
sparklyr简介
Apache Spark作为一个强大的大数据处理引擎,已经成为当今数据科学和大数据分析领域不可或缺的工具。然而,对于熟悉R语言的数据科学家来说,直接使用Spark可能存在一定的学习曲线。这就是sparklyr发挥作用的地方。sparklyr是一个由RStudio开发的R包,它为R用户提供了一个与Apache Spark进行交互的简洁而强大的接口。通过sparklyr,R用户可以轻松地利用Spark的分布式计算能力,同时保持在熟悉的R环境中工作。

sparklyr的主要特性
-
与Spark的无缝集成: sparklyr允许用户直接从R中连接到Spark集群,无论是本地Spark实例还是远程集群。
-
dplyr语法支持: 通过集成dplyr,sparklyr使得在Spark数据集上进行数据操作变得异常简单,R用户可以使用熟悉的dplyr语法来处理大规模数据。
-
机器学习支持: sparklyr提供了对Spark MLlib的访问,使得在Spark上进行机器学习变得轻而易举。
-
SQL查询: 用户可以直接在R中执行SQL查询,操作Spark中的数据。
-
数据导入导出: sparklyr支持多种数据格式的读写,如CSV、JSON和Parquet等。
-
扩展性: 开发者可以创建自定义扩展,以支持更多Spark功能。
安装和连接
要开始使用sparklyr,首先需要安装这个包。可以通过CRAN轻松安装:
install.packages("sparklyr")
安装完成后,还需要安装Spark的本地版本:
library(sparklyr)
spark_install()
接下来,就可以连接到Spark了:
library(sparklyr)
sc <- spark_connect(master = "local")
这里创建了一个本地的Spark连接。对于远程集群,只需要更改master参数即可。
数据操作与分析
使用dplyr进行数据处理
sparklyr与dplyr的集成是其最强大的特性之一。这允许R用户使用熟悉的dplyr语法来操作Spark数据框。例如:
library(dplyr)
# 将R数据集复制到Spark
iris_tbl <- copy_to(sc, iris)
# 使用dplyr语法进行数据操作
result <- iris_tbl %>%
filter(Sepal.Length > 5) %>%
group_by(Species) %>%
summarise(avg_petal_width = mean(Petal.Width))
# 将结果收集回R
collected_result <- collect(result)
这个例子展示了如何将R中的iris数据集复制到Spark,然后使用dplyr语法进行过滤、分组和汇总操作。最后,我们将结果收集回R进行进一步分析或可视化。
SQL查询
除了使用dplyr,sparklyr还支持直接执行SQL查询:
library(DBI)
result <- dbGetQuery(sc, "SELECT Species, AVG(Petal_Width) as avg_petal_width
FROM iris
WHERE Sepal_Length > 5
GROUP BY Species")
这种方法特别适合那些更熟悉SQL的用户,或者需要执行复杂查询的场景。
机器学习与高级分析
sparklyr不仅仅是用于数据处理,它还提供了对Spark MLlib的访问,使得在大规模数据上进行机器学习变得简单。
线性回归示例
以下是使用sparklyr进行线性回归的一个简单示例:
# 准备数据
mtcars_tbl <- copy_to(sc, mtcars)
# 拆分训练集和测试集
partitions <- mtcars_tbl %>%
sdf_random_split(training = 0.7, test = 0.3, seed = 1099)
# 训练线性回归模型
model <- partitions$training %>%
ml_linear_regression(response = "mpg", features = c("wt", "cyl"))
# 查看模型摘要
summary(model)
# 在测试集上进行预测
predictions <- ml_predict(model, partitions$test)
这个例子展示了如何使用sparklyr训练一个线性回归模型,并在测试集上进行预测。sparklyr的机器学习API设计得非常直观,使得即使是复杂的机器学习任务也能轻松完成。
其他机器学习算法
除了线性回归,sparklyr还支持多种其他机器学习算法,如逻辑回归、决策树、随机森林、支持向量机等。这些算法都可以通过类似的API轻松使用。
数据导入与导出
在大数据分析中,数据的导入和导出是关键步骤。sparklyr提供了多种方法来读取和写入不同格式的数据。
读取数据
sparklyr支持读取CSV、JSON、Parquet等多种格式的数据:
# 读取CSV文件
csv_data <- spark_read_csv(sc, "my_csv_data", "path/to/file.csv")
# 读取JSON文件
json_data <- spark_read_json(sc, "my_json_data", "path/to/file.json")
# 读取Parquet文件
parquet_data <- spark_read_parquet(sc, "my_parquet_data", "path/to/file.parquet")
写入数据
同样,sparklyr也支持将数据写入这些格式:
# 写入CSV文件
spark_write_csv(my_data, "path/to/output.csv")
# 写入JSON文件
spark_write_json(my_data, "path/to/output.json")
# 写入Parquet文件
spark_write_parquet(my_data, "path/to/output.parquet")
这些功能使得sparklyr能够轻松地与各种数据源和数据湖集成。
分布式R计算
sparklyr的一个强大特性是能够在Spark集群上执行分布式R代码。这通过spark_apply()函数实现:
# 在Spark集群上应用R函数
result <- spark_apply(iris_tbl, function(data) {
# 这里可以使用任何R代码
data$Sepal.Area <- data$Sepal.Length * data$Sepal.Width
return(data)
})
这个功能允许用户利用Spark的分布式计算能力来执行复杂的R计算,大大提高了处理大规模数据的效率。
与其他工具的集成
sparklyr不仅仅是一个独立的工具,它还能与其他流行的数据科学工具无缝集成。
与H2O的集成
通过rsparkling包,sparklyr可以与H2O的机器学习算法集成:
library(rsparkling)
library(h2o)
# 将Spark数据转换为H2O格式
mtcars_h2o <- as_h2o_frame(sc, mtcars_tbl)
# 使用H2O的算法
model <- h2o.glm(x = c("wt", "cyl"), y = "mpg", training_frame = mtcars_h2o)
这种集成使得用户可以在Spark的分布式环境中利用H2O强大的机器学习能力。
与Livy的集成
sparklyr还支持通过Livy连接到远程Spark集群:
sc <- spark_connect(master = "http://livy-server:8998", method = "livy")
这为在企业环境中使用sparklyr提供了更多的灵活性。
RStudio集成
对于使用RStudio IDE的用户来说,sparklyr提供了额外的便利。RStudio包含了对Spark和sparklyr的集成支持,包括:
- 创建和管理Spark连接的图形界面
- 浏览Spark数据框的表格和列
- 预览Spark数据框的前1000行
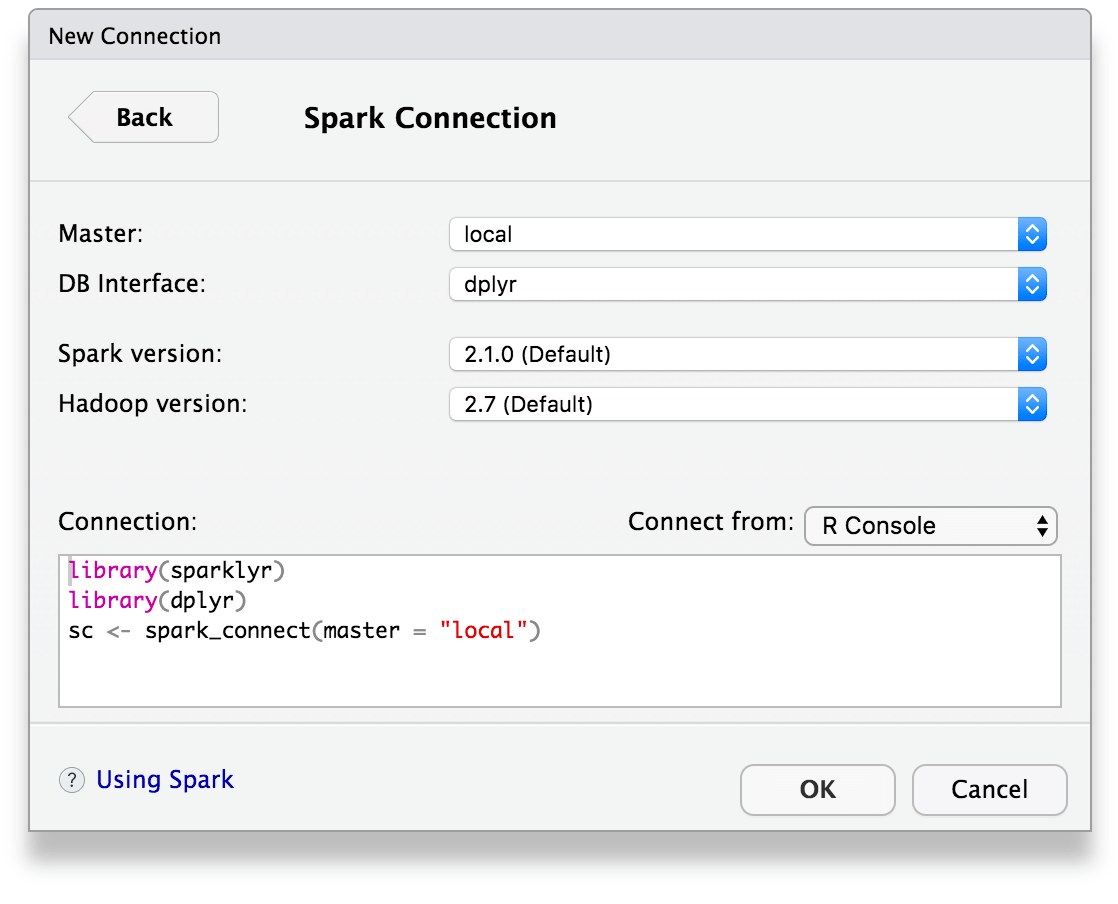
这些功能大大简化了在RStudio中使用Spark的工作流程。
性能考虑
虽然sparklyr提供了便利的接口,但在处理大规模数据时,性能仍然是一个重要考虑因素。以下是一些提高sparklyr性能的建议:
-
减少数据移动: 尽量在Spark中完成大部分数据处理,只将必要的结果收集回R。
-
使用缓存: 对频繁使用的数据集使用
sdf_persist()进行缓存。 -
优化查询: 利用Spark的查询优化器,编写高效的dplyr操作或SQL查询。
-
合理配置: 根据数据规模和集群资源合理配置Spark参数。
扩展sparklyr
sparklyr的设计允许用户创建自定义扩展,以支持更多Spark功能或集成其他工具。这通过创建新的R包来实现,该包可以定义新的Spark函数、自定义数据源等。
结论
sparklyr为R用户提供了一个强大而灵活的工具,使他们能够轻松地利用Apache Spark的分布式计算能力。通过结合R的统计分析能力和Spark的大规模数据处理能力,sparklyr开启了大数据分析的新篇章。无论是数据清理、探索性数据分析,还是复杂的机器学习任务,sparklyr都能胜任。
随着大数据时代的深入,sparklyr的重要性只会继续增长。它不仅简化了R用户使用Spark的过程,还为传统的R分析工作流带来了处理大规模数据的能力。对于任何希望在大数据环境中发挥R优势的数据科学家来说,掌握sparklyr无疑是一项宝贵的技能。
随着sparklyr的持续发展和社区的不断壮大,我们可以期待看到更多创新功能和用例的出现。无论是在学术研究、商业分析还是数据科学教育中,sparklyr都将继续发挥重要作用,推动R语言在大数据时代的应用前沿。
总之,sparklyr不仅仅是一个工具,它代表了一种将传统统计分析与现代大数据技术结合的趋势。通过掌握sparklyr,R用户可以大大扩展自己的数据分析能力,迎接大数据时代的挑战与机遇。🚀📊









