注意:这个过程非常耗时,并且还需要提前安装xelatex和imagemagic。
本项目致力于使用模型从多样性文档中提取高质量内容。它不涉及将提取的内容重新组合成新文档,如将PDF转换为Markdown。对于这些需求,请参考我们的另一个GitHub项目:MinerU
TODO 列表
- 表格解析:开发将表格图像转换为相应LaTeX/Markdown格式源代码的功能。
- 化学方程式检测:实现自动检测化学方程式。
- 化学方程式/图解识别:开发识别和解析化学方程式和图解的模型。
- 阅读顺序排序模型:构建一个模型来确定文档中文本的正确阅读顺序。
PDF-Extract-Kit旨在提供高质量的PDF提取能力。我们鼓励社区提出具体而有价值的需求,并欢迎大家参与持续改进PDF-Extract-Kit工具,以推动科研和产业发展。
许可证
本仓库使用Apache-2.0许可证。
请遵循相应模型的许可证使用相应的模型权重:LayoutLMv3 / UniMERNet / StructEqTable / YOLOv8 / PaddleOCR。
致谢
- LayoutLMv3:布局检测模型
- UniMERNet:公式识别模型
- StructEqTable:表格识别模型
- YOLOv8:公式检测模型
- PaddleOCR:OCR模型
引用
如果您在研究中发现我们的模型/代码/论文有用,请考虑给予⭐和引用📝,谢谢 :)
@misc{wang2024unimernet,
title={UniMERNet: A Universal Network for Real-World Mathematical Expression Recognition},
author={Bin Wang and Zhuangcheng Gu and Chao Xu and Bo Zhang and Botian Shi and Conghui He},
year={2024},
eprint={2404.15254},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@article{he2024opendatalab,
title={Opendatalab: Empowering general artificial intelligence with open datasets},
author={He, Conghui and Li, Wei and Jin, Zhenjiang and Xu, Chao and Wang, Bin and Lin, Dahua},
journal={arXiv preprint arXiv:2407.13773},
year={2024}
}











