
StreamSpeech - 集成语音识别、翻译与合成的"全能"模型
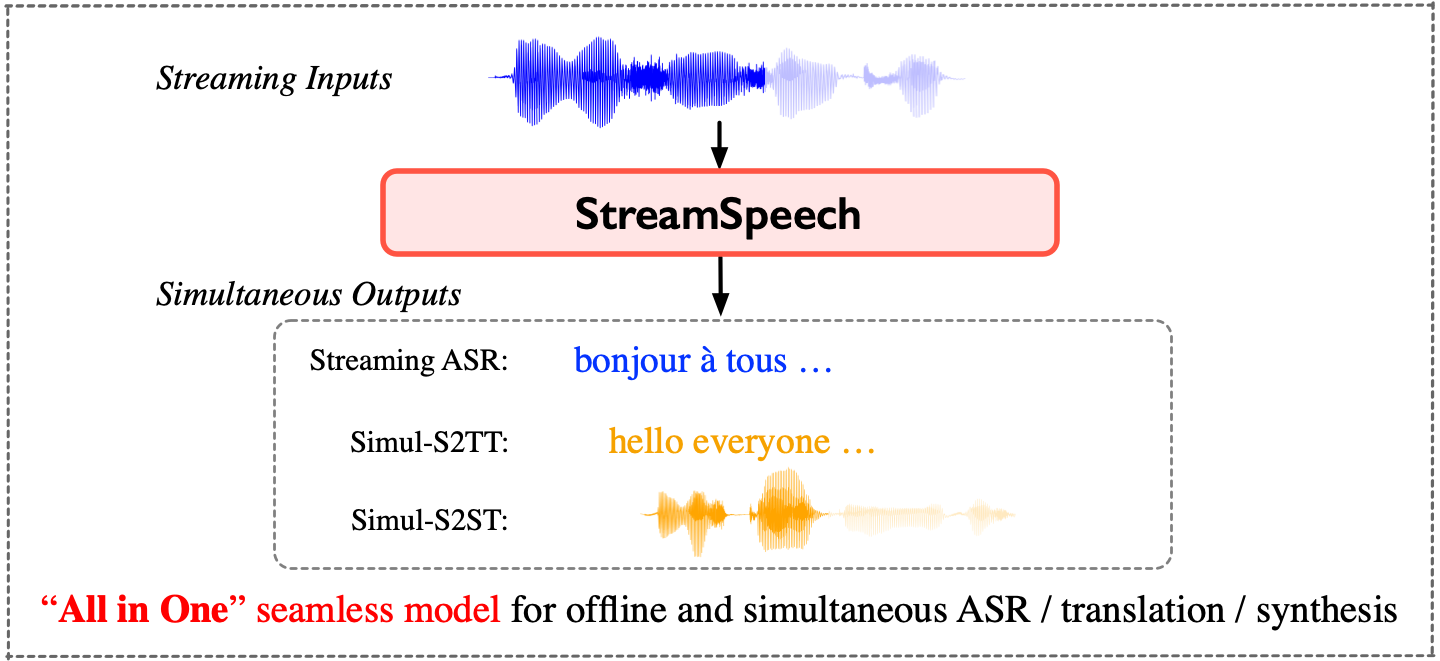
StreamSpeech是一个强大的"All in One"无缝模型,可同时进行离线和实时的语音识别、语音翻译和语音合成。本文将为大家介绍StreamSpeech项目的各种学习资源,帮助读者快速入门这个多功能语音处理模型。
🌟 项目亮点
-
StreamSpeech在离线和同步语音到语音翻译任务上均达到了SOTA性能。
-
通过一个无缝模型实现流式ASR、同步语音到文本翻译和同步语音到语音翻译。
-
在同步翻译过程中可以展示中间结果(如ASR或翻译结果),提供更全面的低延迟通信体验。
📚 学习资源
-
项目主页: StreamSpeech GitHub仓库
- 包含完整的代码实现、使用说明和示例
-
论文: StreamSpeech: Simultaneous Speech-to-Speech Translation with Multi-task Learning
- 详细介绍了StreamSpeech的技术原理和创新点
-
在线演示: StreamSpeech Demo
- 可以直接体验StreamSpeech的翻译效果
-
预训练模型: Hugging Face模型仓库
- 提供了多种语言对的预训练模型,方便直接使用
💻 快速开始
-
环境配置:
- Python 3.10
- PyTorch 2.0.1
- 安装fairseq和SimulEval
-
模型下载:
- 从Hugging Face或百度网盘下载预训练模型
-
数据准备:
- 按照SimulEval格式准备测试数据
-
模型推理:
- 使用提供的脚本进行流式ASR、同步S2TT和同步S2ST的推理
🔧 支持的任务
StreamSpeech支持以下8种任务:
- 离线: 语音识别(ASR)、语音到文本翻译(S2TT)、语音到语音翻译(S2ST)、语音合成(TTS)
- 实时: 流式ASR、同步S2TT、同步S2ST、实时TTS(在任意延迟下使用单一模型)
🎓 进阶学习
-
数据预处理: 参考
./preprocess_scripts处理CVSS-C数据。 -
模型训练:
- 同步语音到语音翻译:
train.simul-s2st.sh - 离线语音到语音翻译:
train.offline-s2st.sh
- 同步语音到语音翻译:
-
评估:
- 离线评估:
pred.offline-s2st.sh - 实时评估:
simuleval.simul-s2st.sh
- 离线评估:
📊 性能展示
StreamSpeech在多个任务上都取得了优异的性能,包括:
- 离线语音到语音翻译
- 同步语音到语音翻译
- 同步语音到文本翻译
- 流式ASR
具体的性能数据和对比图表可以在项目页面查看。
🤝 贡献与支持
如果您对StreamSpeech项目有任何问题或建议,欢迎在GitHub上提交issue或直接联系作者(zhangshaolei20z@ict.ac.cn)。如果您觉得这个项目对您有帮助,请考虑在您的研究中引用StreamSpeech。
StreamSpeech是一个功能强大、性能优异的语音处理模型,希望本文提供的学习资源能帮助您快速入门并充分利用这个优秀的工具。无论您是研究人员还是开发者,StreamSpeech都将为您的语音识别、翻译和合成任务带来全新的可能性。🚀










