图像到视频扩散模型中的条件图像泄露问题
近年来,扩散模型在图像到视频(I2V)生成任务中取得了显著进展。然而,这些模型的工作机制还未被完全理解。研究人员最近发现了I2V扩散模型(I2V-DMs)中一个被忽视但却很重要的问题 - 条件图像泄露。本文将深入探讨这一问题,并提出解决方案。
什么是条件图像泄露?
条件图像泄露指的是I2V-DMs在生成过程的前期阶段过度依赖输入的条件图像,而忽视了从噪声输入中预测干净视频的关键任务。这导致生成的视频缺乏动态感和生动的运动效果。
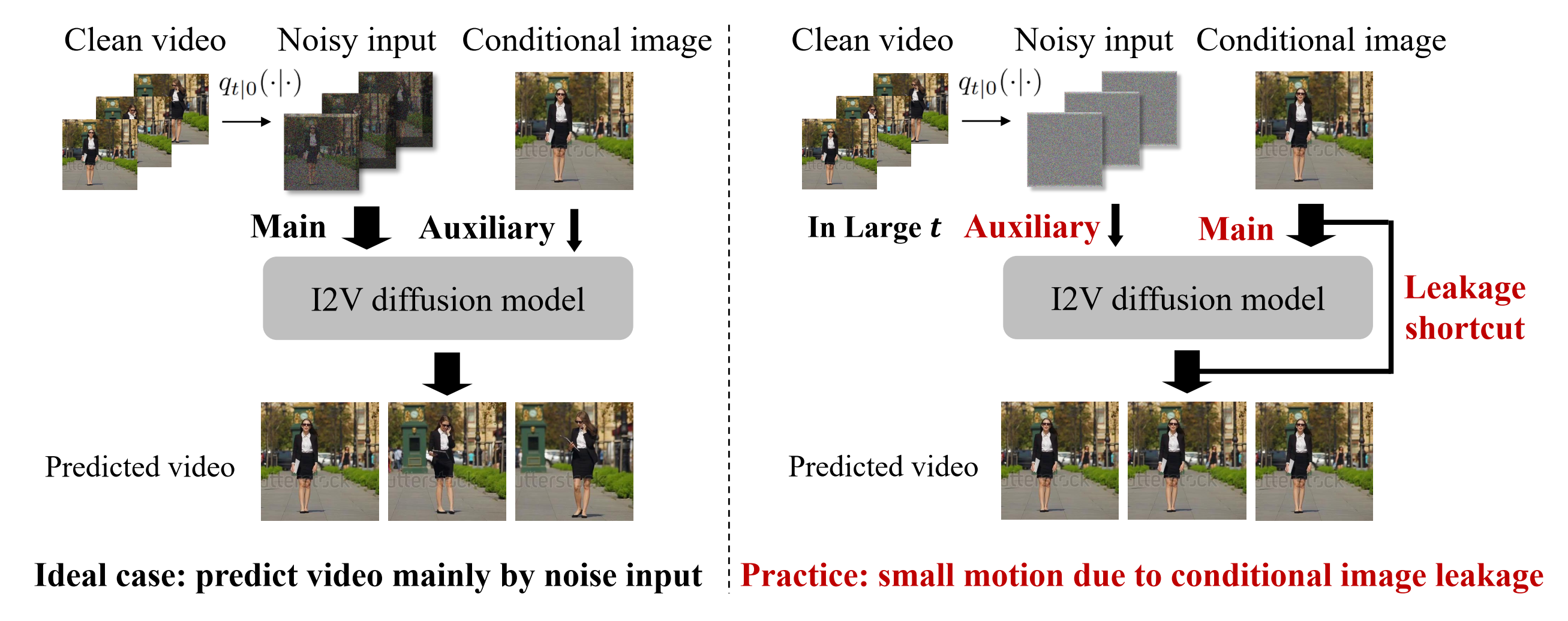
如上图所示,条件图像泄露会导致生成的视频帧与输入图像过于相似,缺乏变化。
解决方案
为了解决这一问题,研究人员提出了从推理和训练两个方面入手的即插即用策略:
-
推理策略
- 调整推理起始时间步 M
- 使用分析初始化(Analytic-Init)来初始化噪声分布
-
训练策略
- 调整最大噪声水平 beta_m
- 调整分布中心的指数 a
这些策略在多个主流I2V-DM模型上进行了验证,包括DynamiCrafter、SVD和VideoCrafter1等。
效果展示
以下是应用这些策略前后的效果对比:

可以看到,应用新策略后(右图),生成的视频动态感更强,运动更加自然流畅。
实现细节
研究人员提供了详细的代码实现和使用说明,主要包括:
- 环境配置
- 数据集准备
- 推理策略实现
- 训练策略实现
- 预训练模型下载
感兴趣的读者可以参考项目GitHub仓库获取更多技术细节。
结论与展望
本研究揭示了I2V扩散模型中一个重要但被忽视的问题,并提出了有效的解决方案。这不仅提升了生成视频的质量,也加深了我们对扩散模型工作机制的理解。
未来的研究方向可能包括:
- 进一步优化推理和训练策略
- 扩展到更多I2V模型架构
- 探索条件图像泄露问题在其他条件生成任务中的表现
总的来说,这项工作为提升视频生成质量和丰富性开辟了新的思路,有望推动相关技术在创意内容制作、视觉特效等领域的应用。
研究者们欢迎社区的反馈和贡献,共同推进这一激动人心的研究方向。如果您觉得这项工作有帮助,欢迎引用相关论文并关注后续研究进展。










