
RGT: 面向图像超分辨率的递归泛化Transformer
图像超分辨率(SR)作为计算机视觉领域的一个重要任务,一直受到学术界和工业界的广泛关注。近年来,Transformer架构在图像SR任务中展现出了卓越的性能。然而,由于自注意力(SA)机制的二次计算复杂度,现有方法往往倾向于在局部区域内采用SA以降低计算开销。这种局部设计限制了全局上下文信息的利用,而全局信息对于精确的图像重建至关重要。
为了解决这一问题,来自中国科学技术大学和上海交通大学的研究团队提出了一种名为递归泛化Transformer(Recursive Generalization Transformer, RGT)的新型图像SR方法。该方法能够有效捕获全局空间信息,并且适用于高分辨率图像处理。
RGT的核心创新
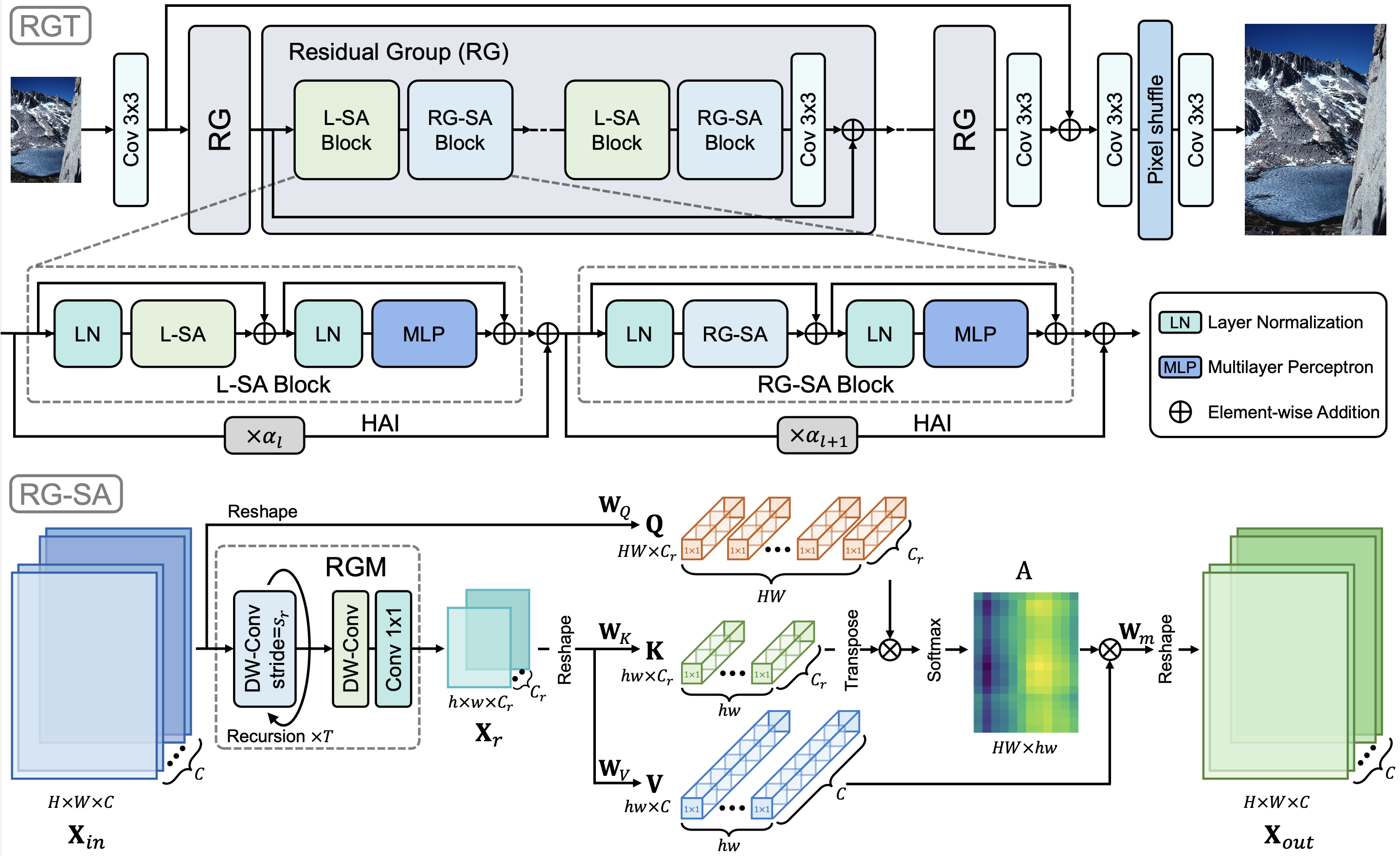
RGT的核心创新在于提出了递归泛化自注意力(RG-SA)机制。具体而言:
-
递归聚合: RG-SA通过递归的方式将输入特征聚合成具有代表性的特征图。
-
交叉注意力: 利用交叉注意力机制从聚合后的特征中提取全局信息。
-
通道维度缩放: 对注意力矩阵(query、key和value)的通道维度进行缩放,以减少通道域中的冗余。
-
混合自适应集成(HAI): 将RG-SA与局部自注意力相结合,并提出HAI模块实现不同层次(局部或全局)特征的直接有效融合。
RGT的性能优势
通过大量实验,RGT在定量和定性评估中都展现出了优于现有最先进方法的性能:
-
定量评估: 在多个公开数据集(如Set5、Set14、BSD100、Urban100和Manga109)上进行了全面测试。结果显示,RGT在PSNR和SSIM指标上均优于现有方法。
-
定性评估: 视觉对比结果表明,RGT能够更好地恢复图像细节和纹理,尤其在处理复杂结构和高频信息时表现突出。
-
计算效率: 尽管引入了全局信息处理,RGT仍然保持了较高的计算效率,适用于实际应用场景。
RGT的实现细节
RGT的实现基于PyTorch框架,主要依赖如下:
- Python 3.8
- PyTorch 1.9.0
- NVIDIA GPU + CUDA
研究团队提供了详细的安装指南和使用说明,包括数据集准备、模型训练和测试等步骤。感兴趣的读者可以通过GitHub仓库获取完整代码和预训练模型。
RGT的应用前景
RGT在图像SR领域展现出的优异性能为其在实际应用中的广泛使用奠定了基础。潜在的应用场景包括但不限于:
-
医学影像: 提高医疗图像的分辨率,辅助医生进行更精确的诊断。
-
遥感图像处理: 增强卫星和航拍图像的细节,用于环境监测和城市规划。
-
视频监控: 提升监控视频的清晰度,改善安防系统的识别能力。
-
消费电子: 优化智能手机、平板电脑等设备的图像显示质量。
-
数字文化遗产: 修复和增强历史图像和文献,助力文化保护工作。
结论与展望
RGT为图像超分辨率任务提供了一种新的解决方案,通过创新的递归泛化自注意力机制和混合自适应集成模块,实现了全局上下文信息的高效提取和利用。其在多个公开数据集上的优异表现证明了该方法的有效性和潜力。
未来的研究方向可能包括:
-
进一步优化RGT的计算效率,使其更适合移动设备等资源受限的场景。
-
探索RGT在其他计算机视觉任务中的应用,如图像去噪、图像修复等。
-
结合最新的人工智能技术,如大规模语言模型,进一步提升RGT的性能和适应性。
-
研究RGT在实时视频超分辨率中的应用,以满足日益增长的高质量视频需求。
总的来说,RGT为图像超分辨率领域带来了新的突破,为相关研究和应用开辟了广阔的前景。随着技术的不断发展和完善,我们有理由相信RGT及其衍生方法将在计算机视觉领域发挥越来越重要的作用。


















