
 访问官网
访问官网 Github
Github 文档
文档 论文
论文skweak: NLP的弱监督





在许多实际NLP场景中,标记数据仍然是一种稀缺资源。特别是在处理资源匮乏的语言(或文本领域)时,或者在使用没有预先存在数据集的特定任务标签时,情况更是如此。唯一可用的选择通常是手动收集和标注文本,这既昂贵又耗时。
skweak(发音为/skwi:k/)是一个基于Python的软件工具包,它使用弱监督为这个问题提供了一个具体的解决方案。skweak的构建围绕一个非常简单的想法:我们不是手动标注文本,而是定义一组_标记函数_来自动标记我们的文档,然后_聚合_它们的结果以获得语料库的标记版本。
标记函数可以采取各种形式,如特定领域的启发式方法(如模式匹配规则)、词表(基于大型词典)、机器学习模型,甚至众包工作者的标注。聚合是通过一个统计模型完成的,该模型通过比较各个标记函数的预测结果,自动估计每个标记函数的相对准确性(和混淆)。
skweak可以应用于序列标注和文本分类,并提供了一个完整的API,只需几行代码就可以创建、应用和聚合标记函数。该工具包还与SpaCy紧密集成,这使得将其纳入现有的NLP流程变得容易。来试试吧!
完整论文:
Pierre Lison, Jeremy Barnes 和 Aliaksandr Hubin (2021), "skweak: 让NLP的弱监督变得简单", ACL 2021 (系统演示)。
文档和API: 关于如何使用skweak的详细信息,请参见Wiki。
依赖项
spacy>= 3.0.0hmmlearn>= 0.3.0pandas>= 0.23numpy>= 1.18
您还需要Python >= 3.6。
安装
安装skweak最简单的方法是通过pip:
pip install skweak
或者如果您想从仓库安装:
pip install --user git+https://github.com/NorskRegnesentral/skweak
上述安装只包括核心库(不包括examples中的额外示例)。
注意:一些示例和测试可能需要训练过的spaCy管道。这些可以使用以下语法自动下载(以en_core_web_sm管道为例):
python -m spacy download en_core_web_sm
基本概述
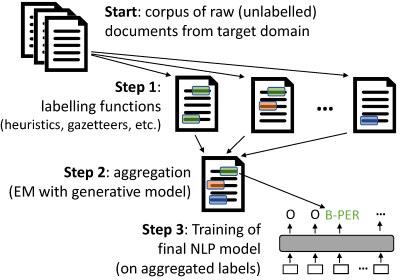
使用 `skweak` 进行弱监督包括以下步骤: - **开始**:首先,你需要来自文本领域的原始(未标记)数据。`skweak` 构建在 [SpaCy](http://www.spacy.io) 之上,并使用 Spacy 的 `Doc` 对象进行操作,所以你首先需要使用 SpaCy 将文档转换为 `Doc` 对象。 - **步骤 1**:然后,我们需要定义一系列标记函数,这些函数将处理这些文档并用标签标注文本段。这些标记函数可以来自启发式规则、词汇表、机器学习模型等。更多详情请参见。 - **步骤 2**:一旦标记函数被应用到你的语料库上,你需要_聚合_它们的结果,以获得单一的标注层(而不是来自标记函数的多个可能冲突的标注)。在 `skweak` 中,这是通过一个生成模型来完成的,该模型自动估计每个标记函数的相对准确性和可能的混淆。 - **步骤 3**:最后,基于这些聚合的标签,我们可以训练我们的最终模型。步骤 2 给我们提供了一个标记好的语料库,它(概率性地)聚合了所有标记函数的输出,你可以使用这些标记数据来估计任何类型的机器学习模型。你可以自由选择你喜欢的任何模型/框架。
快速入门
这里是一个最小示例,在单个文档上应用了三个标记函数(LFs):
import spacy, re
from skweak import heuristics, gazetteers, generative, utils
# LF 1:检测 MONEY 实体的启发式规则
def money_detector(doc):
for tok in doc[1:]:
if tok.text[0].isdigit() and tok.nbor(-1).is_currency:
yield tok.i-1, tok.i+1, "MONEY"
lf1 = heuristics.FunctionAnnotator("money", money_detector)
# LF 2:使用正则表达式检测年份
lf2= heuristics.TokenConstraintAnnotator("years", lambda tok: re.match("(19|20)\d{2}$",
tok.text), "DATE")
# LF 3:包含几个名字的词汇表
NAMES = [("Barack", "Obama"), ("Donald", "Trump"), ("Joe", "Biden")]
trie = gazetteers.Trie(NAMES)
lf3 = gazetteers.GazetteerAnnotator("presidents", {"PERSON":trie})
# 我们创建一个语料库(这里只有一个文本)
nlp = spacy.load("en_core_web_sm")
doc = nlp("Donald Trump paid $750 in federal income taxes in 2016")
# 应用标记函数
doc = lf3(lf2(lf1(doc)))
# 创建并拟合 HMM 聚合模型
hmm = generative.HMM("hmm", ["PERSON", "DATE", "MONEY"])
hmm.fit([doc]*10)
# 拟合后,我们只需应用模型来聚合所有函数
doc = hmm(doc)
# 然后我们可以可视化最终结果(在 Jupyter 中)
utils.display_entities(doc, "hmm")
显然,要充分利用 skweak,你需要的不仅仅是三个标记函数。更重要的是,你需要一个更大的语料库,包括尽可能多的来自你领域的文档,这样模型才能对每个标记函数的相对准确性进行良好的估计。
文档
请参阅 Wiki。
许可证
skweak 在 MIT 许可证下发布。
MIT 许可证是一个简短而简单的许可证,允许软件的商业和非商业使用。唯一的要求是保留版权和许可声明(参见文件 License)。许可的作品、修改和更大的作品可以在不同的条款下分发,无需提供源代码。
引用
请参阅描述该框架的论文:
Pierre Lison, Jeremy Barnes and Aliaksandr Hubin (2021), "skweak: Weak Supervision Made Easy for NLP", ACL 2021 (System demonstrations)。
@inproceedings{lison-etal-2021-skweak,
title = "skweak: Weak Supervision Made Easy for {NLP}",
author = "Lison, Pierre and
Barnes, Jeremy and
Hubin, Aliaksandr",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-demo.40",
doi = "10.18653/v1/2021.acl-demo.40",
pages = "337--346",
}











