
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
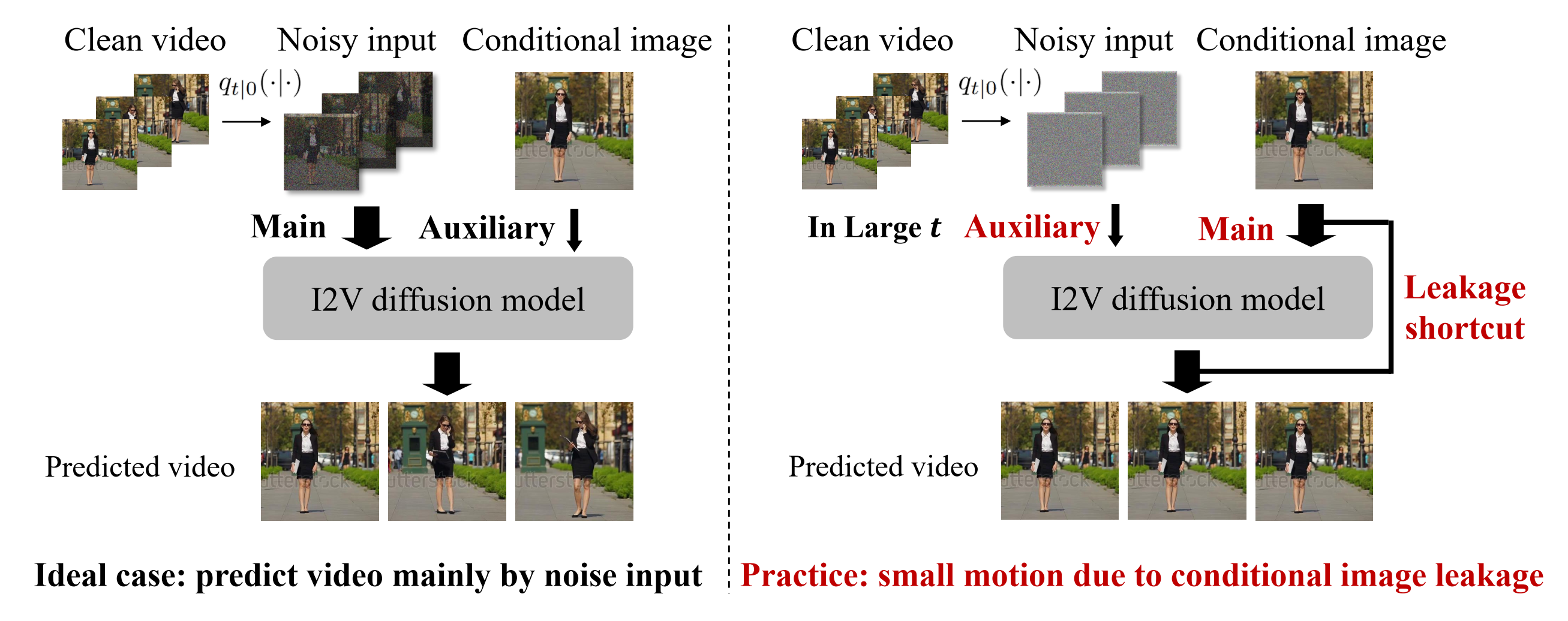
论文在图像到视频扩散模型中识别和解决条件图像泄露问题

🔆 概述
扩散模型在图像到视频(I2V)生成方面取得了实质性进展。然而,这些模型尚未被完全理解。在本文中,我们报告了I2V扩散模型(I2V-DMs)中一个重要但先前被忽视的问题,即条件图像泄露。I2V-DMs倾向于在较大的时间步长上过度依赖条件图像,忽视了从噪声输入预测清晰视频的关键任务,这导致生成的视频缺乏动态和生动的运动。我们进一步从推理和训练两个方面解决这一挑战,提出了相应的即插即用策略。这些策略在各种I2V-DMs上得到验证,包括DynamiCrafter、SVD和VideoCrafter1。
✅ 待办事项:
- [2024.06.25]:发布代码、模型和项目页面。
- [2024.08.11]:添加Animate-Anything和PIA的推理代码
- 发布无水印和其他分辨率的模型。
⚙️ 环境设置
我们的即插即用策略可应用于各种I2V-DMs,允许直接使用其原始环境。 例如,设置DynamiCrafter:
cd examples/DynamiCrafter
conda create -n dynamicrafter python=3.8.5
conda activate dynamicrafter
pip install -r requirements.txt
设置VideoCrafter1:
cd examples/VideoCrafter
conda create -n videocrafter python=3.8.5
conda activate videocrafter
pip install -r requirements.txt
设置SVD:
cd examples/SVD
conda create -n svd python=3.9.18
conda activate svd
pip install -r requirements.txt
设置Animate-Anything:
cd examples/animate-anything
conda create -n animation python=3.10
conda activate animation
pip install -r requirements.txt
设置PIA:
cd examples/PIA
conda env create -f pia.yml
conda activate pia
☀️ 数据集
从此处下载WebVid数据集,我们使用Webvid-2M子集。将.csv文件放在examples/dataset/results_2M_train.csv中,视频数据放在examples/dataset/中。我们使用原始数据,不进行任何过滤。
🧊 推理策略
我们克隆了DynamiCrafter和VideoCrafter1的仓库,并自行实现了SVD。我们在它们上应用了我们的即插即用策略。
🎒 初始噪声分布
| 模型 | 分辨率 | 初始噪声 |
|---|---|---|
| DynamiCrafter | 256x256 | 初始噪声 |
| DynamiCrafter | 320x512 | 初始噪声 |
| DynamiCrafter | 576x1024 | 初始噪声 |
| VideoCrafter | 256x256 | 初始噪声 |
| VideoCrafter | 320x512 | 初始噪声 |
| VideoCrafter | 576x1024 | 初始噪声 |
| SVD | 320 x 512 | 初始噪声 |
| SVD | 576 x 1024 | 初始噪声 |
😄 示例结果
| 模型 | 条件图像 | 标准推理 | + 我们的推理策略 |
| DynamiCrafter320x512 |

|

|

|
| VideoCrafter320x512 |

|

|

|
| SVD 576x1024 |

|

|

|
| Animate-Anything |

|

|

|
| PIA |
|

|

|
DynamiCrafter
- 从仓库下载原始DynamiCrafter检查点并将其放在
examples/DynamiCrafter/ckpt/original中,或者从这里下载我们的DynamiCrafter-CIL并将其放在examples/DynamiCrafter/ckpt/finetuned中。下载上表中的初始噪声并将其放在examples/DynamiCrafter/ckpt/中。 - 运行以下命令:
cd examples/DynamiCrafter
# 对于原始的320x512分辨率DynamiCrafter
sh inference_512.sh
# 对于我们320x512分辨率的DynamiCrafter-CIL
sh inference_CIL_512.sh
# 对于我们576x1024分辨率的DynamiCrafter-CIL
sh inference_CIL_1024.sh
inference.sh中与我们策略相关的参数解释如下:
M:起始时间步M。whether_analytic_init:表示是否使用解析初始化;0表示不应用,1表示应用analytic_init_path:如果应用解析初始化,则为初始化噪声均值和方差的路径
注意M=1000, whether_analytic_init=0是基线。
起始时间M的效果如下:
| 条件图像 | M=1.00T | M=0.94T | M=0.90T | M=0.86T | M=0.82T |

|

|

|

|

|

|
SVD
- 下载预训练的SVD模型并将其放在
examples/SVD/ckpt/pretrained/stable-video-diffusion-img2vid中。从这里下载我们的SVD-CIL并将其放在examples/SVD/ckpt/finetuned中。下载上表中的初始噪声并将它们放在examples/SVD/ckpt/中。 - 运行以下命令:
cd examples/SVD
# 对于原始SVD
sh inference.sh
# 对于320x512分辨率的SVD-CIL
sh inference_CIL_512.sh
推理的相关参数在examples/SVD/config/inference.yaml中设置,解释如下:
sigma_max:起始时间M。analytic_init_path:如果应用解析初始化,则为初始化噪声均值和方差的路径
VideoCrafter1
- 从仓库下载原始VideoCrafter检查点并将其放在
examples/VideoCrafter/ckpt/original中,或者从这里下载我们的VideoCrafter-CIL并将其放在examples/VideoCrafter/ckpt/finetuned中。下载上表中的初始噪声并将它们放在examples/VideoCrafter/ckpt中。 - 运行以下命令:
cd examples/VideoCrafter
# 对于原始的320x512分辨率VideoCrafter
sh inference_512.sh
# 对于320x512分辨率的VideoCrafter-CIL
sh inference_CIL_512.sh
inference.sh中与我们策略相关的参数解释如下:
M:起始时间Manalytic_init_path:如果应用解析初始化,则为初始化噪声均值和方差的路径
Animate-Anything
- 从仓库下载原始Animate-Anything检查点并将其放在
cond-image-leakage/examples/animate-anything/output/latent/animate_anything_512_v1.02中 - 运行以下命令:
cd cond-image-leakage/examples/animate-anything
python inference.py --config example/config/concert.yaml
cond-image-leakage/examples/PIA/example/config/base.yaml中与我们策略相关的参数解释如下:
noise_scheduler_kwargs.num_train_timesteps:起始时间M
PIA
- 按照
cond-image-leakage/examples/PIA/README.md中的说明从仓库下载原始Animate-Anything检查点并放置。 - 运行以下命令:
cd cond-image-leakage/examples/PIA
inference.sh中与我们策略相关的参数解释如下:
M:起始时间M
🔥 训练策略
与推理策略类似,我们基于DynamiCrafter、VideoCrafter1和SVD仓库对基线进行微调。
😄 示例结果
| 模型 | 条件图像 | 微调基线 | + 我们的训练策略 |
| DynamiCrafter |

|

|

|
| VideoCrafter |

|

|

|
| SVD |

|

|

|
DynamiCrafter
- 从仓库下载DynamiCrafter检查点,并将它们放在
examples/DynamiCrafter/ckpt/original中。 - 运行以下命令:
cd examples/DynamiCrafter
sh train.sh
train.sh中与我们策略相关的参数解释如下:
beta_m:最大噪声水平。a:分布中心的指数:$\mu(t)=2t^a-1$,其中$a > 0$。
beta_m的效果如下:
| 条件图像 | beta_m=25 | beta_m=100 | beta_m=700 |

|

|

|

|
a的效果如下:
| 条件图像 | a = 5.0 | a = 1.0 | a = 0.1 |
|
|
|

|

|
较低的a对应更动态的运动和较低的时间一致性和图像对齐。
SVD
- 从仓库下载SVD检查点,并将它们放在
examples/SVD/ckpt/pretrained/stable-video-diffusion-img2vid中; - 运行以下命令:
cd examples/SVD
sh train.sh
examples/SVD/config/train.yaml中与我们策略相关的参数解释如下:
beta_m:最大噪声水平。较高的beta_m对应更动态的运动和较低的时间一致性和图像对齐。a:分布中心的指数:$\mu(t)=2t^a-1$,其中$a > 0$。较低的$a$对应更动态的运动和较低的时间一致性和图像对齐。
请注意,原始SVD首先在条件图像上添加噪声,然后将其输入VAE。这里我们首先将条件图像输入VAE,然后在条件潜在表示上添加噪声。
VideoCrafter1
- 从仓库下载VideoCrafter检查点,并将它们放在
examples/VideoCrafter/original/ckpt/中。 - 运行以下命令:
cd examples/VideoCrafter
sh train.sh
train.sh中与我们策略相关的参数解释如下:
beta_m:最大噪声水平。较高的beta_m对应更动态的运动和较低的时间一致性和图像对齐。a:分布中心的指数:$\mu(t)=2t^a-1$,其中$a > 0$。较低的$a$对应更动态的运动和较低的时间一致性和图像对齐。
🎒 检查点
为了公平比较,朴素微调和我们的方法在相同的设置下进行训练。将来,我们会发布没有水印的模型。
| 模型 | 朴素微调 | 我们在Webvid上的方法 | 无水印 |
|---|---|---|---|
| DynamiCrafter | 320x512 | 320x512 | 320x512 576x1024 |
| SVD | 320x512 | 320x512 | |
| VideoCrafter1 | 320x512 | 320x512 |
😄 引用
如果您发现这个仓库有帮助,请按以下方式引用:
@article{zhao2024identifying,
title={Identifying and Solving Conditional Image Leakage in Image-to-Video Diffusion Model},
author={Zhao, Min and Zhu, Hongzhou and Xiang, Chendong and Zheng, Kaiwen and Li, Chongxuan and Zhu, Jun},
journal={arXiv preprint arXiv:2406.15735},
year={2024}
}
❤️ 致谢
此实现基于以下工作:











