
RKNN-LLM简介
RKNN-LLM是瑞芯微近期推出的大语言模型(LLM)软件栈,旨在帮助用户快速将AI模型部署到瑞芯微芯片上。该解决方案为用户提供了一套完整的工具链,包括模型转换、量化、推理等功能,大大简化了在瑞芯微AI芯片上部署和运行LLM的过程。
系统架构
RKNN-LLM的整体架构如下图所示:
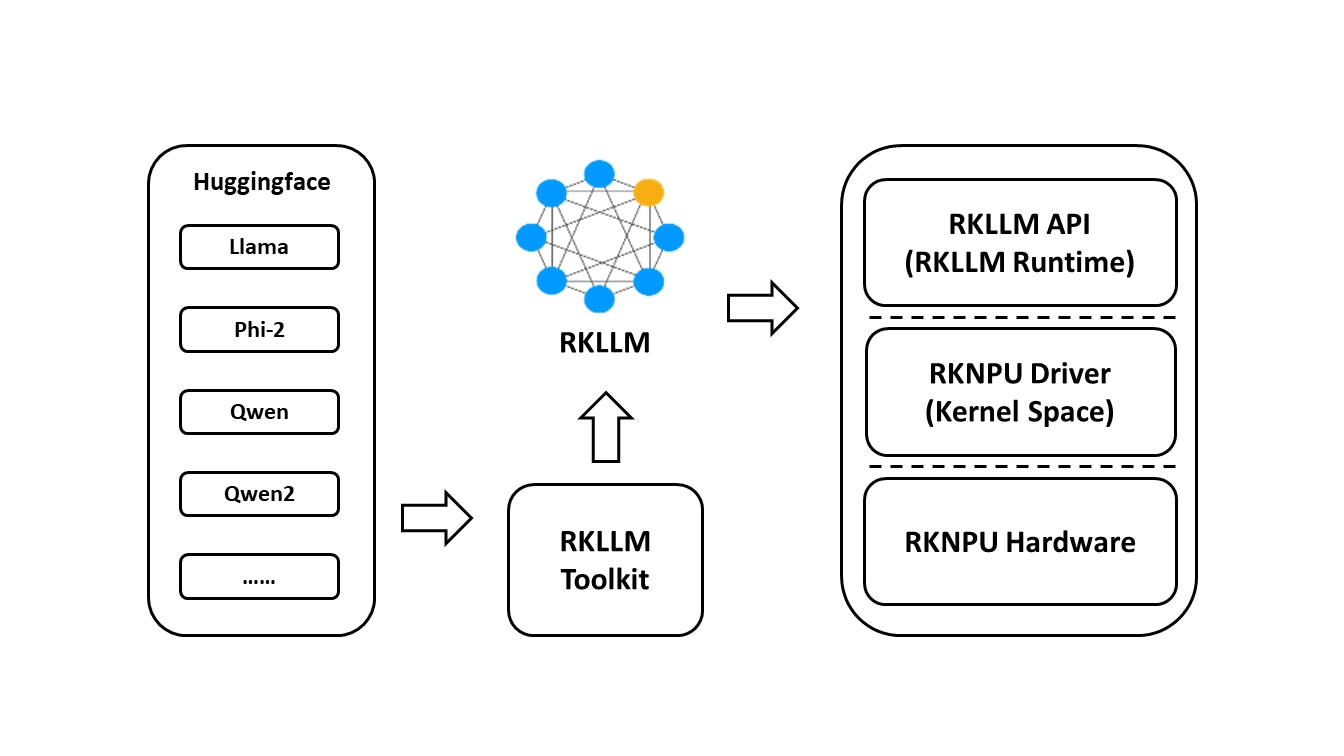
该架构主要包含以下几个关键组件:
-
RKLLM-Toolkit: 在PC端运行的软件开发工具包,用于执行模型转换和量化。
-
RKLLM Runtime: 为瑞芯微NPU平台提供C/C++编程接口,帮助用户部署RKLLM模型并加速LLM应用的实现。
-
RKNPU内核驱动: 负责与NPU硬件进行交互,已开源并可在瑞芯微内核代码中找到。
使用RKNN-LLM时,用户需要首先在PC上运行RKLLM-Toolkit工具,将训练好的模型转换为RKLLM格式的模型。然后,在开发板上使用RKLLM C API进行推理。
支持的平台
目前,RKNN-LLM支持以下瑞芯微芯片平台:
- RK3588系列
- RK3576系列
这两个系列芯片都集成了高性能的NPU,非常适合运行大语言模型等AI应用。
支持的模型
RKNN-LLM目前支持多种主流的大语言模型,包括:
- TinyLLAMA 1.1B
- Qwen 1.8B
- Qwen2 0.5B
- Phi-2 2.7B
- Phi-3 3.8B
- ChatGLM3 6B
- Gemma 2B
- InternLM2 1.8B
- MiniCPM 2B
这些模型覆盖了从0.5B到6B不同参数规模,可以满足不同场景下的需求。用户可以根据自己的应用需求和硬件资源选择合适的模型。
主要功能特性
RKNN-LLM具有以下主要功能和特性:
-
模型转换与量化 RKLLM-Toolkit可以将原始的LLM模型转换为适合在瑞芯微NPU上运行的格式,并进行量化以提高性能。
-
高效推理 RKLLM Runtime针对瑞芯微NPU进行了优化,可以实现高效的LLM推理。
-
内存优化 通过优化模型转换和推理过程中的内存占用,降低了系统资源需求。
-
性能提升 增加了预填充(prefill)速度,减少了初始化时间,提高了整体推理性能。
-
量化精度提升 改进了量化算法,提高了量化后模型的精度。
-
服务器调用 新增了服务器调用接口,方便集成到更大的系统中。
-
推理中断 添加了推理中断接口,允许用户在需要时暂停或终止推理过程。
-
详细输出 在返回值中增加了logprob和token_id信息,为用户提供更多的模型输出细节。
使用指南
要使用RKNN-LLM,用户需要按照以下步骤进行:
-
下载SDK 用户可以从RKLLM_SDK下载所有必要的包、Docker镜像、示例、文档和平台工具。下载密码为:rkllm。
-
模型转换 使用RKLLM-Toolkit在PC上将原始LLM模型转换为RKLLM格式。
-
部署到开发板 将转换后的模型部署到搭载RK3588或RK3576系列芯片的开发板上。
-
编写应用程序 使用RKLLM Runtime提供的C/C++ API编写应用程序,实现模型的加载和推理。
-
运行和优化 在开发板上运行应用程序,并根据需要进行性能优化。
与RKNN Toolkit2的关系
RKNN-LLM专注于大语言模型的部署,而对于其他类型的AI模型,瑞芯微还提供了RKNN Toolkit2。用户可以根据自己的需求选择合适的工具:
- 对于LLM部署,使用RKNN-LLM
- 对于其他AI模型部署,使用RKNN Toolkit2
最新更新
RKNN-LLM的最新版本(v1.0.1)带来了多项重要更新:
- 优化了模型转换和推理的内存占用
- 提高了预填充速度和整体推理性能
- 改进了量化精度
- 新增了对Gemma、ChatGLM3、MiniCPM、InternLM2和Phi-3等模型的支持
- 添加了服务器调用和推理中断接口
- 在返回值中增加了logprob和token_id信息
这些更新进一步提升了RKNN-LLM的性能和功能,为用户提供了更好的开发体验。
结语
RKNN-LLM为在瑞芯微AI芯片上部署和运行大语言模型提供了一个强大而灵活的解决方案。通过提供全面的工具链和优化的运行时库,它大大简化了LLM的部署过程,同时保证了高效的推理性能。随着AI技术的不断发展和边缘计算需求的增长,RKNN-LLM将在智能设备、机器人、车载系统等多个领域发挥重要作用,推动AI应用的普及和创新。
对于开发者和企业来说,RKNN-LLM提供了一个绝佳的机会,可以快速将先进的大语言模型集成到基于瑞芯微芯片的产品中,从而创造出更智能、更有价值的应用和服务。随着RKNN-LLM的不断完善和更新,我们可以期待看到更多基于瑞芯微平台的创新AI应用涌现。









