
引言
在人工智能和自然语言处理领域,语言模型的训练方法一直是研究的热点。近期,MetaAI提出了一种名为"自我奖励语言模型"(Self-Rewarding Language Model)的创新训练框架,引起了学术界和工业界的广泛关注。本文将深入探讨这一突破性技术,分析其工作原理、优势以及潜在的应用前景。
什么是自我奖励语言模型?
自我奖励语言模型是MetaAI研究人员在2024年初提出的一种新型语言模型训练方法。这一方法的核心思想是让语言模型在训练过程中自主生成奖励信号,从而实现自我优化和持续学习。
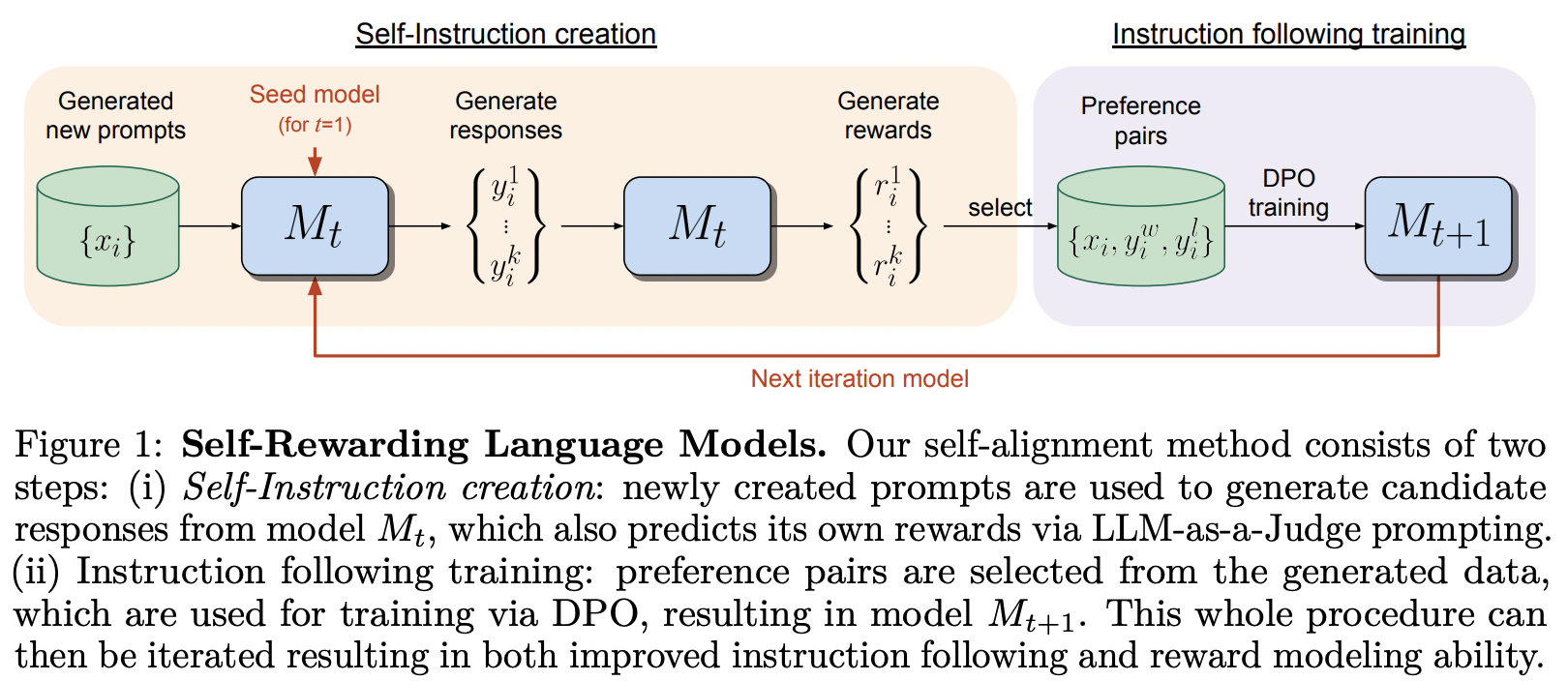
如上图所示,自我奖励语言模型的训练过程主要包括以下几个步骤:
- 模型生成初始输出
- 模型自我评估输出质量
- 根据评估结果生成奖励信号
- 利用奖励信号优化模型参数
这种自我闭环的训练方式使得模型能够不断提升自身的生成能力,而无需大量人工标注的训练数据。
自我奖励语言模型的优势
与传统的语言模型训练方法相比,自我奖励语言模型具有以下几个显著优势:
-
降低对人工标注数据的依赖: 通过自我生成奖励信号,该方法大大减少了对大规模人工标注数据的需求,这在资源有限的情况下尤为重要。
-
持续学习能力: 模型可以在训练过程中不断自我优化,理论上可以实现无限制的能力提升。
-
个性化定制: 由于模型可以根据自身的评估标准进行优化,因此可以更容易地适应特定领域或任务的需求。
-
潜在的超越人类表现: 自我奖励机制使得模型有可能在某些任务上达到甚至超越人类水平的表现。
PyTorch实现: self-rewarding-lm-pytorch
为了推动这一创新技术的研究和应用,GitHub用户lucidrains开发了一个名为self-rewarding-lm-pytorch的开源项目,实现了自我奖励语言模型的PyTorch版本。这个项目为研究人员和开发者提供了一个便捷的工具,可以快速实验和改进自我奖励语言模型。
主要特性
-
灵活的训练配置: 项目支持多种训练配置,包括SFT(Supervised Fine-Tuning)、SPIN(Self-Play Improvement)、DPO(Direct Preference Optimization)等。
-
易于使用的API: 提供了简洁的API,使用户能够轻松地构建和训练自我奖励语言模型。
-
支持自定义奖励函数: 允许用户定义自己的奖励生成逻辑,以适应不同的应用场景。
-
兼容性: 与主流的Transformer模型架构兼容,可以轻松集成到现有的项目中。
使用示例
以下是一个简单的使用示例,展示了如何使用self-rewarding-lm-pytorch库来训练一个自我奖励语言模型:
import torch
from self_rewarding_lm_pytorch import SelfRewardingTrainer, create_mock_dataset
from x_transformers import TransformerWrapper, Decoder
# 创建一个简单的Transformer模型
transformer = TransformerWrapper(
num_tokens = 256,
max_seq_len = 1024,
attn_layers = Decoder(
dim = 512,
depth = 1,
heads = 8
)
)
# 创建模拟数据集
sft_dataset = create_mock_dataset(100, lambda: (torch.randint(0, 256, (256,)), torch.tensor(1)))
prompt_dataset = create_mock_dataset(100, lambda: 'mock prompt')
# 初始化训练器
trainer = SelfRewardingTrainer(
transformer,
finetune_configs = dict(
train_sft_dataset = sft_dataset,
self_reward_prompt_dataset = prompt_dataset,
dpo_num_train_steps = 1000
)
)
# 开始训练
trainer(overwrite_checkpoints = True)
这个例子展示了如何创建一个简单的Transformer模型,并使用SelfRewardingTrainer来训练它。通过配置不同的训练参数,用户可以灵活地控制训练过程。
未来展望与挑战
自我奖励语言模型无疑是一个极具潜力的研究方向,但同时也面临着一些挑战:
-
奖励函数的设计: 如何设计一个合适的奖励函数,使其能够准确反映输出质量,是一个关键问题。
-
计算资源需求: 自我奖励机制可能会增加训练的计算复杂度,如何在有限的计算资源下实现高效训练是一个重要课题。
-
模型稳定性: 自我奖励可能导致模型陷入局部最优或产生不稳定的行为,如何保证模型的稳定性和可靠性需要进一步研究。
-
伦理考量: 自主学习的模型可能会产生意料之外的行为,如何确保模型的输出符合伦理标准是一个值得关注的问题。
结语
自我奖励语言模型代表了语言模型训练的一个新方向,它有望推动人工智能向着更高水平的自主学习和持续进化迈进。虽然还存在一些挑战,但通过开源项目如self-rewarding-lm-pytorch的努力,我们相信这一技术将会在未来得到更广泛的应用和发展。
研究人员和开发者可以通过参与self-rewarding-lm-pytorch项目,为这一创新技术的发展贡献力量。无论是提出新的想法、改进代码,还是分享使用经验,每一份贡献都可能推动自我奖励语言模型向前迈进一步。
随着技术的不断成熟和完善,我们有理由期待自我奖励语言模型在自然语言处理、人机交互、智能助手等多个领域带来革命性的变革。让我们共同期待这一激动人心的技术发展征程! 🚀🤖💡









