
RAPTOR简介 🌳
RAPTOR (Recursive Abstractive Processing for Tree-Organized Retrieval) 是一种新型的检索增强语言模型,通过构建文档的递归树结构来实现高效的信息检索。这种方法能够更好地处理大规模文本,并提供更精准的上下文感知能力,有效解决了传统语言模型的一些局限性。
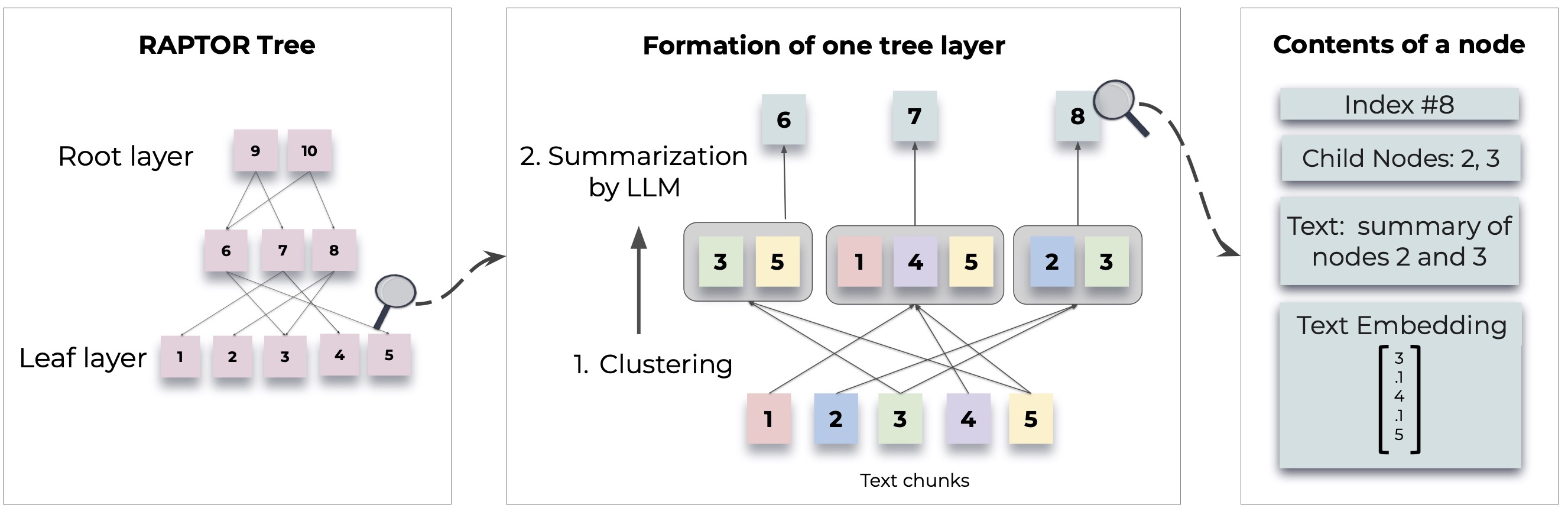
快速入门 🚀
要开始使用RAPTOR,请按照以下步骤操作:
- 确保安装Python 3.8+
- 克隆RAPTOR仓库并安装依赖:
git clone https://github.com/parthsarthi03/raptor.git
cd raptor
pip install -r requirements.txt
- 设置OpenAI API密钥并初始化RAPTOR:
import os
os.environ["OPENAI_API_KEY"] = "your-openai-api-key"
from raptor import RetrievalAugmentation
RA = RetrievalAugmentation()
- 添加文档并开始使用:
with open('sample.txt', 'r') as file:
text = file.read()
RA.add_documents(text)
question = "How did Cinderella reach her happy ending?"
answer = RA.answer_question(question=question)
print("Answer: ", answer)
核心功能 💡
- 文档索引: 将文本文档添加到RAPTOR的树结构中
- 问答系统: 基于索引的文档回答问题
- 树结构保存与加载: 保存和加载构建好的树结构
- 自定义模型集成: 支持集成自定义的摘要、问答和嵌入模型
进阶使用 🔧
RAPTOR的灵活设计允许用户集成自定义模型:
- 自定义摘要模型: 继承
BaseSummarizationModel类 - 自定义问答模型: 继承
BaseQAModel类 - 自定义嵌入模型: 继承
BaseEmbeddingModel类
详细的使用示例可以在项目的demo.ipynb文件中找到。
学习资源 📚
- RAPTOR论文: 深入了解RAPTOR的理论基础和实现细节
- GitHub仓库: 源代码、文档和示例
- 示例notebook: 包含使用Llama/Mistral/Gemma等模型的实例
贡献与支持 🤝
RAPTOR是一个开源项目,欢迎社区贡献。无论是修复bug、添加新功能还是改进文档,您的帮助都将受到赞赏。项目使用MIT许可证发布。
如果RAPTOR对您的研究有所帮助,请按以下格式引用:
@inproceedings{sarthi2024raptor,
title={RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval},
author={Sarthi, Parth and Abdullah, Salman and Tuli, Aditi and Khanna, Shubh and Goldie, Anna and Manning, Christopher D.},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}
更多示例、配置指南和更新,请持续关注RAPTOR的GitHub仓库。🌟










