
PortaSpeech:便携高质量的生成式文本转语音模型
近年来,文本转语音(Text-to-Speech, TTS)技术取得了长足的进步。然而,如何在保证语音质量的同时,实现模型的轻量化和便携性,仍然是一个挑战。最近,来自浙江大学的研究人员提出了一种名为PortaSpeech的新型TTS模型,旨在解决这一问题。
PortaSpeech的模型架构
PortaSpeech的核心思想是结合变分自编码器(VAE)和流模型(Flow)的优点。具体来说,PortaSpeech包含以下几个主要模块:
-
语言编码器(Linguistic Encoder):负责提取文本的语言学特征。
-
变分生成器(Variational Generator):基于VAE,用于生成初步的mel频谱图。
-
流后处理网络(Flow PostNet):基于流模型,进一步优化mel频谱图的细节。
-
声码器(Vocoder):将mel频谱图转换为波形音频。
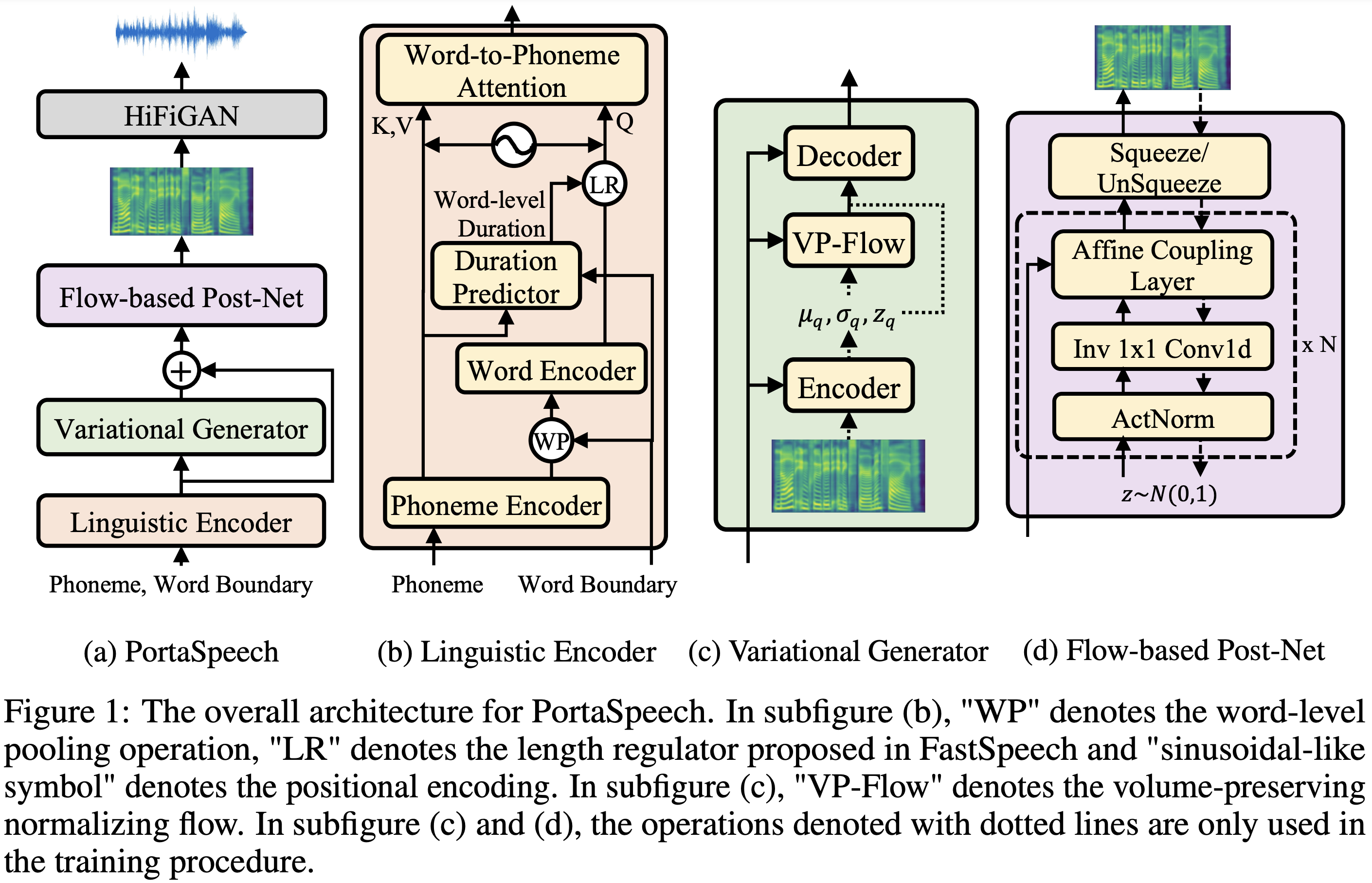
这种设计充分利用了VAE在捕捉长程语义特征(如韵律)方面的优势,以及流模型在重建频率细节方面的优势。通过这种组合,PortaSpeech能够生成既自然流畅又富有表现力的语音。
模型特点
-
轻量级设计:通过在流后处理网络中引入分组参数共享机制,PortaSpeech大大减少了模型参数量。标准版本的参数量为24M,小型版本仅为7.6M。
-
混合对齐机制:语言编码器采用了结合硬性词间对齐和软性词内对齐的混合对齐机制,有助于提取更准确的词级语义信息。
-
可控性:支持通过调整持续时间比例来控制合成语音的说话速度。
-
非自回归生成:采用非自回归方式生成mel频谱图,提高了推理速度。
训练与使用
PortaSpeech的训练过程相对简单:
-
数据预处理:使用Montreal Forced Aligner(MFA)工具进行强制对齐,获取文本和音素序列之间的对应关系。
-
模型训练:运行
train.py脚本,指定数据集名称即可开始训练。 -
语音合成:使用
synthesize.py脚本可以进行单句或批量语音合成。
# 单句合成
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
# 批量合成
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
实验结果
研究人员在LJSpeech数据集上进行了实验。结果表明,PortaSpeech在主观听感评分(MOS)上达到4.15分,与当前最先进的TTS模型相当。同时,小型版本的PortaSpeech(7.6M参数)仅比标准版本(24M参数)的MOS分数低0.05,展现了出色的参数效率。

进一步优化
尽管PortaSpeech已经取得了不错的效果,研究人员指出仍有一些可以改进的方向:
-
词音素对齐:目前使用的对角引导注意力(DGA)损失和CTC损失在对齐准确性和音频质量之间存在权衡。未来可以探索更好的对齐方法。
-
多说话人支持:当前版本仅支持单说话人TTS,未来将扩展到多说话人场景。
-
声码器选择:目前支持HiFi-GAN和MelGAN两种声码器,可以尝试集成更多高质量的声码器。
结论
PortaSpeech为轻量级高质量TTS模型提供了一个新的范式。通过巧妙结合VAE和流模型的优势,以及采用一系列优化技巧,PortaSpeech在保证语音质量的同时,大大减少了模型参数量,提高了模型的便携性和实用性。这对于在移动设备或边缘设备上部署TTS系统具有重要意义。
未来,随着进一步的优化和扩展,PortaSpeech有望在更多场景中发挥作用,推动TTS技术向更轻量、更高质量的方向发展。研究人员也鼓励社区基于开源代码进行进一步的探索和改进,共同推动TTS技术的进步。
🔗 项目地址: https://github.com/keonlee9420/PortaSpeech
📄 论文链接: PortaSpeech: Portable and High-Quality Generative Text-to-Speech












