
 访问官网
访问官网 Github
Github 论文
论文递归泛化 Transformer 用于图像超分辨率
Zheng Chen、Yulun Zhang、Jinjin Gu、Linghe Kong和Xiaokang Yang,"用于图像超分辨率的递归泛化 Transformer",ICLR,2024
[论文] [arXiv] [补充材料] [可视化结果] [预训练模型]
🔥🔥🔥 新闻
- 2024-02-04: 代码和预训练模型已发布。🎊🎊🎊
- 2023-09-29: 本仓库已发布。
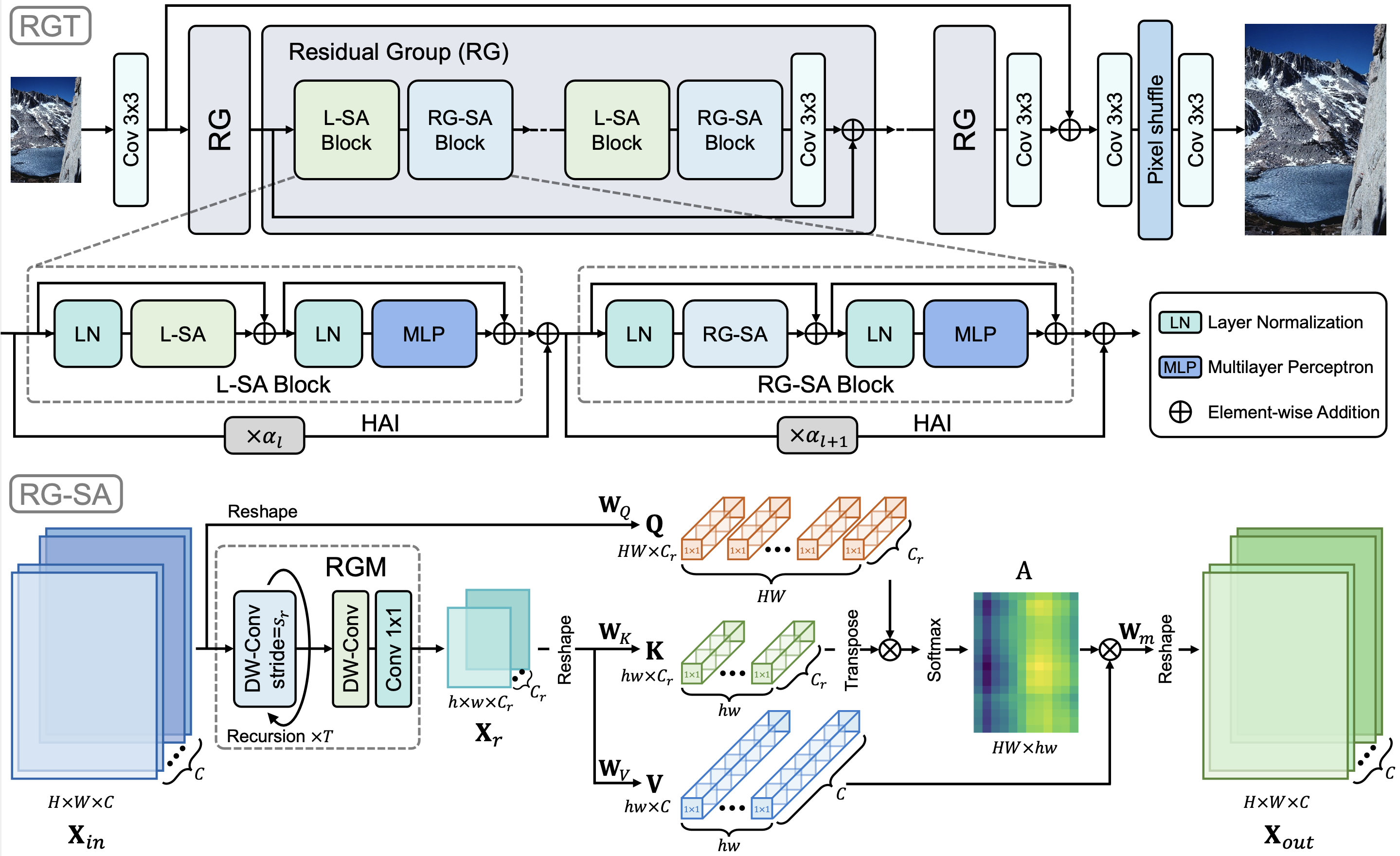
摘要: Transformer 架构在图像超分辨率(SR)任务中表现出了卓越的性能。由于 Transformer 中自注意力(SA)的二次计算复杂度,现有方法倾向于在局部区域采用 SA 以减少开销。然而,局部设计限制了全局上下文的利用,而这对于准确的图像重建至关重要。在本工作中,我们提出了用于图像 SR 的递归泛化 Transformer (RGT),它可以捕获全局空间信息并适用于高分辨率图像。具体来说,我们提出了递归泛化自注意力(RG-SA)。它递归地将输入特征聚合成具有代表性的特征图,然后利用交叉注意力提取全局信息。同时,注意力矩阵($query$、$key$ 和 $value$)的通道维度进一步缩放以减少通道域中的冗余。此外,我们将 RG-SA 与局部自注意力相结合以增强全局上下文的利用,并提出了混合自适应集成(HAI)用于模块集成。HAI 允许不同层级(局部或全局)特征之间的直接有效融合。大量实验表明,我们的 RGT 在定量和定性方面都优于最近的最先进方法。










⚙️ 依赖
- Python 3.8
- PyTorch 1.9.0
- NVIDIA GPU + CUDA
# 克隆 GitHub 仓库并进入默认目录 'RGT'。
git clone https://github.com/zhengchen1999/RGT.git
conda create -n RGT python=3.8
conda activate RGT
pip install -r requirements.txt -f https://download.pytorch.org/whl/torch_stable.html
python setup.py develop
⚒️ 待办事项
- 发布代码和预训练模型
🔗 目录
🖨️ 数据集
使用的训练和测试集可以按以下方式下载:
| 训练集 | 测试集 | 可视化结果 |
|---|---|---|
| DIV2K (800张训练图像,100张验证图像) + Flickr2K (2650张图像) [完整训练数据集 DF2K:Google Drive / 百度网盘] | Set5 + Set14 + BSD100 + Urban100 + Manga109 [完整测试数据集:Google Drive / 百度网盘] | Google Drive / 百度网盘 |
下载训练和测试数据集并将它们放入 datasets/ 的相应文件夹中。有关目录结构的详细信息,请参见 datasets。
📦 模型
| 方法 | 参数量 (M) | FLOPs (G) | PSNR (dB) | SSIM | 模型库 | 可视化结果 |
|---|---|---|---|---|---|---|
| RGT-S | 10.20 | 193.08 | 27.89 | 0.8347 | Google Drive / 百度网盘 | Google Drive / 百度网盘 |
| RGT | 13.37 | 251.07 | 27.98 | 0.8369 | Google Drive / 百度网盘 | Google Drive / 百度网盘 |
性能在 Urban100 (x4) 上报告。FLOPs 的输出尺寸为 3×512×512。
🔧 训练
-
下载训练(DF2K,已处理)和测试(Set5、Set14、BSD100、Urban100、Manga109,已处理)数据集,将它们放在
datasets/中。 -
运行以下脚本。训练配置在
options/train/中。
# RGT-S,输入=64x64,4个GPU
python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_RGT_S_x2.yml --launcher pytorch
python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_RGT_S_x3.yml --launcher pytorch
python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_RGT_S_x4.yml --launcher pytorch
# RGT,输入=64x64,4个GPU
python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_RGT_x2.yml --launcher pytorch
python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_RGT_x3.yml --launcher pytorch
python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/train/train_RGT_x4.yml --launcher pytorch
训练实验位于experiments/目录中。
🔨 测试
🌗 测试带有高分辨率图像的图片
-
下载预训练的模型并将它们放在
experiments/pretrained_models/目录中。我们提供了图像超分辨率的预训练模型:RGT-S和RGT(x2、x3、x4)。
-
下载测试(Set5、Set14、BSD100、Urban100、Manga109)数据集,将它们放在
datasets/目录中。 -
运行以下脚本。测试配置在
options/test/目录中(例如,test_RGT_x2.yml)。注1:您可以在YML文件中设置
use_chop: True(默认为False)以对图像进行分块测试。# 不使用自集成 # RGT-S,复现论文表2中的结果 python basicsr/test.py -opt options/test/test_RGT_S_x2.yml python basicsr/test.py -opt options/test/test_RGT_S_x3.yml python basicsr/test.py -opt options/test/test_RGT_S_x4.yml # RGT,复现论文表2中的结果 python basicsr/test.py -opt options/test/test_RGT_x2.yml python basicsr/test.py -opt options/test/test_RGT_x3.yml python basicsr/test.py -opt options/test/test_RGT_x4.yml -
输出结果在
results/目录中。
🌓 测试没有高分辨率图像的图片
-
下载预训练的模型并将它们放在
experiments/pretrained_models/目录中。我们提供了图像超分辨率的预训练模型:RGT-S和RGT(x2、x3、x4)。
-
将您的数据集(单个低分辨率图像)放在
datasets/single目录中。该文件夹中已包含一些测试图像。 -
运行以下脚本。测试配置在
options/test/目录中(例如,test_single_x2.yml)。注1:默认模型是RGT。您可以通过修改YML文件来使用其他模型,如RGT-S。
注2:您可以在YML文件中设置
use_chop: True(默认为False)以对图像进行分块测试。# 在您的数据集上测试 python basicsr/test.py -opt options/test/test_single_x2.yml python basicsr/test.py -opt options/test/test_single_x3.yml python basicsr/test.py -opt options/test/test_single_x4.yml -
输出结果在
results/目录中。
🔎 结果
我们达到了最先进的性能。详细结果可以在论文中找到。
📎 引用
如果您在研究或工作中发现代码有帮助,请引用以下论文。
@inproceedings{chen2024recursive,
title={Recursive Generalization Transformer for Image Super-Resolution},
author={Chen, Zheng and Zhang, Yulun and Gu, Jinjin and Kong, Linghe and Yang, Xiaokang},
booktitle={ICLR},
year={2024}
}
💡 致谢
本代码基于BasicSR构建。











