
Silero Models简介
Silero Models是一个开源的语音技术工具包,提供了预训练的企业级语音识别(STT)和语音合成(TTS)模型。它的主要特点包括:
- 使用简单,一行代码即可完成语音识别或合成
- 模型质量高,可与Google等大公司的语音服务媲美
- 无需GPU,在CPU上也能快速运行
- 支持多种语言,包括英语、俄语、德语、西班牙语等
- 模型体积小,依赖少,易于部署
Silero Models的目标是让高质量的语音技术变得简单易用,让更多开发者能够方便地将语音功能集成到自己的应用中。
语音识别(STT)模型
Silero Models提供了多种语言的语音识别模型:
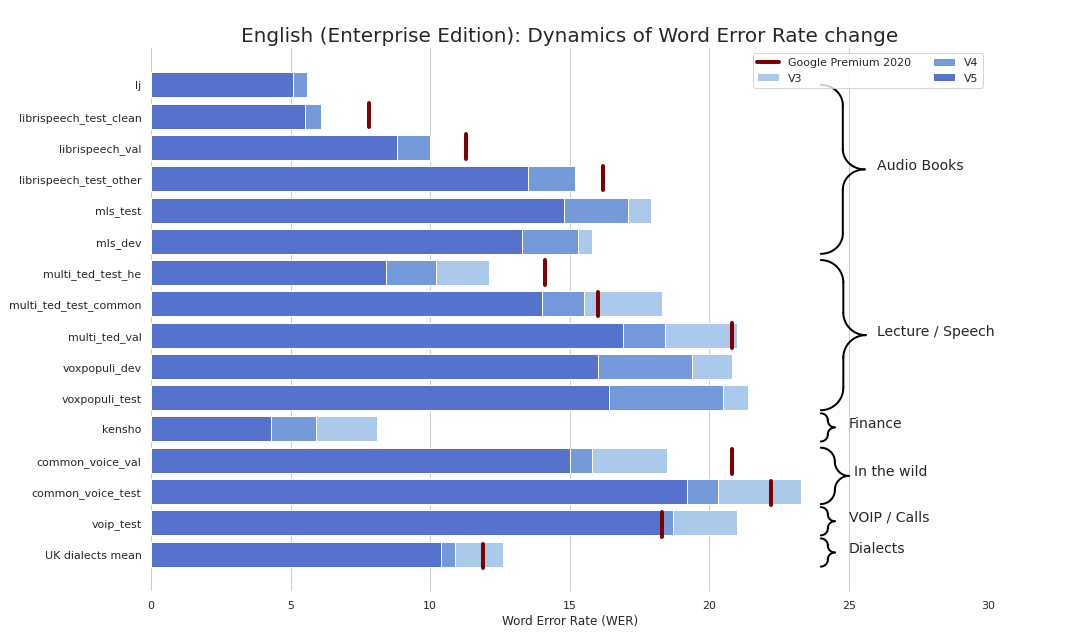
- 英语(en_v6): 最新的英语模型,支持PyTorch和ONNX格式
- 德语(de_v4): 德语模型,支持PyTorch和ONNX格式
- 西班牙语(es_v1): 西班牙语模型,支持PyTorch和ONNX格式
- 乌克兰语(ua_v3): 乌克兰语模型,支持PyTorch和ONNX格式
这些模型都经过了量化处理,可以在CPU上快速运行。使用方法非常简单,只需几行代码即可完成语音识别:
import torch
model, decoder, utils = torch.hub.load(repo_or_dir='snakers4/silero-models',
model='silero_stt',
language='en')
audio_path = 'audio.wav'
audio = utils.read_audio(audio_path)
text = model(audio)
print(decoder(text[0]))
语音合成(TTS)模型
Silero Models的TTS模型同样支持多种语言:
- 俄语(v4_ru): 支持多个说话人,包括aidar、baya、kseniya等
- 英语(v3_en): 支持100多个说话人
- 德语(v3_de): 支持多个说话人
- 西班牙语(v3_es): 支持3个说话人
- 法语(v3_fr): 支持6个说话人
TTS模型的使用也非常简单:
import torch
model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models',
model='silero_tts',
language='en',
speaker='en_0')
audio = model.apply_tts(text=example_text,
speaker='en_0',
sample_rate=48000)
TTS模型支持SSML标记语言,可以更精细地控制合成语音的效果。
文本增强模型
除了语音识别和合成,Silero Models还提供了文本增强模型,可以为文本添加标点符号和大小写。该模型支持俄语、英语、德语和西班牙语,可以显著提高文本的可读性。
使用方法
Silero Models提供了多种使用方式:
- 通过PyTorch Hub直接加载
- 通过pip安装silero包
- 手动下载模型文件
对于大多数用户来说,通过PyTorch Hub加载是最简单的方式。Silero Models还提供了详细的使用示例和Colab notebook,方便用户快速上手。
总结
Silero Models为开发者提供了一套简单易用、高质量的语音技术工具。无论是语音识别、语音合成还是文本增强,都可以通过几行代码轻松实现。这个开源项目大大降低了语音技术的使用门槛,为更多应用添加语音功能提供了可能。
如果您对语音技术感兴趣,不妨尝试一下Silero Models,相信它能为您的项目带来新的可能性。










