
Prompt-Can-Anything:让AI实现无限可能
在人工智能快速发展的今天,各种强大的AI模型层出不穷。如何将这些先进的AI能力整合起来,为用户提供一个功能丰富、易于使用的AI应用平台,成为了一个重要的研究方向。Prompt-Can-Anything项目正是为此而生,它旨在通过简单的提示和一键操作,让用户轻松实现各种复杂的AI任务。
项目概述
Prompt-Can-Anything是一个结合了最先进AI应用的Gradio库和研究仓库。该项目的核心理念是"通过提示和SOTA模型的创造力,你可以做任何事情"。它整合了多种多模态AI模型,包括计算机视觉、自然语言处理、语音识别等领域的前沿技术,为用户提供了一个功能丰富的AI应用平台。
项目的主要动机是积累"Anything"AI智能代理后端,用于工程和研究。这需要使用更多的多模态任务和零样本模型,不仅提供多模态AI处理Web UI,还要逐步丰富其功能。最终目标是打造一个完整的智能代理,可以调用任何AI任务。
主要特性
Prompt-Can-Anything具有以下几个主要特性:
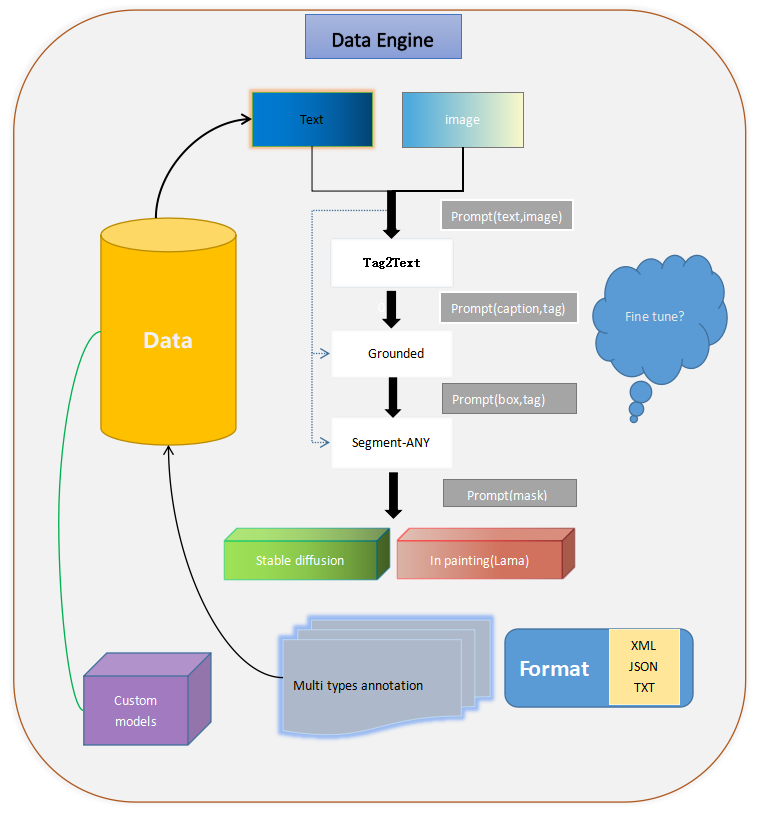
- 数据引擎(YOCO)
YOCO不仅仅是一个可以提示任何内容的工具。它依赖于集成的多模态模型和辅助生成器(如ChatGPT)来完成"数据引擎"。通过有效的全自动标注和稳定扩散系列方法,YOCO可以生成和控制满足要求的数据,并生成便于训练常规模型的自定义标签格式。
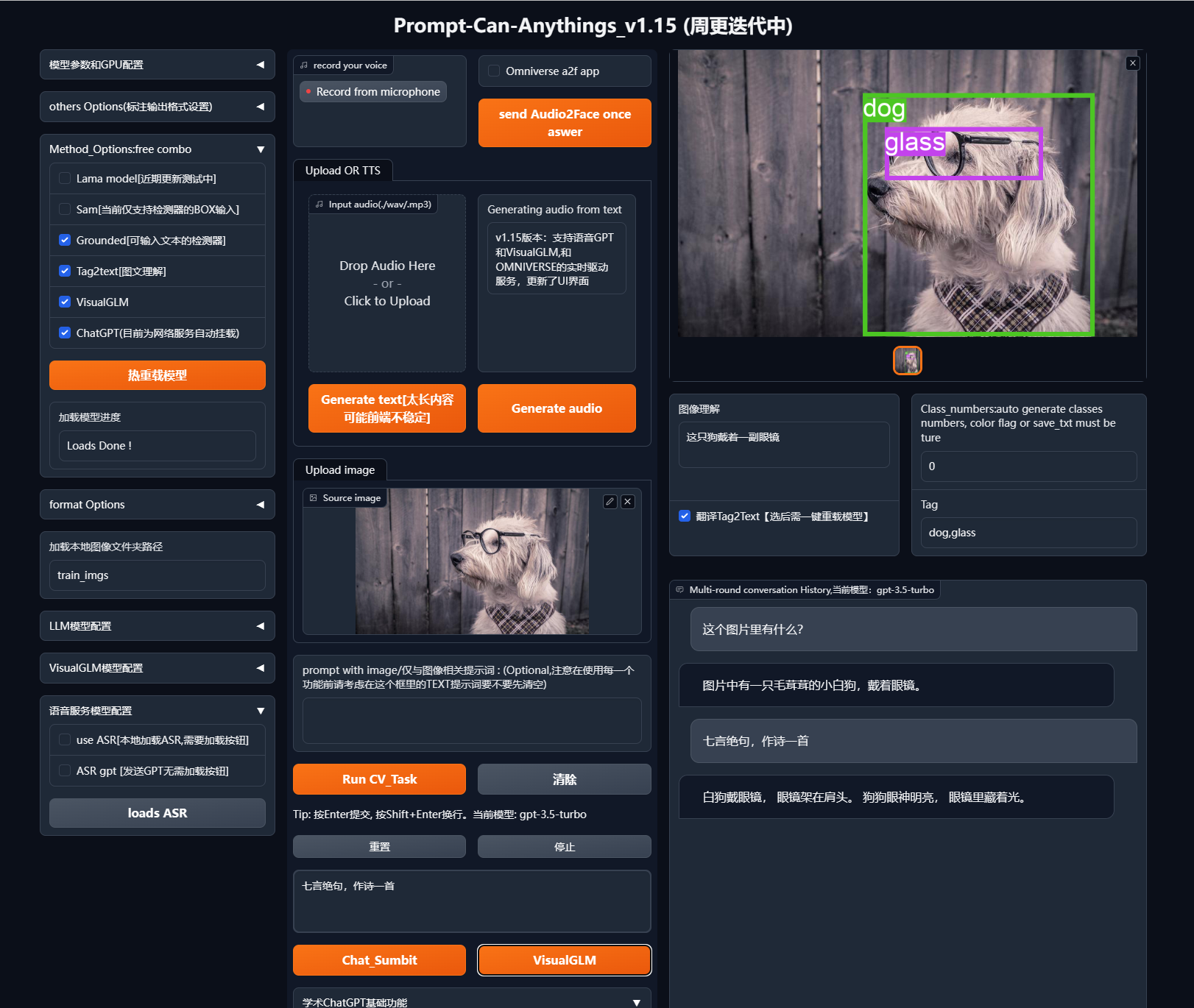
- 交互式内容创作和视觉GPT
该项目集成了多种GPT模型,主要使用ChatGPT的接口,并使用开源的清华VISUALGLM进行部署和微调本地化GPT。通过多模态应用工具,用户可以进行对话和内容创作。
- 3D和2D虚拟形象(即将推出)
项目计划通过3D引擎结合多模态任务(如GPT)完成角色设计交互。同时,还将通过Sadtalker开源项目和GPT等多模态任务完成2D角色设计交互。
- 无限潜力的"Anything"
通过不断的创新和积累,项目将继续集成和学习最先进的AI技术。开发者将记录每个集成的模型,并在文章中提供详细的解释和总结。
技术细节
Prompt-Can-Anything项目整合了多个先进的AI模型和技术,包括但不限于:
- VisualGLM-6B: 视觉ChatGLM(6B参数)
- Segment Anything: 强大的分割模型
- Grounding DINO: 高质量零样本检测器
- Stable-Diffusion: 强大的文本到图像扩散模型
- Tag2text: 高效可控的视觉语言模型
- SadTalker: 用于生成逼真的3D运动系数的模型
- LAMA: 用于大规模图像修复的模型
这些模型和技术的结合,使得Prompt-Can-Anything能够处理各种复杂的多模态AI任务。
使用指南
要开始使用Prompt-Can-Anything,用户需要按照以下步骤操作:
- 克隆项目仓库:
git clone https://github.com/positive666/Prompt-Can-Anything
cd Prompt-Can-Anything
- 安装基本环境:
pip install -r requirements.txt
- 安装Ground检测器(需编译):
cd model_cards
pip install -e .
- 下载模型权重
用户需要下载各个模型的权重文件,并将路径配置在config_private.py文件中。
- 运行Web UI demo
python gradio_demo.py
应用示例
Prompt-Can-Anything支持多种AI任务,包括图像理解、目标检测、实例分割等。以下是一些应用示例:
- 自动标注
用户可以通过提供图像和提示,让系统自动完成目标检测、分割和文本标注等任务。

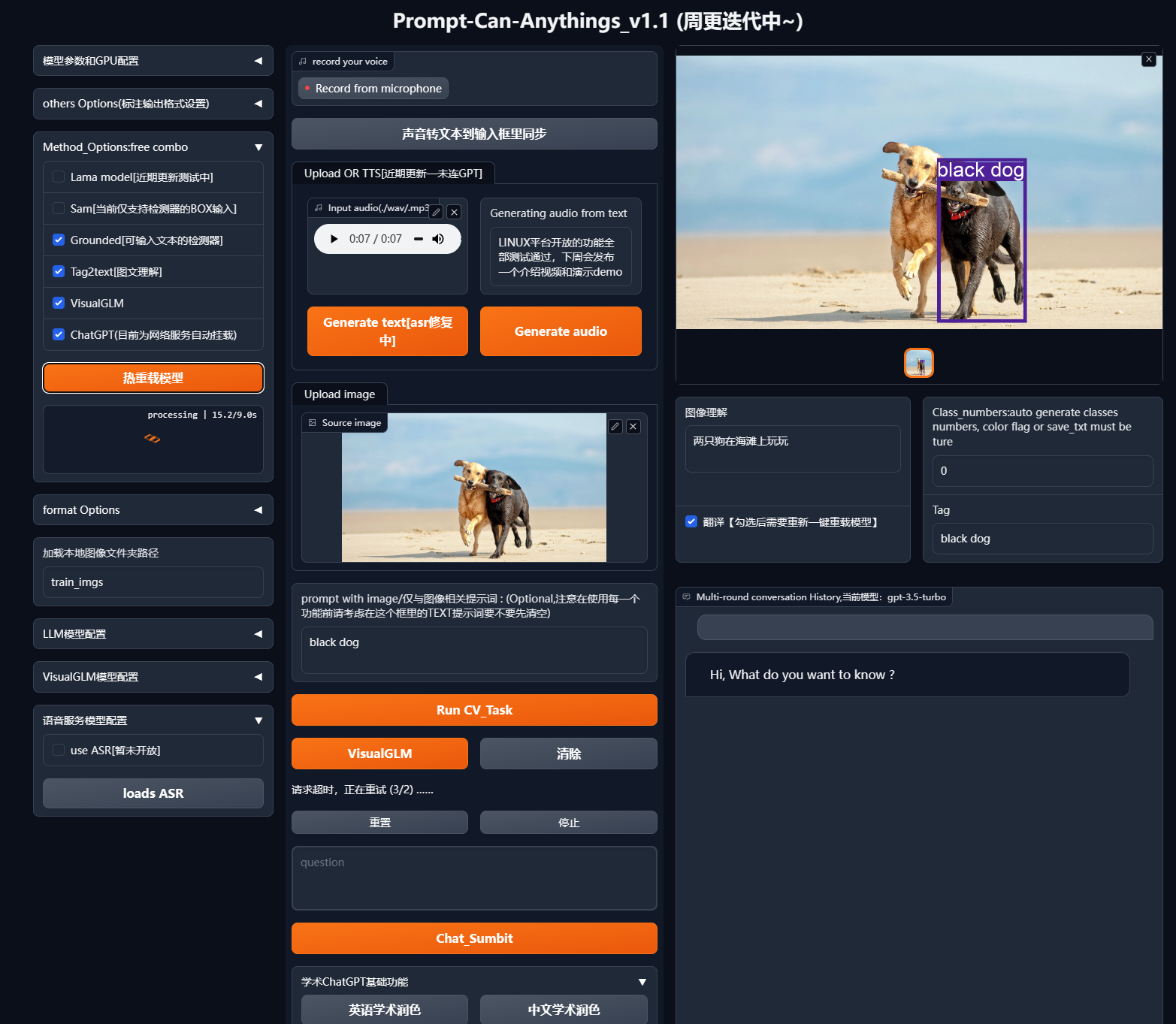
- Web UI界面
项目提供了一个功能丰富的Web UI界面,用户可以通过简单的操作实现各种AI任务。
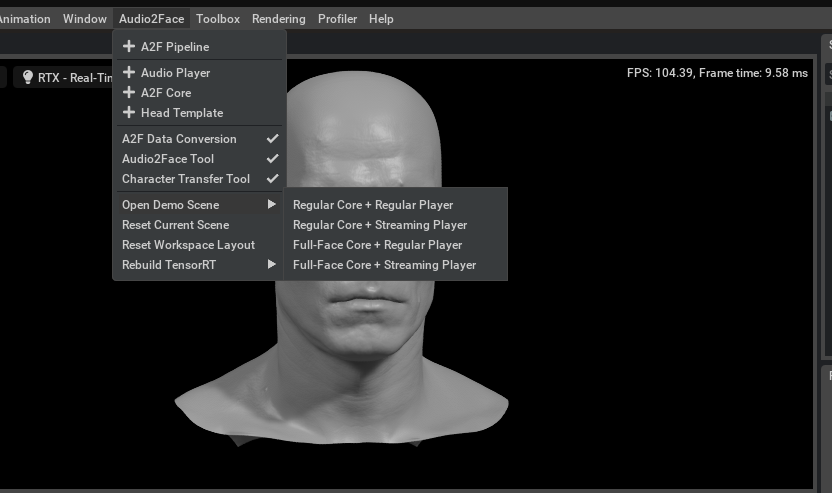
- 语音到虚拟形象
结合ASR、TTS和LLM模型,项目还支持语音到虚拟形象的功能,可以实现虚拟主播等应用。
未来展望
Prompt-Can-Anything项目仍在不断发展中,未来计划包括:
- 发布更多demo和代码
- 支持ChatGPT/VISUALGLM/ASR/TTS等功能
- 完善3D和2D虚拟形象功能
- 扩展SAM的输入控制
- 发布训练方法
- 实现知识克隆功能
结语
Prompt-Can-Anything项目展现了AI技术整合的巨大潜力。通过简单的提示和操作,用户可以轻松实现各种复杂的AI任务。随着项目的不断发展和完善,我们可以期待它在未来为更多领域带来创新和便利。无论是在研究还是实际应用中,Prompt-Can-Anything都将成为一个强大而灵活的AI工具平台。









