
StreamSpeech:开创实时语音翻译新纪元
在当今全球化的时代,跨语言交流的需求日益增长。然而,实时语音翻译一直是一个具有挑战性的任务,需要在翻译质量和延迟之间取得平衡。近日,来自中国科学院计算技术研究所的研究团队提出了一种名为StreamSpeech的创新模型,为这一难题提供了突破性的解决方案。
StreamSpeech的核心理念
StreamSpeech是一个"一体化"的无缝模型,能够同时处理语音识别、语音翻译和语音合成任务。与传统的级联系统不同,StreamSpeech采用了多任务学习的方法,将翻译和同步策略统一到一个框架中。这种设计使得模型能够更好地把握语音输入中的关键时刻,从而在保证翻译质量的同时实现低延迟输出。
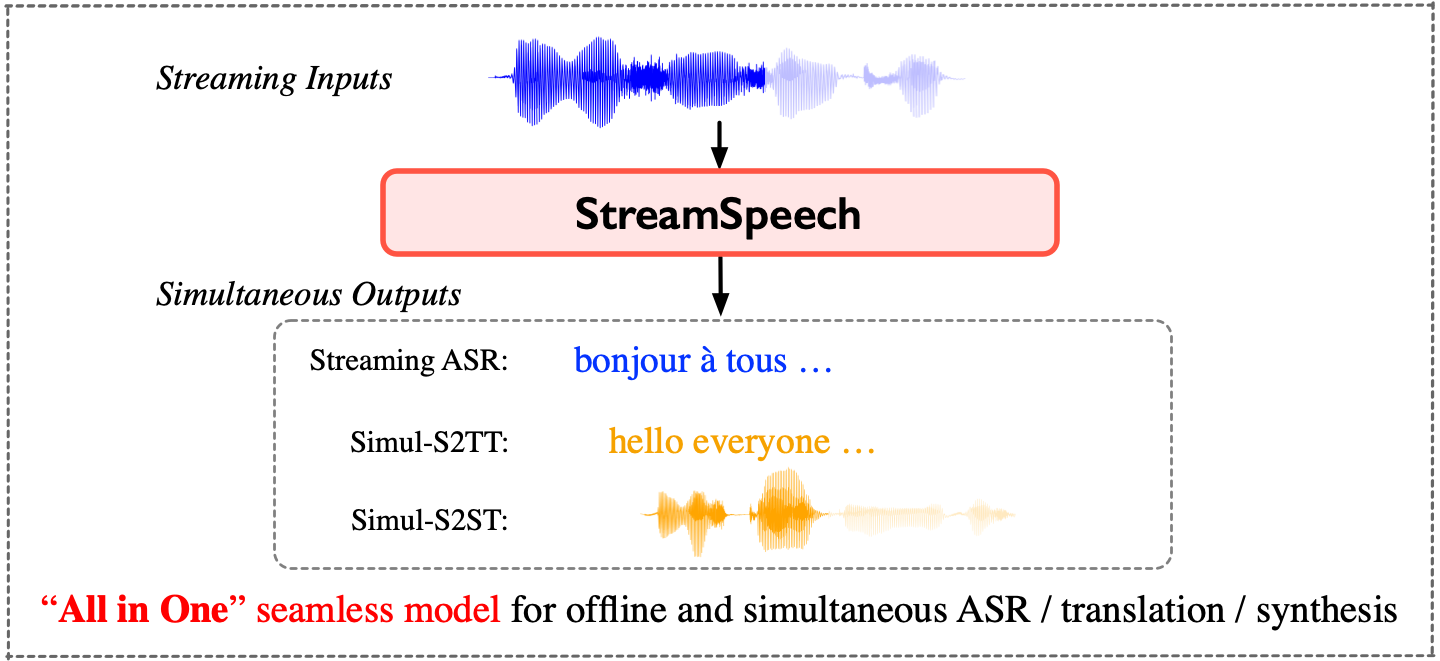
如上图所示,StreamSpeech采用了两阶段的架构设计:
- 第一阶段将源语音转换为目标文本的隐藏状态(自回归语音到文本翻译,AR-S2TT)
- 第二阶段通过非自回归的文本到单元生成来产生目标语音
此外,模型还引入了源语言/目标语言/单元CTC解码器,通过语音识别(ASR)、非自回归语音到文本翻译(NAR-S2TT)和语音到单元翻译(S2UT)等多个任务来学习对齐关系,从而指导StreamSpeech在何时开始识别、翻译和合成。
StreamSpeech的突出特点
-
卓越的性能: StreamSpeech在离线和同步语音到语音翻译任务中都达到了最先进的性能水平。这意味着无论是在预先录制的音频还是实时流式输入的场景中,StreamSpeech都能提供高质量的翻译结果。
-
多功能一体化: 作为一个无缝的流式模型,StreamSpeech能够同时执行流式语音识别、同步语音到文本翻译以及同步语音到语音翻译。这种多功能性使得它能够适应各种不同的应用场景。
-
中间结果输出: 在同步翻译过程中,StreamSpeech能够呈现高质量的中间结果(如ASR或翻译结果)。这一特性为用户提供了更全面的实时交流体验,使得交流双方能够更好地把握对话的进展。
-
灵活的延迟控制: StreamSpeech允许用户通过设置不同的chunk大小来控制翻译的延迟。这种灵活性使得模型可以根据具体应用的需求来平衡翻译质量和实时性。
StreamSpeech的应用前景
StreamSpeech的出现为实时跨语言交流开辟了新的可能性。以下是一些潜在的应用场景:
-
国际会议: 在多语言环境的国际会议中,StreamSpeech可以提供实时的语音翻译服务,使得与会者能够无障碍地交流。
-
在线教育: 对于跨语言的在线课程,StreamSpeech可以帮助学生实时理解外语授课内容,提高学习效率。
-
商务谈判: 在国际商务谈判中,StreamSpeech可以作为实时翻译助手,促进双方的沟通和理解。
-
旅游服务: 对于国际旅游者,StreamSpeech可以提供即时的语音翻译服务,帮助他们克服语言障碍。
-
医疗服务: 在跨语言的医疗咨询中,StreamSpeech可以帮助医生和患者进行准确的沟通,提高诊疗效果。
StreamSpeech的技术细节
StreamSpeech的优秀性能源于其精心设计的模型架构和训练策略。以下是一些关键的技术细节:
-
多任务学习: StreamSpeech通过同时学习ASR、S2TT和S2ST等多个任务,提高了模型的泛化能力和鲁棒性。
-
CTC解码器: 引入CTC(Connectionist Temporal Classification)解码器有助于模型学习更好的对齐关系,从而提高翻译的准确性。
-
非自回归生成: 在目标语音生成阶段采用非自回归方法,大大提高了模型的推理速度,有利于实现低延迟输出。
-
流式处理: StreamSpeech采用基于chunk的处理方式,能够在接收到部分输入的情况下就开始生成输出,实现真正的实时翻译。
StreamSpeech的性能评估
研究团队在CVSS基准数据集上对StreamSpeech进行了全面的评估。结果显示,StreamSpeech在多个指标上都取得了显著的进步:
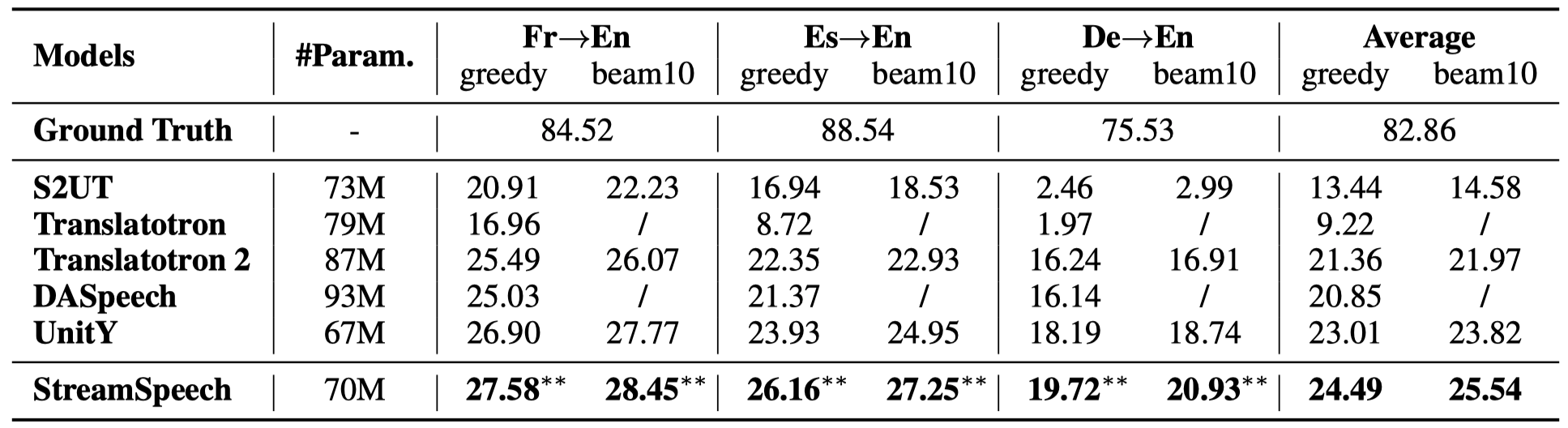
上图展示了StreamSpeech在离线语音到语音翻译任务中的性能。可以看到,StreamSpeech在ASR-BLEU指标上明显优于其他基线模型。
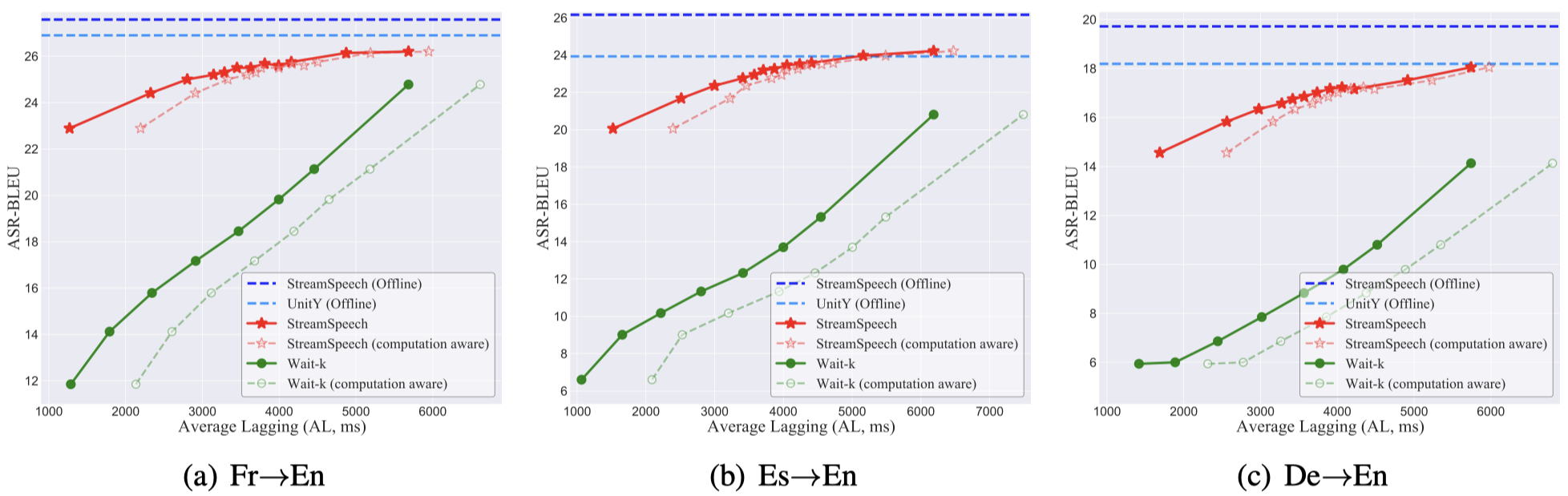
这张图展示了StreamSpeech在同步语音到语音翻译任务中的表现。横轴代表延迟(AL),纵轴代表翻译质量(ASR-BLEU)。可以看到,StreamSpeech在不同延迟设置下都能保持较高的翻译质量,展现出了优秀的性能-延迟权衡。
StreamSpeech的开源与社区
为了推动语音翻译技术的发展,研究团队已经将StreamSpeech的代码、模型和演示开源。开发者和研究者可以通过以下方式获取相关资源:
- GitHub仓库: https://github.com/ictnlp/StreamSpeech
- 预训练模型: Hugging Face模型库
- 在线演示: StreamSpeech演示网站
研究团队鼓励社区成员参与到StreamSpeech的开发和改进中来。无论是提出新的想法、报告问题还是贡献代码,都将有助于推动这项技术的进步。
未来展望
尽管StreamSpeech已经取得了令人瞩目的成果,但实时语音翻译领域仍有很大的发展空间。未来的研究方向可能包括:
-
多语言扩展: 目前StreamSpeech主要支持法语、西班牙语和德语到英语的翻译。未来可以扩展到更多的语言对,以满足全球范围内的翻译需求。
-
个性化适应: 开发能够适应不同说话者风格和口音的个性化模型,提高翻译的自然度和准确性。
-
多模态融合: 结合视觉信息等其他模态,提高翻译的上下文理解能力和准确性。
-
低资源语言支持: 探索如何在训练数据有限的情况下,为低资源语言提供高质量的实时翻译服务。
-
硬件优化: 研究如何将StreamSpeech部署到移动设备等资源受限的平台上,实现更广泛的应用。
结语
StreamSpeech的出现标志着实时语音翻译技术迈入了一个新的阶段。通过创新的模型设计和多任务学习策略,StreamSpeech成功地在翻译质量和延迟之间取得了优秀的平衡。这一突破不仅为学术研究提供了新的思路,也为实际应用带来了巨大的潜力。
随着技术的不断完善和应用场景的拓展,我们有理由相信,StreamSpeech将在促进全球交流、消除语言障碍方面发挥越来越重要的作用。未来,实时、准确、自然的跨语言交流或许将不再是梦想,而是触手可及的现实。










