
Recognize Anything Model: 开启图像识别新纪元
在计算机视觉领域,图像识别一直是一个核心且具有挑战性的任务。近年来,随着深度学习技术的发展,图像识别的准确率不断提高,但仍存在泛化能力不足、需要大量标注数据等问题。为解决这些痛点,研究人员提出了Recognize Anything Model (RAM),这是一个强大的开源图像识别基础模型,在零样本识别、通用性和准确率等方面都取得了突破性进展。
RAM的核心特点
RAM具有以下几个突出的特点:
-
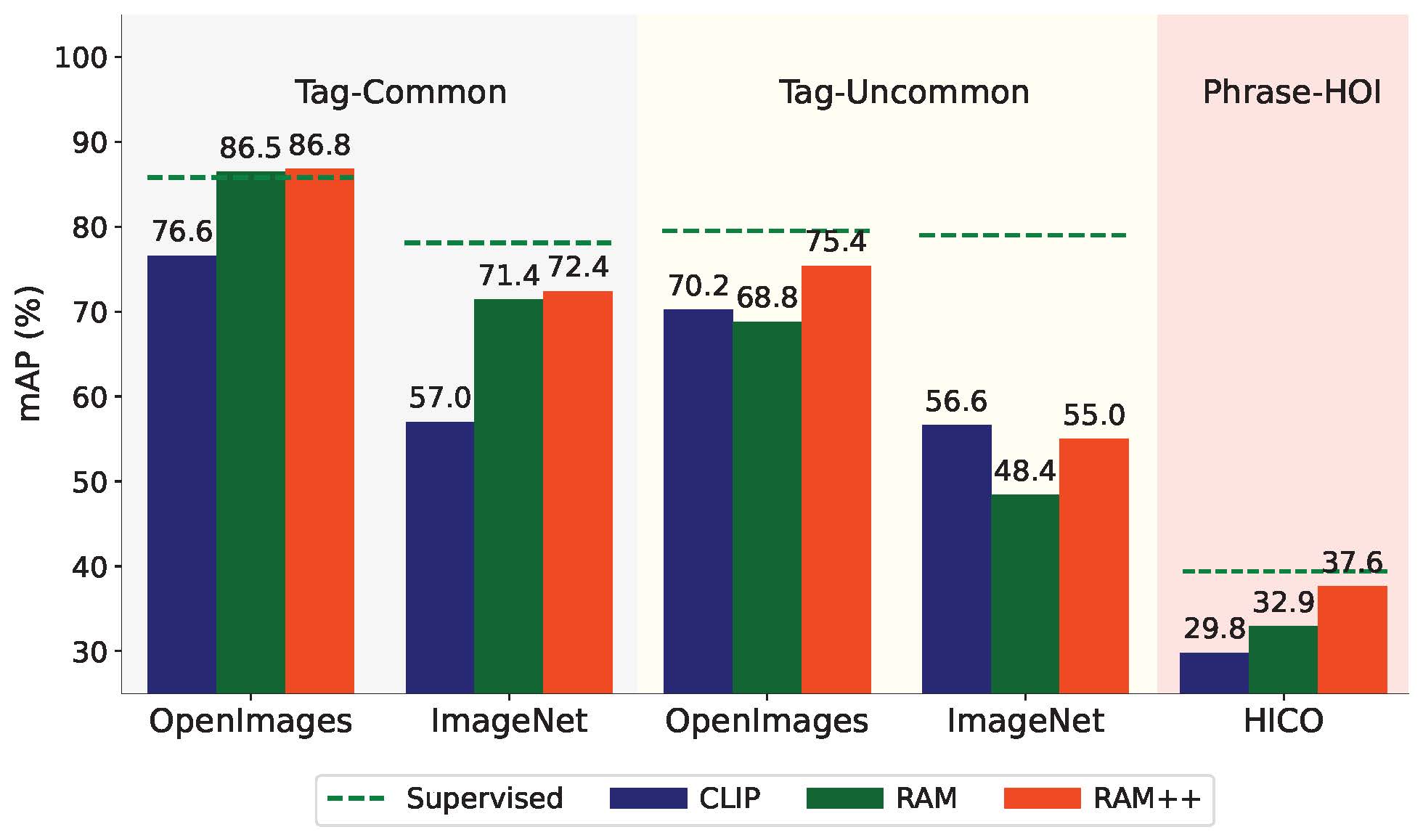
强大的零样本识别能力:RAM可以准确识别训练中未见过的类别,展现出优秀的泛化性能。
-
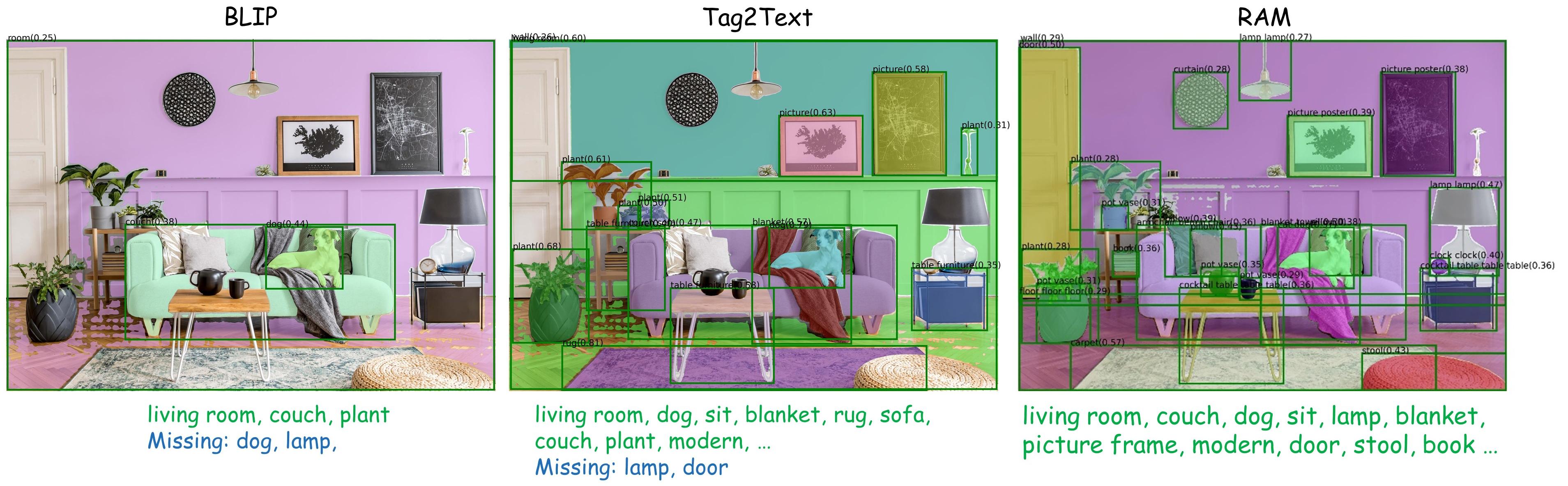
高精度的图像标记:对于常见类别,RAM的识别准确率甚至超过了全监督学习模型。
-
开放集识别:RAM++版本进一步增强了识别未知类别的能力。
-
低成本可复现:RAM采用开源数据集训练,降低了复现成本。
-
灵活多用途:RAM可以应用于多种场景,如图像搜索、内容审核等。
RAM的技术原理
RAM基于vision-language模型架构,主要包含以下几个关键组件:
-
视觉编码器:采用Swin Transformer作为主干网络,提取图像的高级语义特征。
-
文本解码器:使用Transformer解码器生成标签和描述文本。
-
多粒度文本监督:结合图像标签和描述文本进行训练,增强模型的语义理解能力。
-
数据引擎:自动生成和清洗训练数据,提高标注质量。
-
开放集识别模块:RAM++引入LLM生成的标签描述,增强对未知类别的识别能力。
这种设计使得RAM在保持高精度的同时,具备了强大的泛化能力和灵活性。
RAM的应用场景
RAM的出现为计算机视觉领域带来了新的可能性,它可以应用于多种场景:
-
图像搜索与检索:RAM可以为图像生成准确的标签,提升搜索的精准度。
-
内容审核:自动识别和标记敏感内容,提高审核效率。
-
辅助医疗诊断:识别医学图像中的异常特征,辅助医生诊断。
-
智能零售:自动识别商品类别,优化库存管理。
-
自动驾驶:识别道路环境中的各种物体,提高安全性。
RAM的训练与使用
RAM的训练过程包括以下步骤:
-
准备训练数据:使用COCO、Visual Genome等开源数据集。
-
预训练:使用多GPU并行训练,优化模型参数。
-
微调:在特定任务上进行微调,提升模型性能。
使用RAM进行推理非常简单,只需几行代码即可:
from ram.models import ram_plus
model = ram_plus(pretrained="path/to/checkpoint.pth")
image_tags = model.generate(image_path)
print(image_tags)
RAM的未来发展
尽管RAM已经展现出惊人的性能,但研究人员仍在不断改进和扩展其功能:
- 进一步提高开放集识别能力
- 结合多模态信息,如视频和音频
- 探索在更大规模数据集上的训练
- 优化模型结构,提高推理速度
结语
Recognize Anything Model (RAM)代表了图像识别技术的最新进展,它不仅在精度上超越了现有方法,还展现出强大的泛化能力和灵活性。作为一个开源项目,RAM为研究人员和开发者提供了一个强大的工具,有望推动计算机视觉领域的进一步发展。随着RAM的不断完善和应用,我们可以期待看到更多激动人心的创新应用出现。









