
 Github
Github Huggingface
Huggingface 论文
论文Prompt-Can-Anything
英文 | 中文
这是一个结合了最先进AI应用的gradio库和研究仓库。它可以帮助你实现任何事情 - 你只需提供提示并点击一下。通过提示和最先进模型的创造力,你可以做任何事情。你不必安装所有功能,可以根据你想使用的功能进行安装。
动机
目前,"Anything"AI智能代理后端已经积累了工程和研究经验。这需要使用更多的多模态任务和零样本模型,不仅提供多模态AI处理的网页界面,还要逐步丰富其功能。
通过这个项目,你可以完成任何事情!让我们了解更多关于这个项目的开发进展和计划,以及最终结合本地GPT仓库的完整智能代理可以帮助你调用任何AI任务!欢迎提问、点星、fork,你也可以成为开发者。
功能
-
(YOCO) 它不仅仅是一个可以提示任何事情的工具
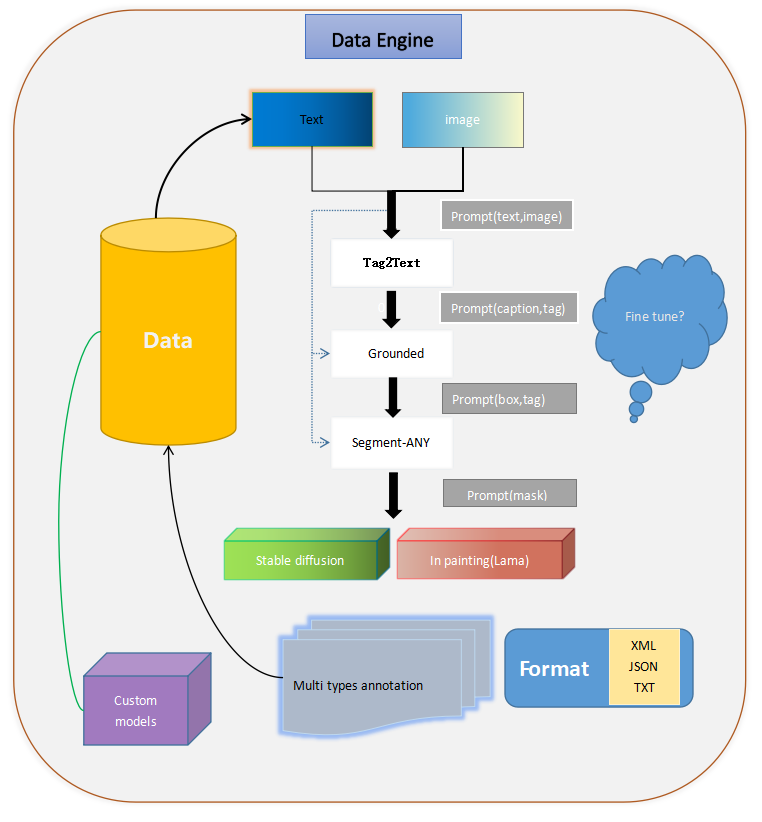
🔥 数据引擎:
此外,我们将在未来引入视频、音频和3D注释。YOCO依赖于集成的多模态模型和辅助生成器,如ChatGPT。当然,它并非无所不能。通过有效的全自动注释和稳定扩散系列方法来生产和控制符合要求的数据,我们完成了"数据引擎",并生成有利于训练常规模型的自定义标签格式。
🔥 模型训练:
对于每个模型,我们不仅需要使用它,还需要阅读其论文、微调方法,并与原作者沟通,尝试一些改进和更好训练的开发工作。我们使用微调大型模型和YOCO生成的自定义标签格式来更高效地训练常规模型。
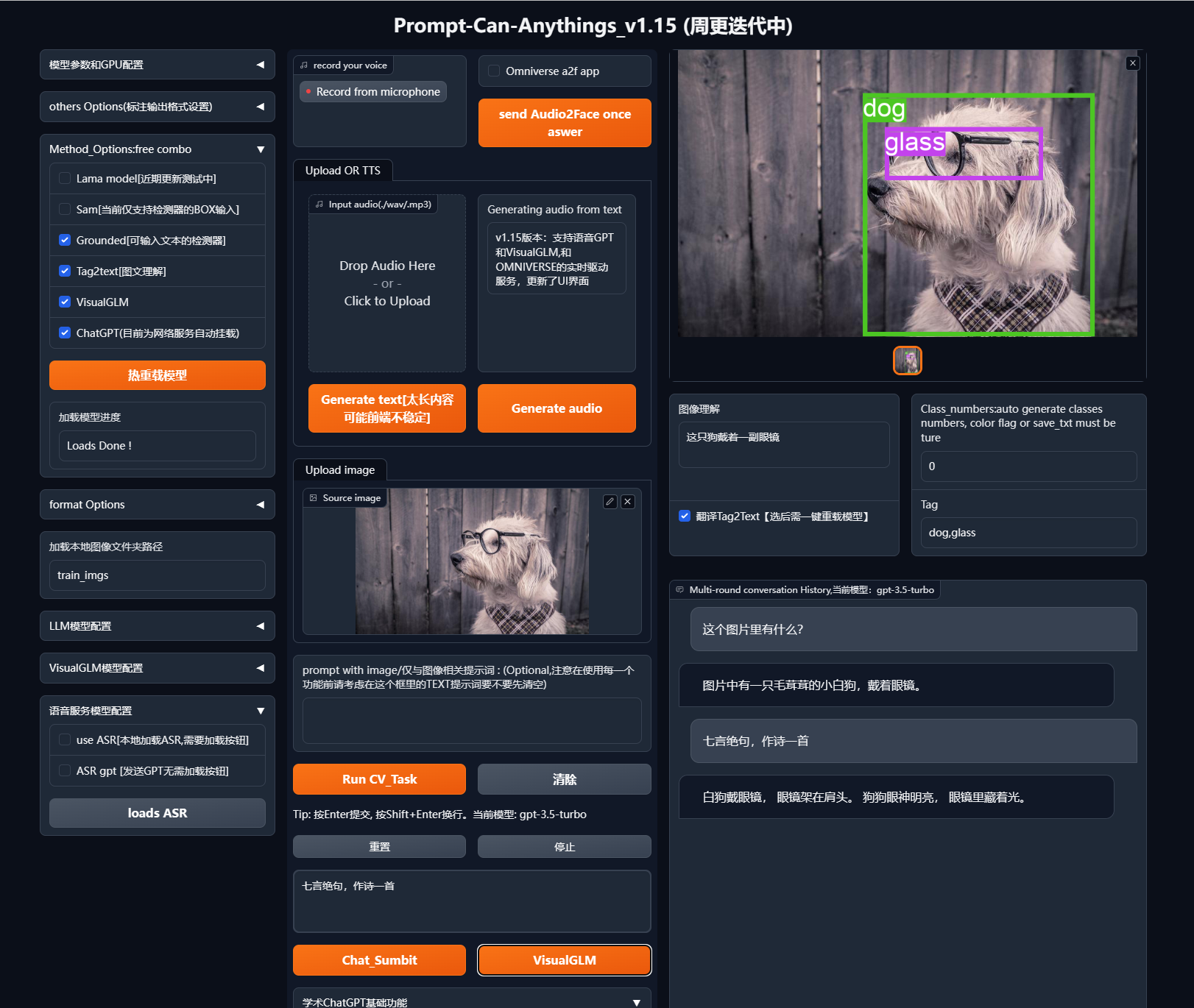
- 🚀 交互式内容创作和视觉GPT
整合多样化的GPT,主要使用chatgpt的接口,并使用开源的清华VISUALGLM部署和微调本地化GPT,同时尝试改进模型结构。通过多模态应用工具,我们可以进行对话和内容创作。
简单示例(asr->llM_model->tts->a2f app)
- ⭐ 3D && 2D 虚拟形象(即将推出)
通过3D引擎结合GPT等多模态任务完成角色设计交互;
通过Sadtalker开源项目和GPT等多模态任务完成角色设计交互。
- 🔥🔥🚀 无限潜力的"Anything"
通过持续的创造力和积累,我们将整合并学习最先进的AI。我们将记录每个集成的模型,并在文章中提供详细的解释和总结。作者将为本地大型模型总结所有AI相关知识储备和工程经验(这部分是最终开发功能,正在计划中)。
⭐ 研究🚀 项目🔥 灵感(准备中)
在研究层面,零样本对比学习是研究趋势,我们希望尽可能了解我们正在应用的项目的模型设计细节,以便我们想要结合文本、图像和音频来设计一个强对齐的骨干网络。 在项目层面,基础模型的Tensorrt加速提高效率。
🔥 [8月,更新计划预览,欢迎fork]
-
🔥 添加gpt_academic仓库的疯狂功能,并即将添加langchain\agent
-
优化语音问题和代码逻辑优化,添加Gilgen
-
🔥6月初Tag2text版本2的官方最新模型集成测试,添加RAM(已完成)
-
一键微调按钮功能,添加:visualglm(已完成)
-
语音文本处理链接GPT,加入chatglm与a2f APP(已完成)
⭐[新闻列表]
-【2023/8/7】 修复llm(chatglm2,gpt3.5加载和改进gradio ui)的bug
-【2023/7/21】 更新官方仓库的tag2text和ram
-【2023/6/7】 v1.15:添加子模块SadTalker,更新UI
-【2023/6/6】 v1.15:环境安装问题和补充说明,特殊模型独立调用,无需安装依赖;添加VisualGLM一键微调功能,考虑机器配置和显存请谨慎使用
-【2023/6/5】 v1.15 视频演示和计划,修复asr bug,chatgpt与asr和tts结合
-【2023/5/31】 修复已知问题,添加tts演示,Linux平台测试通过所有开放功能
-【2023/5/23】 添加网页演示:添加VisualGLM,来自Academic-gpt的chatgpt
-【2023/5/7】 添加网页演示:目前网站上生成文本、检测和分割图像或图像文件夹的功能已经正常测试,程序无需重启,记住上次模型加载配置,未来将持续优化。
-【2023/5/4】 添加语义分割标签,添加参数(--color-flag --save-mask )
-【2023/4/26】 YOCO,自动标注工具:提交初步代码,对输入的图像或文件夹,可以获得检测、分割和文本标注的结果,可选择chatgpt api。
前期工作
-
VisualGLM-6B : 视觉ChatGlm(6B)
-
Segment Anything : 强大的分割模型。但它需要提示(如框/点/文本)来生成掩码。
-
Grounding DINO : 强大的零样本检测器,能够使用自由形式的文本生成高质量的框和标签。
-
Stable-Diffusion : 惊人强大的文本到图像扩散模型。
-
Tag2text : 高效且可控的视觉语言模型,可同时输出优秀的图像描述和图像标签。
-
SadTalker: 学习现实的3D运动系数,用于风格化音频驱动的单图像说话面部动画
-
lama : 使用傅里叶卷积的分辨率鲁棒大掩码修复
-
gpt_academic : LLM工具。
:hammer_and_wrench: YOCO: 快速开始
首先,确保你有基本的GPU深度学习环境。
(推荐Linux,Windows可能在编译Grounded-DINO Deformable-transformer算子时出现问题,参见Grounding DINO)
git clone https://github.com/positive666/Prompt-Can-Anything
cd Prompt-Can-Anything
安装环境
安装基本环境
pip install -r requiremens
或
pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements.txt
Ground detector 安装(编译)
cd model_cards
pip install -e .
清华 VisualGLM 安装(可选,最好使用 LINUX 系统,Windows 测试后会更新安装方案)
git submodule update --init --recursive
cd VisualGLM_6B && pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements.txt
安装 SadTalker(可选)
git clone https://github.com/Winfredy/SadTalker.git
cd SadTalker && pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements.txt
提示:创建两个目录 checkpoints 和 gfpgan,并将它们放在根目录中。从官网下载提取的权重并放入这两个文件夹中。
LAMA 模型安装(可选,尚未发布):
该环境对 Python 版本要求较为严格,您可能需要按照以下 txt 中指定的版本手动覆盖安装:
pip install -r model_cards/lama/requirements.txt
diffuser 安装(可选):
pip install --upgrade diffusers[torch]
更多内容请查看 requirements,"pip install < 您缺失的包 >",如有安装版本问题,请仔细查看 requirement 版本。
Linux 环境问题:
- 关于 pyaudio
方法 1:
在 Linux 平台上 pip 可能无法成功,请访问此页面pyaudio-wheels · PyPI,选择与您的 Python 版本对应的版本,下载并 pip install 该 whl 文件。未来将提供详细说明。
方法 2:
sudo apt-get install portaudio19-dev
sudo apt-get install python3-all-dev
pip install pyaudio
-
使用 qlora 微调问题
pip install bitsandbytes -i https://mirrors.aliyun.com/pypi/simple
Windows 安装问题
与 Linux 相同
更多内容请查看 requirements,"pip install < 您缺失的包 >",如有安装版本问题,请仔细查看 requirements 中的版本。
运行
-
下载模型权重
-
在 config_private.py 中配置隐私文件和参数。下载模型后,在 "MODEL_xxxx_PATH" 变量中配置路径。如果使用 ChatGPT,请配置其代理和 API 密钥。(如果在 web UI 上使用时出现其他服务如 TTS 的网络问题,请先关闭 VPN 连接,仅在使用 ChatGPT 时打开)。
🏃演示
[视频演示 1 百度网盘在线](https://pan.baidu.com/s/1AllUjuOVhzJh7abe71iCxg?pwd=c6v6)
视频演示 2
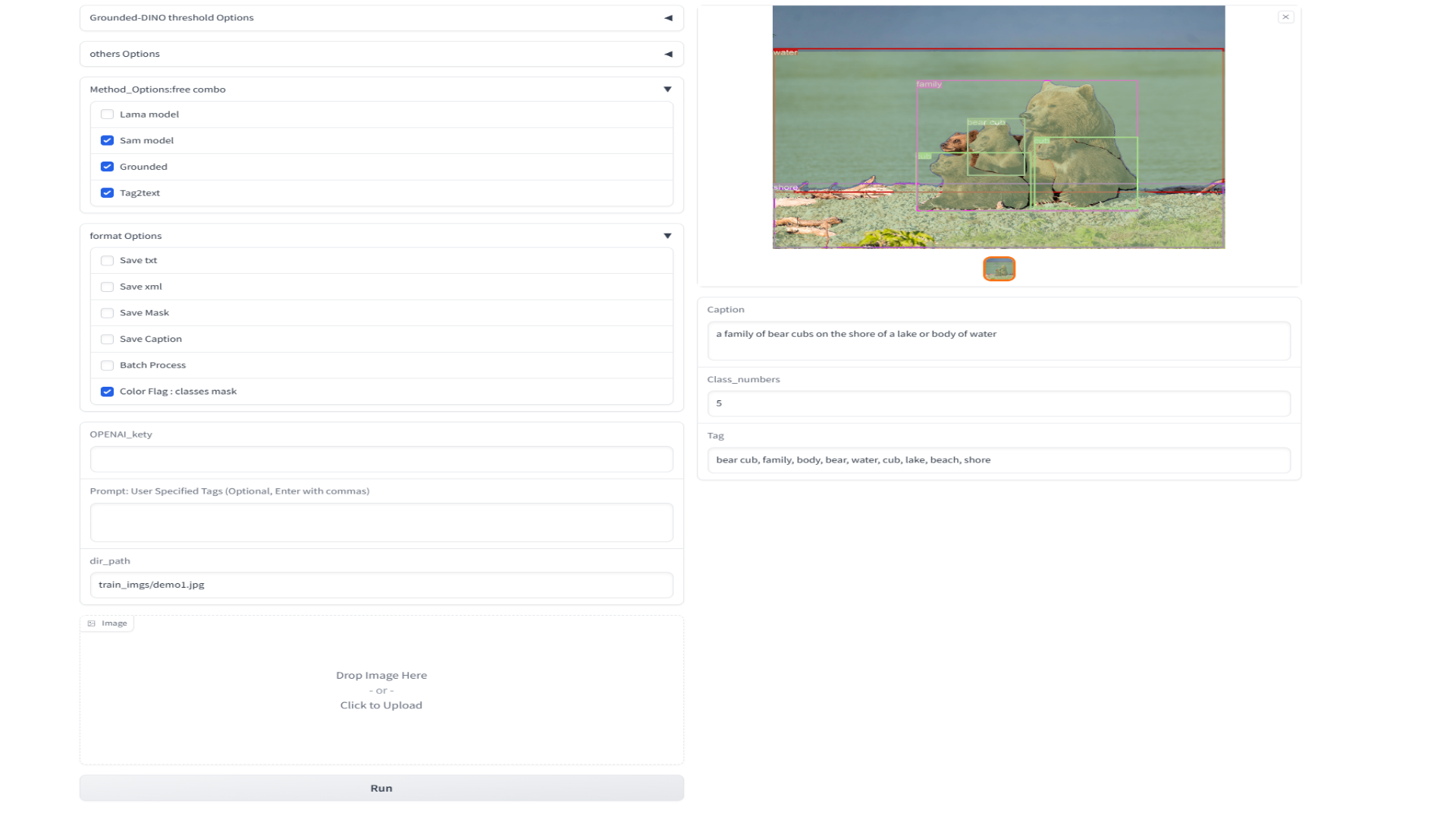
- 自动标注
"--input_prompt" : 您可以手动输入提示。例如,如果您只想检测感兴趣的目标类别,可以直接将提示输入到 grounded detection 模型,或输入到 Tag2Text 模型。
'--color-flag': 使用 BOX 的标签,区分类别和实例分割:语音分割的类别颜色使用 BOX 的标签进行区分。
python auto_lable_demo.py --source <数据路径> --save-txt --save-mask --save-xml --save_caption
示例:
支持多任务,如:
默认任务包括图像理解/检测/实例分割....(添加图像生成和修复方法)

"提示"控制模型输出,示例


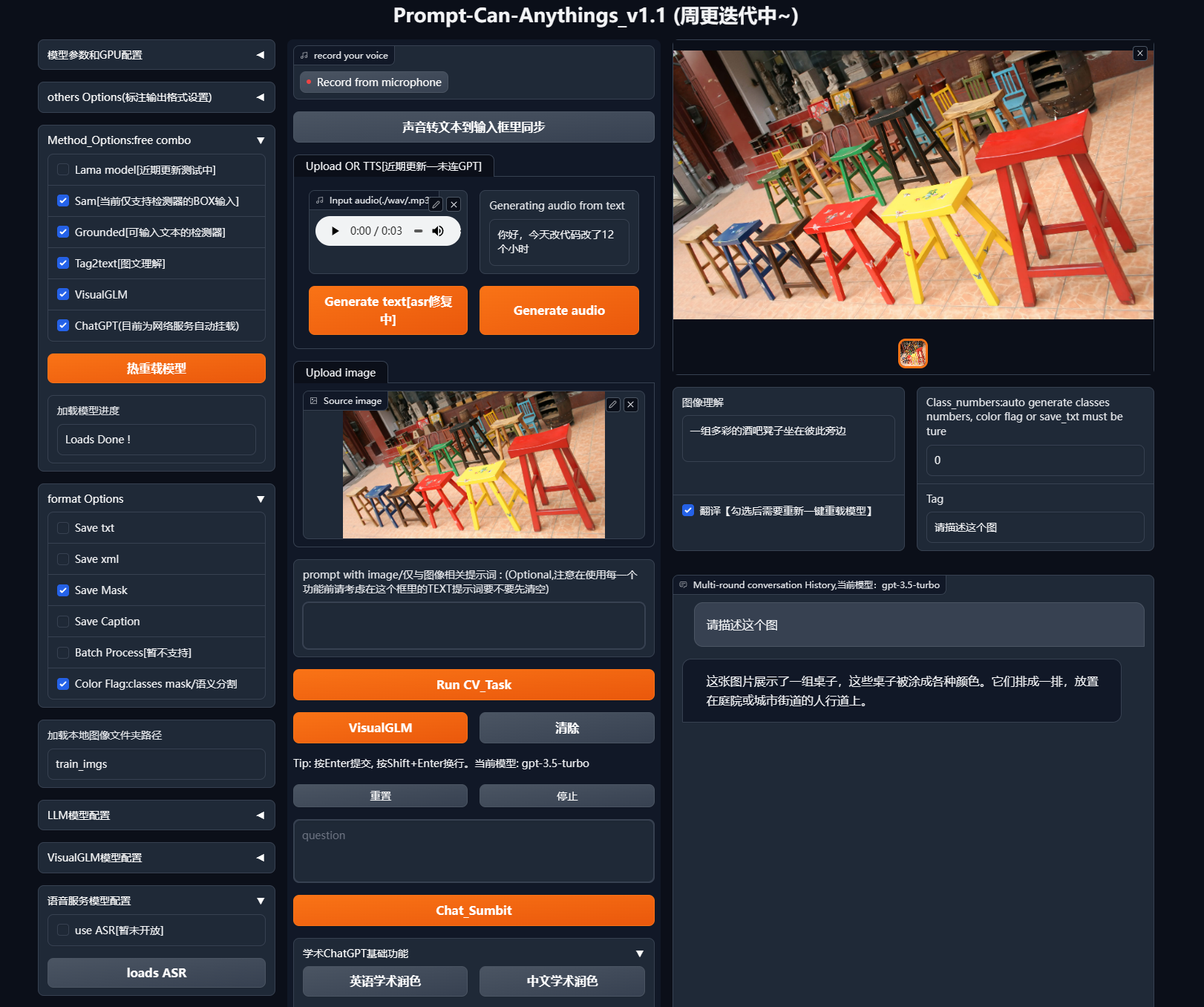
- webui(全部)
python app.py

2.1 使用LLM模型的音频到面部表情系统(测试版)
实际上,ASR、TTS和LLM都是可以任意替换的。
这是一个简单的示例,支持ChatGLM、ChatGPT(你可以使用任何LLM模型,但需要自定义)
启动带有音频到面部表情的ASR和TTS
你需要在Omniverse APP中安装Audio2Face,详见: https://www.nvidia.cn/omniverse/
步骤1. 在Audio2Face中,打开一个演示,选择一个角色,自动构建TRT引擎(不支持GTX10xx GPU),最新版本支持中文! 获取模型的pim路径。



步骤2. 在WebUI中,在config_private.py中配置你的Prim路径"Avatar_instance_A",点击"启动系统"和"语音系统"
🔨待办事项
- 发布演示和代码
- Web UI演示
- 支持ChatGPT/VISUALGLM/ASR/TTS
- YOCO标注微调VISUALGLM演示[下周]
- 3D和2D虚拟形象
- 完成计划中的AI组合"万物皆可"
- 微调SAM的分割和地面检测器,扩展SAM的输入控制
- 发布训练方法
- 知识克隆











