
SparseTransformer: 突破3D视觉的新利器
在深度学习领域,Transformer架构因其强大的建模能力而备受关注。然而,在处理3D点云等具有稀疏性和可变长度特征的数据时,传统Transformer往往面临计算效率和内存消耗的挑战。为了解决这一问题,来自香港中文大学的研究团队开发了SparseTransformer(SpTr)库,为3D视觉任务提供了一种高效的解决方案。
SparseTransformer的核心优势
SparseTransformer是一个基于PyTorch的开源库,具有以下几个突出特点:
-
高效性: 通过优化的CUDA实现,SpTr能够快速处理稀疏数据,大幅提升计算效率。
-
内存友好: 针对可变长度的token序列,SpTr采用了特殊的内存管理策略,有效降低内存占用。
-
易用性: SpTr提供了简洁的API,使得研究人员可以轻松将其集成到现有的Transformer模型中。
-
灵活性: 支持处理整数索引(基于体素的方法)和浮点坐标(基于点的方法),适应不同类型的3D数据表示。
这些特性使得SparseTransformer特别适合处理3D点云数据,为许多计算机视觉任务带来了新的可能性。
安装与使用
要开始使用SparseTransformer,首先需要安装相关依赖:
pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html
pip install torch_scatter==2.0.9
pip install torch_geometric==1.7.2
然后,通过以下命令编译并安装SpTr:
python3 setup.py install
使用SparseTransformer非常简单,只需几行代码即可将其集成到现有的Transformer模型中:
import sptr
# 定义注意力模块
dim = 48
num_heads = 3
indice_key = 'sptr_0'
window_size = np.array([0.4, 0.4, 0.4])
shift_win = False
self.attn = sptr.VarLengthMultiheadSA(
dim,
num_heads,
indice_key,
window_size,
shift_win
)
# 将输入特征和索引包装成SparseTrTensor
input_tensor = sptr.SparseTrTensor(feats, indices, spatial_shape=None, batch_size=None)
output_tensor = self.attn(input_tensor)
# 提取输出特征
output_feats = output_tensor.query_feats
在3D视觉任务中的应用
SparseTransformer已经在多个前沿的3D视觉研究中得到应用,展现出了强大的性能:
-
SphereFormer: 这是一个基于LiDAR的3D识别模型,利用SpTr处理球形投影的点云数据,在自动驾驶场景中取得了出色的效果。
-
Stratified Transformer: 该模型针对3D点云分割任务,采用分层策略和SpTr结构,在多个benchmark上达到了state-of-the-art的性能。
这些应用充分证明了SparseTransformer在处理复杂3D数据时的优势,为未来的研究开辟了新的方向。
技术原理剖析
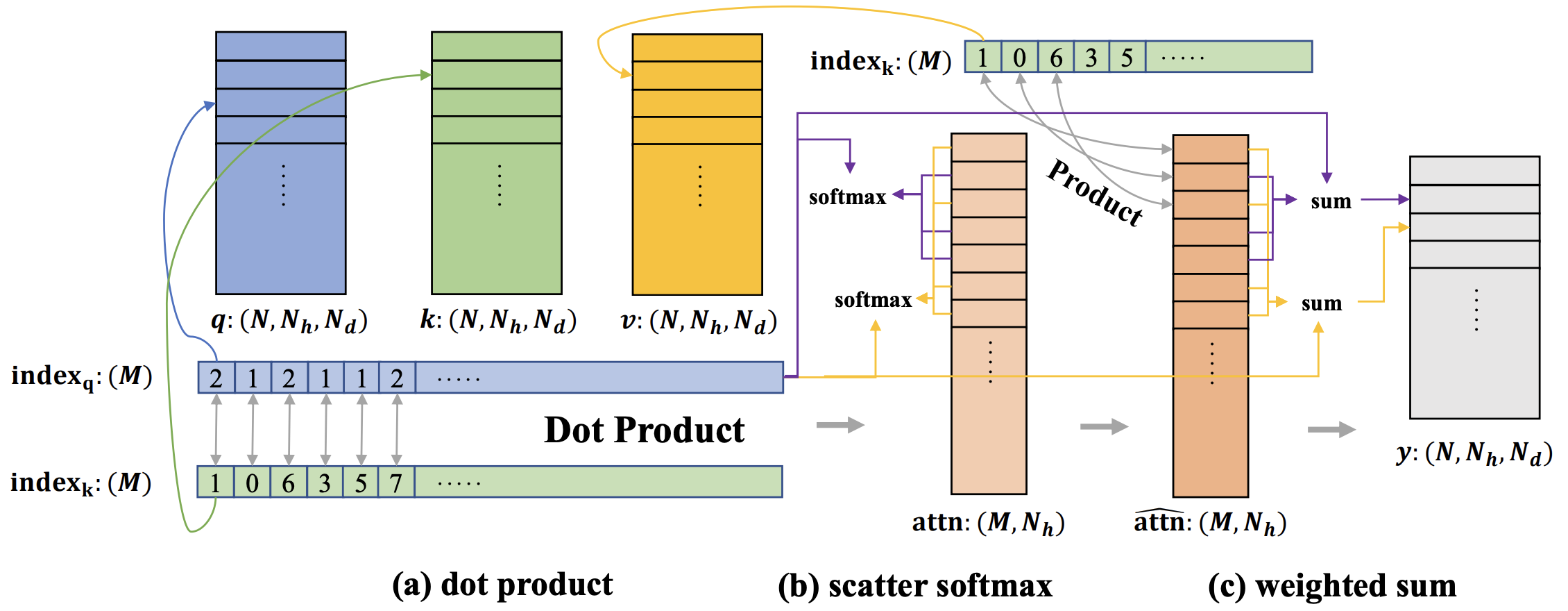
SparseTransformer的核心是其变长多头自注意力机制(VarLengthMultiheadSA)。与传统Transformer不同,SpTr能够高效处理不同长度的token序列,这对于3D点云数据尤为重要。
具体来说,SpTr通过以下几个关键步骤实现高效计算:
-
稀疏表示: 使用SparseTrTensor封装输入数据,保留空间信息同时减少冗余计算。
-
窗口划分: 根据给定的window_size参数,将3D空间划分为多个局部区域,限制注意力计算范围。
-
高效索引: 利用优化的CUDA kernels,快速定位和处理每个窗口内的有效点。
-
并行计算: 充分利用GPU并行能力,同时处理多个注意力头和多个样本。
这种设计不仅提高了计算效率,还大大降低了内存消耗,使得在大规模3D数据上训练深度Transformer模型成为可能。
未来展望
随着3D视觉技术在自动驾驶、机器人、AR/VR等领域的广泛应用,对高效处理大规模3D数据的需求日益增长。SparseTransformer为这一挑战提供了一个有力的解决方案,其潜力远未被完全发掘。
未来,我们可以期待看到SpTr在以下方面的进一步发展:
-
跨模态融合: 结合2D图像和3D点云数据,提供更全面的场景理解能力。
-
动态点云处理: 扩展到处理时序3D数据,如连续的LiDAR扫描序列。
-
更大规模模型: 利用SpTr的高效特性,训练更深更宽的Transformer模型,进一步提升性能。
-
新的应用场景: 探索在医疗影像、地理信息系统等领域的潜在应用。
参与贡献
SparseTransformer是一个开源项目,欢迎社区成员参与贡献。无论是改进代码、添加新功能,还是报告问题,都可以通过GitHub仓库参与进来。项目维护者Xin Lai、Fanbin Lu和Yukang Chen也欢迎与研究者和开发者就相关技术问题进行交流。
如果您在研究中使用了SparseTransformer,请引用以下论文:
@inproceedings{lai2023spherical,
title={Spherical Transformer for LiDAR-based 3D Recognition},
author={Lai, Xin and Chen, Yukang and Lu, Fanbin and Liu, Jianhui and Jia, Jiaya},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}
@inproceedings{lai2022stratified,
title={Stratified transformer for 3d point cloud segmentation},
author={Lai, Xin and Liu, Jianhui and Jiang, Li and Wang, Liwei and Zhao, Hengshuang and Liu, Shu and Qi, Xiaojuan and Jia, Jiaya},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={8500--8509},
year={2022}
}
结语
SparseTransformer为处理3D点云等稀疏数据提供了一个强大而灵活的工具。通过其高效的实现和易用的接口,SpTr正在推动3D视觉技术的边界,为研究人员和开发者开启了新的可能性。随着更多创新应用的出现,我们有理由相信,SparseTransformer将在未来的3D感知和理解任务中发挥越来越重要的作用。
无论您是研究人员、开发者还是对3D视觉感兴趣的爱好者,SparseTransformer都值得一试。它不仅能够帮助您更高效地处理3D数据,还可能激发出全新的创意和应用。让我们一起探索SparseTransformer的无限潜力,共同推动3D视觉技术的发展! 🚀🌟









