
skweak:让NLP的弱监督学习变得简单易用
在许多实际的自然语言处理(NLP)场景中,标注数据仍然是一种稀缺资源。特别是当我们处理资源匮乏的语言或文本领域,或者使用没有预先存在数据集的特定任务标签时,这一问题尤为突出。通常情况下,唯一可行的选择就是手动收集和标注文本,这不仅耗时而且昂贵。
为了解决这一棘手问题,一个名为skweak的创新工具应运而生。skweak是一个基于Python的软件工具包,它为NLP任务提供了一个具体而有效的弱监督学习解决方案。
skweak的核心理念
skweak的核心理念非常简单:不再手动标注文本,而是定义一组"标注函数"来自动标注文档,然后将这些函数的结果进行聚合,从而得到语料库的标注版本。这种方法不仅大大减少了人工标注的工作量,还能利用各种知识源来提高标注质量。
灵活多样的标注函数
skweak支持多种形式的标注函数,包括:
- 特定领域的启发式规则(如模式匹配)
- 基于大型词典的词表
- 机器学习模型
- 众包工人的标注
这种灵活性使得开发人员可以根据具体任务和领域的需求,设计最适合的标注策略。
智能聚合机制
skweak采用了一种统计模型来聚合各个标注函数的结果。这个模型能够通过比较不同函数的预测结果,自动估计每个标注函数的相对准确率和可能存在的混淆。这种智能聚合机制可以有效地解决不同标注函数之间可能存在的冲突,从而得到更加可靠的最终标注。
广泛的应用场景
skweak可以应用于序列标注和文本分类等多种NLP任务。它提供了一个完整的API,使得创建、应用和聚合标注函数只需几行代码就能完成。此外,skweak还与流行的NLP库SpaCy紧密集成,可以轻松地融入现有的NLP流程中。
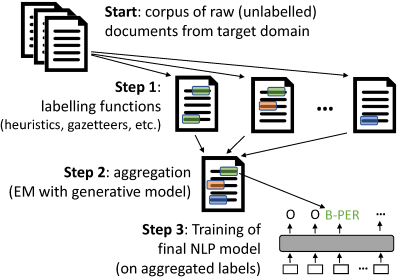
使用skweak的基本步骤
-
准备数据: 首先,你需要从你的文本领域获取原始(未标注)数据。skweak基于SpaCy构建,使用SpaCy的
Doc对象,因此你需要先将文档转换为Doc对象。 -
定义标注函数: 接下来,定义一系列标注函数,这些函数将对文档进行处理并用标签标注跨度。标注函数可以来自启发式规则、词表、机器学习模型等。
-
聚合结果: 将标注函数应用到语料库后,需要聚合它们的结果,以获得单一的标注层。skweak使用一个生成模型来自动估计每个标注函数的相对准确率和可能的混淆。
-
训练最终模型: 基于聚合的标签,你可以训练最终的机器学习模型。这个标注语料库概率性地聚合了所有标注函数的输出,你可以使用它来估计任何类型的机器学习模型。
快速上手示例
以下是一个简单的示例,展示了如何使用skweak定义三个标注函数并应用于单个文档:
import spacy, re
from skweak import heuristics, gazetteers, generative, utils
# LF 1: 检测MONEY实体的启发式规则
def money_detector(doc):
for tok in doc[1:]:
if tok.text[0].isdigit() and tok.nbor(-1).is_currency:
yield tok.i-1, tok.i+1, "MONEY"
lf1 = heuristics.FunctionAnnotator("money", money_detector)
# LF 2: 使用正则表达式检测年份
lf2= heuristics.TokenConstraintAnnotator("years", lambda tok: re.match("(19|20)\d{2}$",
tok.text), "DATE")
# LF 3: 使用包含几个名字的词表
NAMES = [("Barack", "Obama"), ("Donald", "Trump"), ("Joe", "Biden")]
trie = gazetteers.Trie(NAMES)
lf3 = gazetteers.GazetteerAnnotator("presidents", {"PERSON":trie})
# 创建一个语料库(这里只有一个文本)
nlp = spacy.load("en_core_web_sm")
doc = nlp("Donald Trump paid $750 in federal income taxes in 2016")
# 应用标注函数
doc = lf3(lf2(lf1(doc)))
# 创建并拟合HMM聚合模型
hmm = generative.HMM("hmm", ["PERSON", "DATE", "MONEY"])
hmm.fit([doc]*10)
# 拟合后,我们简单地应用模型来聚合所有函数
doc = hmm(doc)
# 然后我们可以在Jupyter中可视化最终结果
utils.display_entities(doc, "hmm")
这个例子展示了skweak的基本用法,但要充分发挥skweak的潜力,你需要更多的标注函数和更大的语料库。这样模型才能更好地估计每个标注函数的相对准确率。
skweak的优势
-
减少人工标注: skweak通过自动化标注过程,大大减少了手动标注的需求,从而节省时间和成本。
-
灵活性: 支持多种类型的标注函数,可以根据具体任务和领域定制标注策略。
-
智能聚合: 使用统计模型自动估计标注函数的准确率,有效处理冲突。
-
易于集成: 与SpaCy紧密集成,可以轻松融入现有NLP流程。
-
适用性广: 可用于序列标注和文本分类等多种NLP任务。
-
简单易用: 提供简洁的API,只需几行代码即可完成复杂的标注任务。
安装和依赖
skweak可以通过pip轻松安装:
pip install skweak
主要依赖包括:
- spacy >= 3.0.0
- hmmlearn >= 0.3.0
- pandas >= 0.23
- numpy >= 1.18
使用Python版本需要 >= 3.6。
结语
skweak为NLP开发人员提供了一个强大而灵活的工具,使得弱监督学习在自然语言处理任务中的应用变得简单易行。通过减少对大量手动标注数据的依赖,skweak可以显著加速NLP项目的开发周期,同时保持较高的模型性能。无论是处理资源匮乏的语言、特定领域的文本,还是没有现成数据集的新任务,skweak都能提供一个有效的解决方案。
随着NLP技术的不断发展和应用领域的不断拓展,像skweak这样的工具将在未来扮演越来越重要的角色,助力研究人员和开发者更高效地构建和优化NLP模型。尽管skweak目前已不再积极维护,但其核心理念和方法仍然具有重要的参考价值,相信会继续影响和启发NLP领域的创新。
📚 欢迎访问skweak的GitHub仓库以了解更多详情,并在您的下一个NLP项目中尝试使用skweak,体验弱监督学习带来的便利与效率提升。









