
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文:label: 识别万物模型
本项目旨在开发一系列开源且强大的基础图像识别模型。





-
识别万物增强模型 (RAM++) [论文]
RAM++是RAM的下一代版本,能够高精度识别任何类别,包括预定义的常见类别和多样化的开放集类别。
-
RAM是一个图像标记模型,能够高精度识别任何常见类别。
RAM已被CVPR 2024多模态基础模型研讨会接收。
-
Tag2Text (ICLR 2024) [论文] [演示]
Tag2Text是一个由标记引导的视觉-语言模型,可以同时支持标记和全面的描述生成。
Tag2Text已被ICLR 2024接收!维也纳见!
:bulb: 亮点
卓越的图像识别能力
RAM++在常见标签类别、非常见标签类别和人-物交互短语方面的表现优于现有的最先进图像基础识别模型。
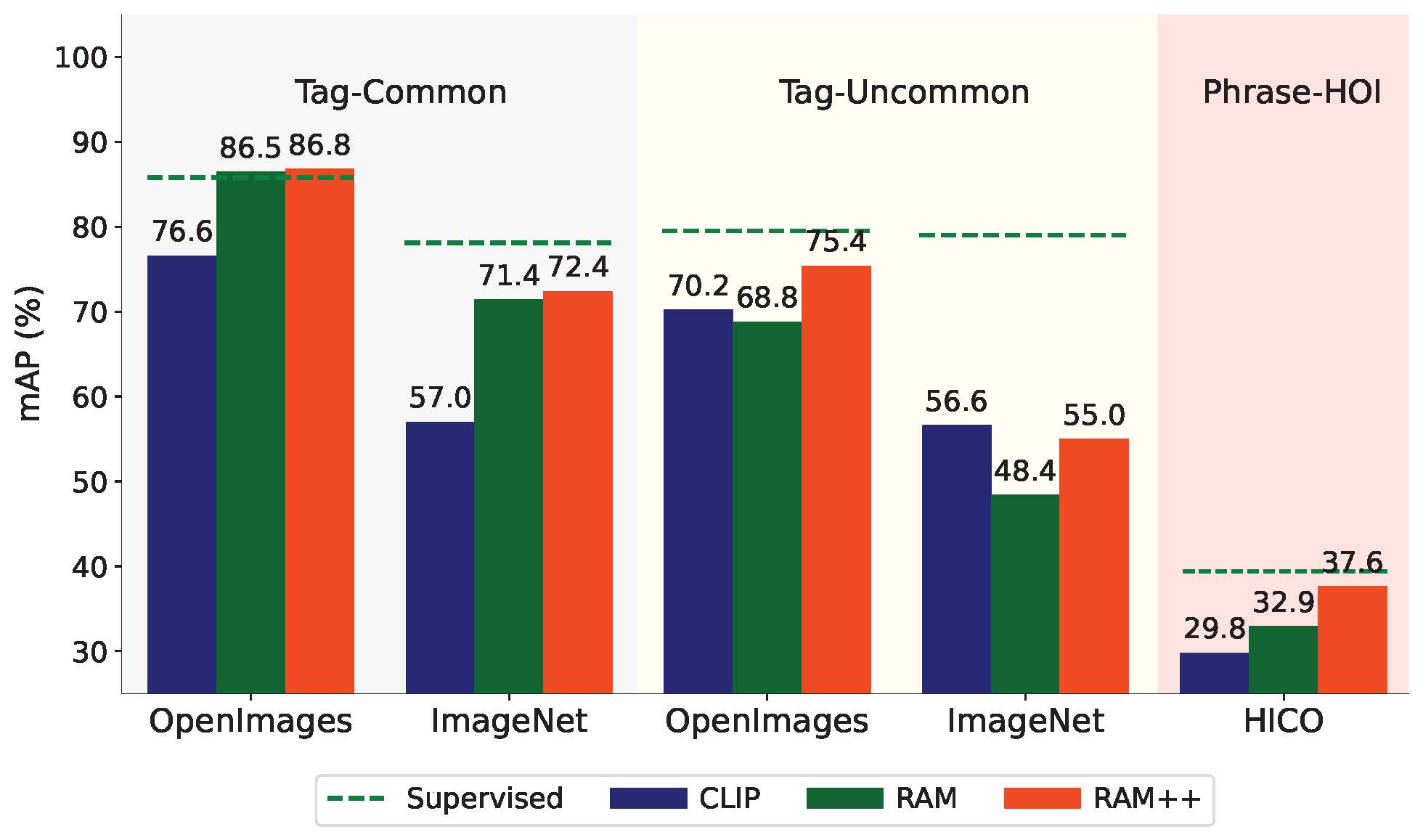 |
零样本图像识别性能比较。
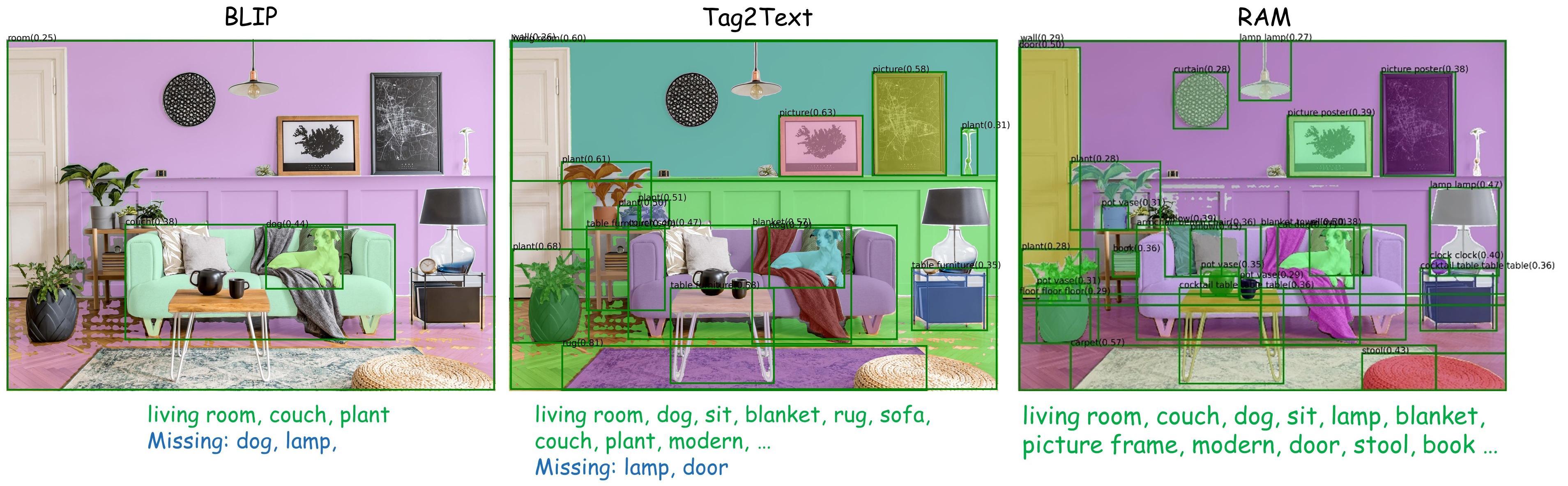
强大的视觉语义分析
我们将Tag2Text和RAM与定位模型(Grounding-DINO和SAM)结合,在Grounded-SAM项目中开发了一个强大的视觉语义分析流程。
:sunrise: 模型库
RAM++
RAM++是RAM的下一代版本,能够高精度识别任何类别,包括预定义的常见类别和多样化的开放集类别。
-
对于常见预定义类别。 RAM++展现了卓越的图像标记能力,具有强大的零样本泛化能力,保持了与RAM相同的能力。
-
对于多样化的开放集类别。 RAM++在CLIP和RAM的基础上实现了显著的增强。
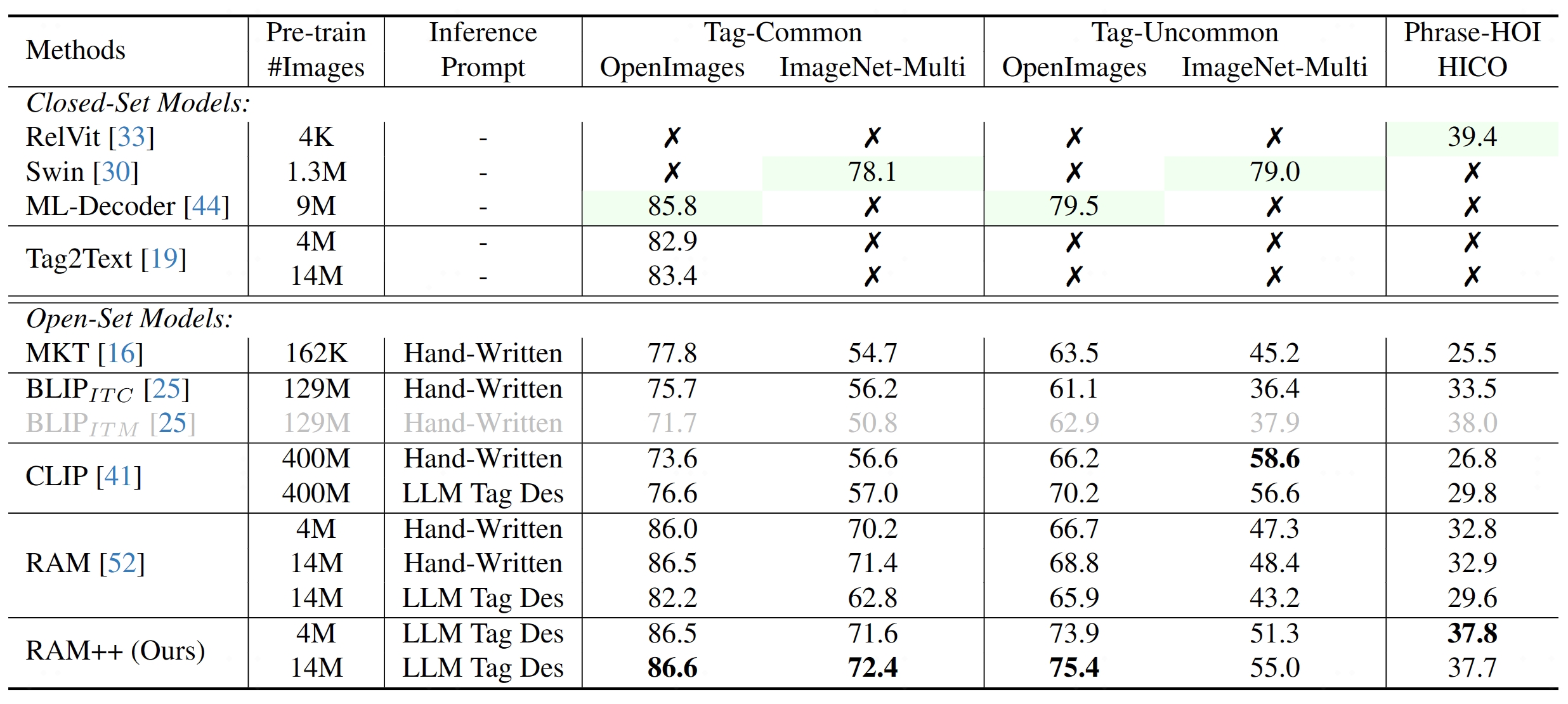 |
(绿色表示完全监督学习,其他表示零样本性能。)
 |
RAM++在开放集类别识别方面展现出显著提升。
RAM
RAM是一个强大的图像标记模型,能够高精度识别任何常见类别。
- 强大且通用。 RAM展现了卓越的图像标记能力,具有强大的零样本泛化能力;
- RAM展示了令人印象深刻的零样本性能,显著优于CLIP和BLIP。
- RAM甚至超越了完全监督方法(ML-Decoder)。
- RAM与Google标记API表现相当。
- 可复现且经济实惠。 RAM使用开源和无需标注的数据集,复现成本低;
- 灵活多用。 RAM提供了卓越的灵活性,适用于各种应用场景。
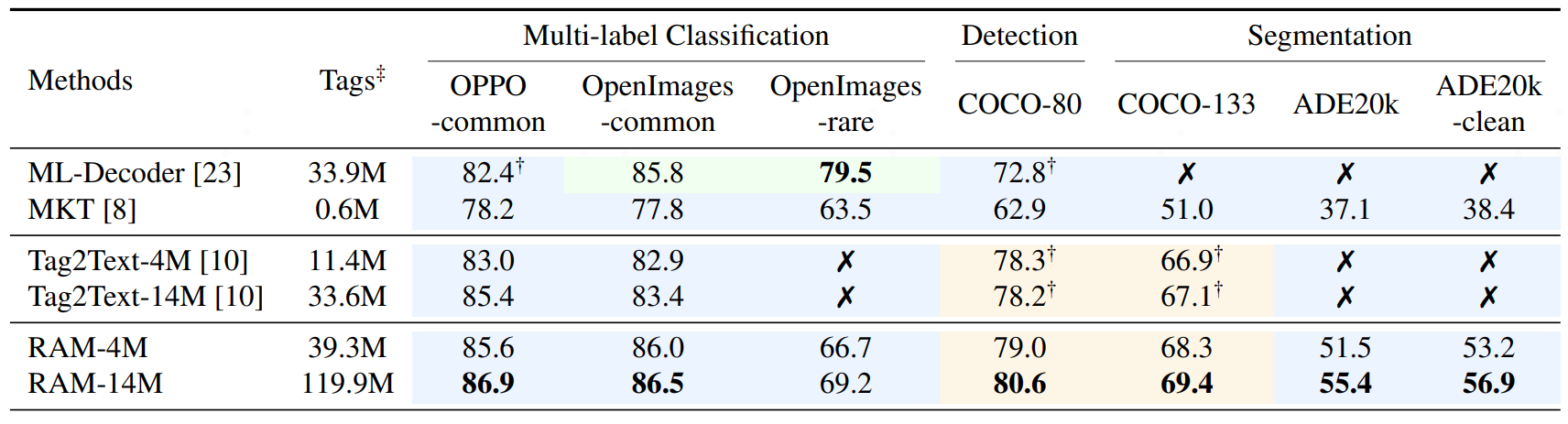 |
(绿色表示完全监督学习,蓝色表示零样本性能。)
 |
RAM在Tag2text框架的基础上显著改进了标记能力。
- 准确性。 RAM利用数据引擎来生成额外的标注并清理不正确的标注,与Tag2Text相比准确性更高。
- 范围。 RAM将固定标签数量从3,400+升级到**6,400+(同义词归约后为4,500+个不同语义标签),涵盖更多有价值的类别**。 此外,RAM具备开放集能力,可以识别训练期间未见过的标签。
Tag2text
Tag2Text是一个高效且可控的视觉语言模型,通过标签指导实现。- 标签。 Tag2Text可识别**3,400多个**常用人类类别,无需人工标注。
- 描述。 Tag2Text将标签信息作为引导元素整合到文本生成中,从而生成更可控和全面的描述。
- 检索。 Tag2Text提供标签作为图像-文本检索的额外可见对齐指标。
 |
Tag2Text在标签指导下生成更全面的描述。
 |
Tag2Text提供标签作为额外的可见对齐指标。
训练数据集
图像文本和标签
这些标注文件来自Tag2Text和RAM。Tag2Text从图像-文本对中自动提取图像标签。RAM通过自动数据引擎进一步增强了标签和文本。
| 数据集 | 大小 | 图像数 | 文本数 | 标签数 |
|---|---|---|---|---|
| COCO | 168 MB | 113K | 680K | 3.2M |
| VG | 55 MB | 100K | 923K | 2.7M |
| SBU | 234 MB | 849K | 1.7M | 7.6M |
| CC3M | 766 MB | 2.8M | 5.6M | 28.2M |
| CC3M-val | 3.5 MB | 12K | 26K | 132K |
CC12M将在下一次更新中发布。
LLM标签描述
这些标签描述文件来自RAM++,通过调用GPT API生成。您也可以使用generate_tag_des_llm.py自定义任何标签类别。
| 标签描述 | 标签列表 |
|---|---|
| RAM标签列表 | 4,585 |
| OpenImages不常见 | 200 |
:toolbox: 检查点
注意:您需要创建"pretrained"文件夹并将这些检查点下载到该文件夹中。
| 名称 | 骨干网络 | 数据 | 说明 | 检查点 | |
|---|---|---|---|---|---|
| 1 | RAM++ (14M) | Swin-Large | COCO, VG, SBU, CC3M, CC3M-val, CC12M | 为任何类别提供强大的图像标记能力。 | 下载链接 |
| 2 | RAM (14M) | Swin-Large | COCO, VG, SBU, CC3M, CC3M-val, CC12M | 为常见类别提供强大的图像标记能力。 | 下载链接 |
| 3 | Tag2Text (14M) | Swin-Base | COCO, VG, SBU, CC3M, CC3M-val, CC12M | 支持全面的图像描述和标记。 | 下载链接 |
:running: 模型推理
环境设置
- 创建并激活Conda环境:
conda create -n recognize-anything python=3.8 -y
conda activate recognize-anything
- 将
recognize-anything作为包安装:
pip install git+https://github.com/xinyu1205/recognize-anything.git
- 或者,如果是开发目的,您可以从源代码构建:
git clone https://github.com/xinyu1205/recognize-anything.git
cd recognize-anything
pip install -e .
然后可以在其他项目中导入RAM++、RAM和Tag2Text模型:
from ram.models import ram_plus, ram, tag2text
RAM++推理
获取图像的英文和中文输出:
python inference_ram_plus.py --image images/demo/demo1.jpg --pretrained pretrained/ram_plus_swin_large_14m.pth
输出将如下所示:
Image Tags: armchair | blanket | lamp | carpet | couch | dog | gray | green | hassock | home | lay | living room | picture frame | pillow | plant | room | wall lamp | sit | wood floor
图像标签: 扶手椅 | 毯子/覆盖层 | 灯 | 地毯 | 沙发 | 狗 | 灰色 | 绿色 | 坐垫/搁脚凳/草丛 | 家/住宅 | 躺 | 客厅 | 相框 | 枕头 | 植物 | 房间 | 壁灯 | 坐/放置/坐落 | 木地板
RAM++对未见类别的推理(开放集)
- 获取图像的OpenImages-Uncommon类别:
我们已经在openimages_rare_200_llm_tag_descriptions中发布了OpenImages-Uncommon类别的LLM标签描述。
python inference_ram_plus_openset.py --image images/openset_example.jpg \ --pretrained pretrained/ram_plus_swin_large_14m.pth \ --llm_tag_des datasets/openimages_rare_200/openimages_rare_200_llm_tag_descriptions.json
输出将如下所示:
Image Tags: Close-up | Compact car | Go-kart | Horse racing | Sport utility vehicle | Touring car
- 您还可以通过标签描述自定义任何标签类别进行识别:
修改categories,并调用GPT API生成相应的标签描述:
python generate_tag_des_llm.py \ --openai_api_key '您的openai api密钥' \ --output_file_path datasets/openimages_rare_200/openimages_rare_200_llm_tag_descriptions.json
批量推理和评估
我们发布了两个数据集OpenImages-common(214个常见标签类别)和OpenImages-rare(200个不常见标签类别)。将OpenImages v6的测试图像复制或符号链接到datasets/openimages_common_214/imgs/和datasets/openimages_rare_200/imgs。
要在OpenImages-common上评估RAM++:
python batch_inference.py \
--model-type ram_plus \
--checkpoint pretrained/ram_plus_swin_large_14m.pth \
--dataset openimages_common_214 \
--output-dir outputs/ram_plus
要评估RAM++在OpenImages-rare上的开放集能力:
python batch_inference.py \
--model-type ram_plus \
-- pretrained/ram_plus_swin_large_14m.pth \
--open-set \
--dataset openimages_rare_200 \
--output-dir outputs/ram_plus_openset
在 OpenImages-common 上评估 RAM:
python batch_inference.py \
--model-type ram \
-- pretrained/ram_swin_large_14m.pth \
--dataset openimages_common_214 \
--output-dir outputs/ram
在 OpenImages-rare 上评估 RAM 的开放集能力:
python batch_inference.py \
--model-type ram \
-- pretrained/ram_swin_large_14m.pth \
--open-set \
--dataset openimages_rare_200 \
--output-dir outputs/ram_openset
在 OpenImages-common 上评估 Tag2Text:
python batch_inference.py \
--model-type tag2text \
-- pretrained/tag2text_swin_14m.pth \
--dataset openimages_common_214 \
--output-dir outputs/tag2text
更多选项请参考 batch_inference.py。要获得 RAM 论文表 3 中的 P/R,请为 RAM 传递 --threshold=0.86,为 Tag2Text 传递 --threshold=0.68。
要对自定义图像进行批量推理,您可以按照给定的两个数据集设置自己的数据集。
:golfing: 模型训练/微调
RAM++
-
下载 RAM 训练数据集,其中每个 json 文件包含一个列表。列表中的每个项目是一个包含三个键值对的字典:{'image_path': 图像路径, 'caption': 图像文本, 'union_label_id': 用于标记的图像标签,包括解析标签和伪标签}。
-
在 ram/configs/pretrain.yaml 中,将 'train_file' 设置为 json 文件的路径。
-
准备 预训练的 Swin-Transformer,并在 ram/configs/swin 中设置 'ckpt'。
-
下载 RAM++ 冻结标签嵌入文件 "ram_plus_tag_embedding_class_4585_des_51.pth",并将文件设置在 "ram/data/frozen_tag_embedding/ram_plus_tag_embedding_class_4585_des_51.pth"。
-
使用 8 个 A100 GPU 预训练模型:
python -m torch.distributed.run --nproc_per_node=8 pretrain.py \
--model-type ram_plus \
--config ram/configs/pretrain.yaml \
--output-dir outputs/ram_plus
- 使用 8 个 A100 GPU 微调预训练的检查点:
python -m torch.distributed.run --nproc_per_node=8 finetune.py \
--model-type ram_plus \
--config ram/configs/finetune.yaml \
--checkpoint outputs/ram_plus/checkpoint_04.pth \
--output-dir outputs/ram_plus_ft
RAM
-
下载 RAM 训练数据集,其中每个 json 文件包含一个列表。列表中的每个项目是一个包含四个键值对的字典:{'image_path': 图像路径, 'caption': 图像文本, 'union_label_id': 用于标记的图像标签,包括解析标签和伪标签, 'parse_label_id': 从标题解析的图像标签}。
-
在 ram/configs/pretrain.yaml 中,将 'train_file' 设置为 json 文件的路径。
-
准备 预训练的 Swin-Transformer,并在 ram/configs/swin 中设置 'ckpt'。
-
下载 RAM 冻结标签嵌入文件 "ram_tag_embedding_class_4585.pth",并将文件设置在 "ram/data/frozen_tag_embedding/ram_tag_embedding_class_4585.pth"。
-
使用 8 个 A100 GPU 预训练模型:
python -m torch.distributed.run --nproc_per_node=8 pretrain.py \
--model-type ram \
--config ram/configs/pretrain.yaml \
--output-dir outputs/ram
- 使用 8 个 A100 GPU 微调预训练的检查点:
python -m torch.distributed.run --nproc_per_node=8 finetune.py \
--model-type ram \
--config ram/configs/finetune.yaml \
--checkpoint outputs/ram/checkpoint_04.pth \
--output-dir outputs/ram_ft
Tag2Text
-
下载 RAM 训练数据集,其中每个 json 文件包含一个列表。列表中的每个项目是一个包含三个键值对的字典:{'image_path': 图像路径, 'caption': 图像文本, 'parse_label_id': 从标题解析的图像标签}。
-
在 ram/configs/pretrain_tag2text.yaml 中,将 'train_file' 设置为 json 文件的路径。
-
准备 预训练的 Swin-Transformer,并在 ram/configs/swin 中设置 'ckpt'。
-
使用 8 个 A100 GPU 预训练模型:
python -m torch.distributed.run --nproc_per_node=8 pretrain.py \
--model-type tag2text \
--config ram/configs/pretrain_tag2text.yaml \
--output-dir outputs/tag2text
- 使用 8 个 A100 GPU 微调预训练的检查点:
python -m torch.distributed.run --nproc_per_node=8 finetune.py \
--model-type tag2text \
--config ram/configs/finetune_tag2text.yaml \
--checkpoint outputs/tag2text/checkpoint_04.pth \
--output-dir outputs/tag2text_ft
:black_nib: 引用
如果您发现我们的工作对您的研究有用,请考虑引用。
@article{huang2023open,
title={Open-Set Image Tagging with Multi-Grained Text Supervision},
author={Huang, Xinyu and Huang, Yi-Jie and Zhang, Youcai and Tian, Weiwei and Feng, Rui and Zhang, Yuejie and Xie, Yanchun and Li, Yaqian and Zhang, Lei},
journal={arXiv e-prints},
pages={arXiv--2310},
year={2023}
}
@article{zhang2023recognize,
title={Recognize Anything: A Strong Image Tagging Model},
author={Zhang, Youcai and Huang, Xinyu and Ma, Jinyu and Li, Zhaoyang and Luo, Zhaochuan and Xie, Yanchun and Qin, Yuzhuo and Luo, Tong and Li, Yaqian and Liu, Shilong and others},
journal={arXiv preprint arXiv:2306.03514},
year={2023}
}
@article{huang2023tag2text,
title={Tag2Text: Guiding Vision-Language Model via Image Tagging},
author={Huang, Xinyu and Zhang, Youcai and Ma, Jinyu and Tian, Weiwei and Feng, Rui and Zhang, Yuejie and Li, Yaqian and Guo, Yandong and Zhang, Lei},
journal={arXiv preprint arXiv:2303.05657},
year={2023}
}
:hearts: 致谢
这项工作是在 BLIP 这个优秀代码库的帮助下完成的,非常感谢!
我们要感谢 @Cheng Rui @Shilong Liu @Ren Tianhe 在 将 RAM/Tag2Text 与 Grounded-SAM 结合 方面的帮助。
我们还要感谢 Ask-Anything 和 Prompt-can-anything 结合了 RAM/Tag2Text,这极大地扩展了 RAM/Tag2Text 的应用边界。











