
STF:突破传统的图像压缩新范式
在当今数字时代,图像压缩技术对于高效存储和传输视觉信息至关重要。随着深度学习的蓬勃发展,基于神经网络的图像压缩方法逐渐成为研究热点。近期,一种名为STF(Swin Transformer for image compression)的创新压缩技术引起了学术界的广泛关注。本文将深入探讨STF的核心理念、技术细节及其在图像压缩领域的重要意义。
STF的诞生背景
传统的图像压缩方法如JPEG虽然应用广泛,但在处理复杂图像时往往难以兼顾压缩率和图像质量。近年来,基于深度学习的端到端图像压缩方法展现出巨大潜力,但大多数模型仍然依赖于卷积神经网络(CNN)架构。然而,CNN在捕捉图像中的长距离依赖关系方面存在固有局限性。
为了突破这一瓶颈,研究人员将目光投向了Transformer架构。Transformer凭借其强大的自注意力机制,在自然语言处理领域取得了巨大成功。但是,将Transformer直接应用于图像压缩任务面临着计算复杂度高、内存消耗大等挑战。
正是在这样的背景下,STF应运而生。它巧妙地结合了Swin Transformer的窗口注意力机制和传统CNN的优势,为图像压缩任务提供了一种全新的解决方案。
STF的核心原理
STF的核心思想是利用窗口化的自注意力机制来高效处理图像数据。与标准Transformer不同,STF将输入图像划分为多个非重叠的窗口,并在这些局部窗口内计算自注意力。这种策略大大降低了计算复杂度,同时保留了Transformer捕捉长距离依赖关系的能力。
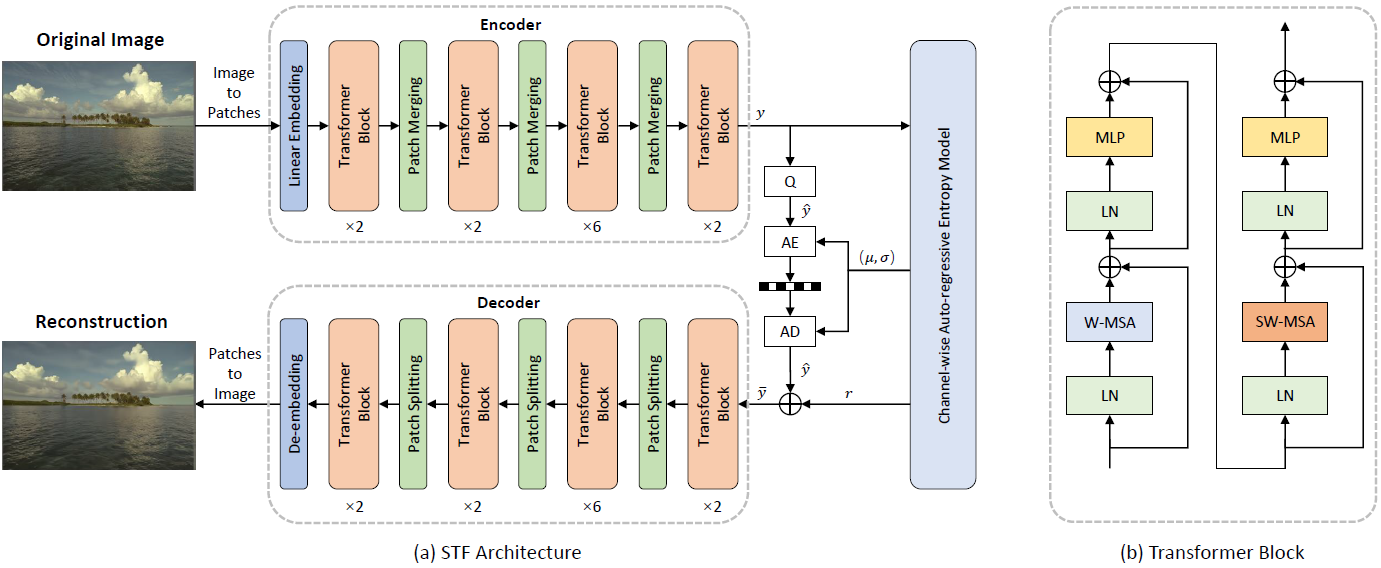
如上图所示,STF的整体架构包括编码器和解码器两个主要部分:
-
编码器:首先通过卷积层对输入图像进行特征提取,然后使用多个Swin Transformer块进行特征变换。每个Swin Transformer块包含窗口多头自注意力(W-MSA)层和前馈网络(FFN)层。
-
解码器:采用与编码器相似的结构,但以相反的顺序重建图像。通过逐步上采样和特征融合,最终生成重建图像。
-
量化模块:位于编码器和解码器之间,负责将连续的潜在表示离散化,以实现有效压缩。
-
熵编码:对量化后的数据进行进一步压缩,减少存储空间和传输带宽需求。
STF的优势与创新
-
高效的特征提取:窗口注意力机制使STF能够在局部区域内高效计算自注意力,同时通过窗口移位操作实现跨窗口信息交互,有效捕捉全局上下文信息。
-
可变压缩率:通过调整模型参数,STF可以灵活地在压缩率和重建质量之间取得平衡,适应不同的应用场景需求。
-
端到端训练:STF采用端到端的训练方式,可以同时优化特征提取、量化和熵编码等所有组件,从而达到最佳压缩性能。
-
与CNN的结合:STF巧妙地融合了CNN和Transformer的优势,在保持Transformer强大建模能力的同时,利用CNN高效处理局部特征。
STF的实现与训练
实现STF需要以下步骤:
-
环境配置:
conda create -n compress python=3.7 conda activate compress pip install compressai pybind11 git clone https://github.com/Googolxx/STF stf cd stf pip install -e . pip install -e '.[dev]' -
数据准备:STF使用OpenImages数据集进行训练。可以使用提供的
downloader_openimages.py脚本下载数据集。 -
模型训练:
CUDA_VISIBLE_DEVICES=0,1 python train.py -d /path/to/image/dataset/ -e 1000 --batch-size 16 --save --save_path /path/to/save/ -m stf --cuda --lambda 0.0035 -
模型评估:
CUDA_VISIBLE_DEVICES=0 python -m compressai.utils.eval_model -d /path/to/image/folder/ -r /path/to/reconstruction/folder/ -a stf -p /path/to/checkpoint/ --cuda
STF的性能表现
STF在多个标准数据集上展现出优异的压缩性能:
-
Kodak数据集:STF在低比特率下的PSNR指标优于多数传统和学习型压缩方法。
-
CLIC专业验证数据集:STF在不同比特率下均表现出色,尤其是在低比特率区域具有明显优势。
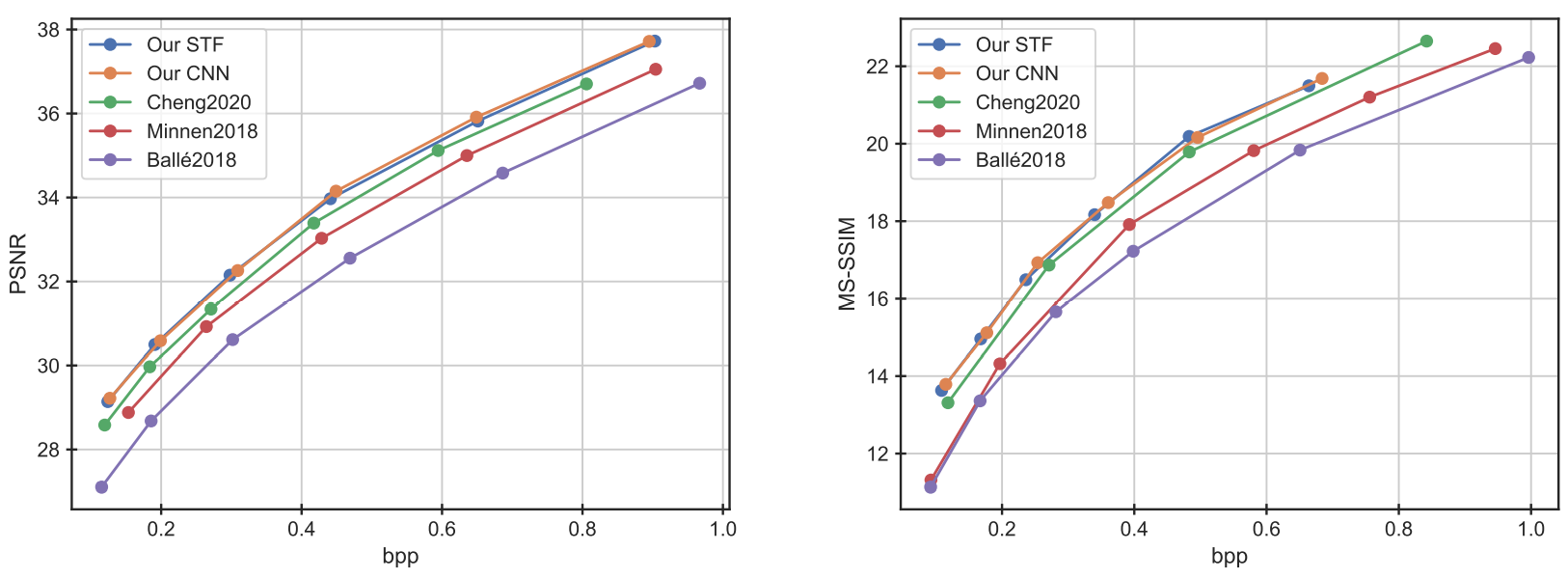
上图展示了STF在Kodak数据集上的率失真曲线,可以看出STF在各个比特率下都优于传统的JPEG和JPEG2000方法。
在编解码效率方面,STF也表现出色。在Kodak数据集上,STF的编码和解码时间分别为0.15秒,与基于CNN的方法相当,但压缩性能更优。
STF的应用前景
STF的出色性能使其在多个领域具有广阔的应用前景:
-
图像存储与传输:STF可以大幅减少图像存储空间和传输带宽需求,特别适用于云存储和移动设备等场景。
-
视频压缩:STF的原理可以扩展到视频压缩领域,有望提升视频流媒体的质量和效率。
-
医学图像:在医疗影像等对图像质量要求极高的领域,STF可以在保证图像细节的同时实现有效压缩。
-
遥感图像:对于大规模遥感图像数据,STF可以显著降低存储和传输成本,同时保留关键信息。
未来研究方向
尽管STF已经展现出优秀的性能,但仍存在进一步改进的空间:
-
计算优化:进一步优化STF的计算效率,使其更适合在资源受限的设备上运行。
-
硬件加速:探索针对STF架构的专用硬件加速方案,提高实时压缩和解压缩的速度。
-
多模态融合:将STF与其他模态(如文本、音频)的压缩技术结合,实现更全面的多媒体压缩方案。
-
可解释性研究:深入分析STF的工作原理,提高模型的可解释性和可控性。
结语
STF作为一种基于窗口注意力的创新图像压缩方法,不仅在性能上超越了传统方法,还为深度学习在图像压缩领域的应用开辟了新的道路。随着进一步的研究和优化,STF有望在未来的数字媒体处理和传输中发挥更加重要的作用,为高效、高质量的视觉信息传播提供强有力的技术支持。
相关资源
- STF官方GitHub仓库: https://github.com/Googolxx/STF
- CompressAI项目: https://github.com/InterDigitalInc/CompressAI
- Swin Transformer: https://github.com/microsoft/Swin-Transformer
- OpenImages数据集: https://github.com/openimages
- Kodak图像数据集: http://r0k.us/graphics/kodak/
对于有兴趣深入研究STF的读者,建议从官方GitHub仓库开始,阅读相关论文并尝试复现实验结果。同时,关注CompressAI等相关项目的最新进展,有助于更全面地了解深度学习图像压缩领域的发展动态。
STF的成功为图像压缩技术的未来发展指明了方向。随着更多研究者的加入和技术的不断迭代,我们有理由相信,基于深度学习的图像压缩方法将在不久的将来彻底改变数字图像的存储和传输方式,为信息时代的视觉通信带来革命性的变革。🚀🖼️













