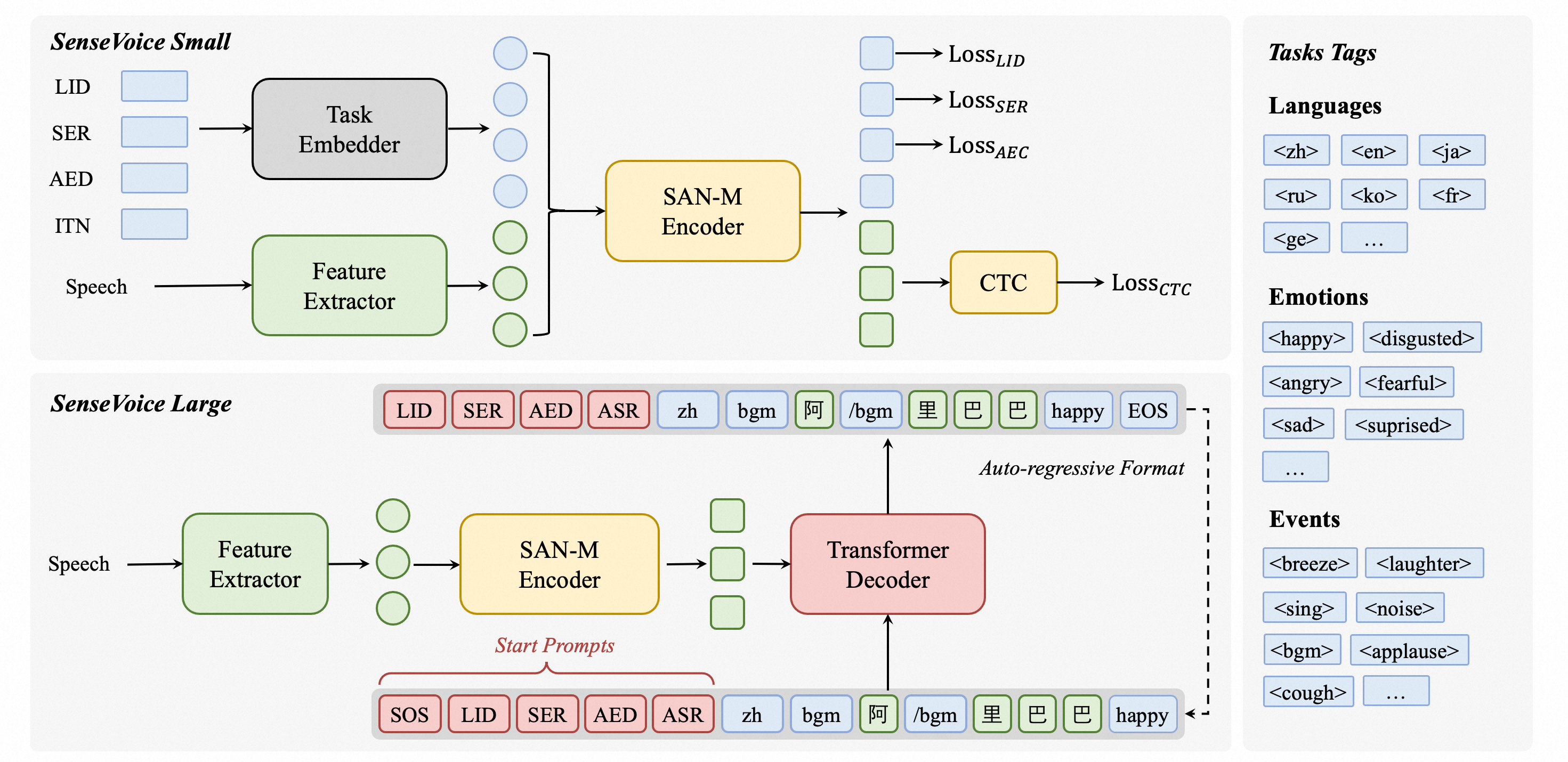
SenseVoice简介
SenseVoice是一个多功能的语音理解基础模型,具有以下主要特点:
- 多语种语音识别:训练数据超过40万小时,支持50多种语言,识别性能超过Whisper模型。
- 丰富的转写功能:具有出色的情感识别能力,支持检测背景音乐、掌声、笑声、哭声等多种人机交互事件。
- 高效推理:SenseVoice-Small模型采用非自回归端到端框架,推理延迟极低,处理10秒音频仅需70毫秒,比Whisper-Large快15倍。
- 便捷微调:提供便捷的微调脚本和策略,方便用户解决长尾样本问题。
- 服务部署:提供服务部署流程,支持多并发请求,客户端语言包括Python、C++、HTML、Java、C#等。
学习资源
代码仓库
模型下载
- ModelScope: https://www.modelscope.cn/models/iic/SenseVoiceSmall
- Hugging Face: https://huggingface.co/FunAudioLLM/SenseVoiceSmall
在线Demo
- ModelScope: https://www.modelscope.cn/studios/iic/SenseVoice
- Hugging Face: https://huggingface.co/spaces/FunAudioLLM/SenseVoice
相关工具包
- FunASR: https://github.com/modelscope/FunASR
- funasr-onnx: https://pypi.org/project/funasr-onnx/
- funasr-torch: https://pypi.org/project/funasr-torch/
使用教程
详细的使用教程可以参考GitHub仓库中的README文档。其中包括:
- 模型推理
- 模型导出(ONNX和Libtorch)
- 服务部署
- 模型微调
社区交流
如果在使用过程中遇到问题,可以通过以下方式寻求帮助:
- 在GitHub页面直接提Issue
- 扫描README中的钉钉群二维码加入社区群
相关项目
-
CosyVoice: 用于自然语音生成的模型,支持多语言、音色和情感控制。
-
SenseVoice.cpp: 基于GGML的纯C/C++推理实现,支持3-bit、4-bit、5-bit、8-bit量化等,无第三方依赖。
通过以上资源,相信读者可以快速入门SenseVoice项目,并根据自己的需求进行更深入的学习和应用开发。如果您对语音理解和生成感兴趣,SenseVoice无疑是一个值得关注和尝试的开源项目。