
T-MAC:让CPU重焕新生的低比特LLM部署利器
在人工智能飞速发展的今天,大型语言模型(LLM)正在各行各业掀起一场革命。然而,这些模型庞大的计算需求也给部署带来了巨大挑战,尤其是在计算资源有限的边缘设备上。为了解决这一难题,微软研究院推出了一款名为T-MAC的创新性内核库,旨在通过查找表(LUT)技术显著提升低比特LLM在CPU上的推理性能。本文将详细介绍T-MAC的核心技术、性能优势及使用方法,探讨它如何为边缘AI部署开辟新的可能性。
T-MAC:颠覆传统的混合精度计算方案
T-MAC的核心创新在于其独特的混合精度矩阵乘法(mpGEMM)实现方式。传统的低比特量化方法虽然可以压缩模型大小,但在实际计算时往往需要先将数据"反量化"回高精度,这一过程会引入额外的计算开销。T-MAC则另辟蹊径,通过预先计算可能的部分和并存储在查找表中,直接支持低比特权重与高精度激活之间的乘法运算,从而绕过了耗时的反量化步骤。
具体来说,T-MAC采用了以下几项关键技术:
- 对于低精度权重(如1-4位),将其分组(例如每4位一组),预计算所有可能的部分和,并存储在查找表中。
- 利用移位和累加操作,灵活支持1到4位的权重精度。
- 在CPU上,充分利用tbl/pshuf等指令实现快速的表查找。
- 通过引入符号位,将表大小从2^n减少到2^(n-1),加速LUT的预计算过程。
这种基于查找表的方法带来了几个显著的优势:
- T-MAC展现出与位数线性相关的FLOP和推理延迟缩放比。这与传统的基于转换的方法形成鲜明对比,后者在从4位降至更低位数时往往无法带来额外的加速。
- T-MAC天然支持int1/2/3/4的位级计算,无需反量化。此外,它还可以通过快速的表查找和加法指令来适配各种类型的激活(如fp8、fp16、int8),避免了对poorly supported的融合乘加指令的依赖。
性能飞跃:T-MAC vs 传统方法
T-MAC的性能优势在各种硬件平台上得到了充分验证。以下是一些关键的性能数据:
- 在Surface Laptop 7上,对于3B BitNet模型,T-MAC单核可达20 tokens/sec,四核可达48 tokens/sec,相比于目前最先进的CPU低比特框架(如llama.cpp)实现了4-5倍的加速。
- 即使在树莓派5等低端设备上,T-MAC也能达到11 tokens/sec的生成速度。
- T-MAC在达到相同性能时所需的CPU核心数显著减少。例如,要达到40 tokens/sec(远超人类阅读速度)的吞吐量,T-MAC只需2个核心,而llama.cpp则需要8个核心。
- 在最新的骁龙X Elite芯片组上,T-MAC通过CPU甚至超越了NPU的性能。在部署llama-2-7b-4bit模型时,NPU只能达到10.4 tokens/sec,而T-MAC使用两个CPU核心就能达到12.6 tokens/sec,使用四个核心更可高达18.7 tokens/sec。
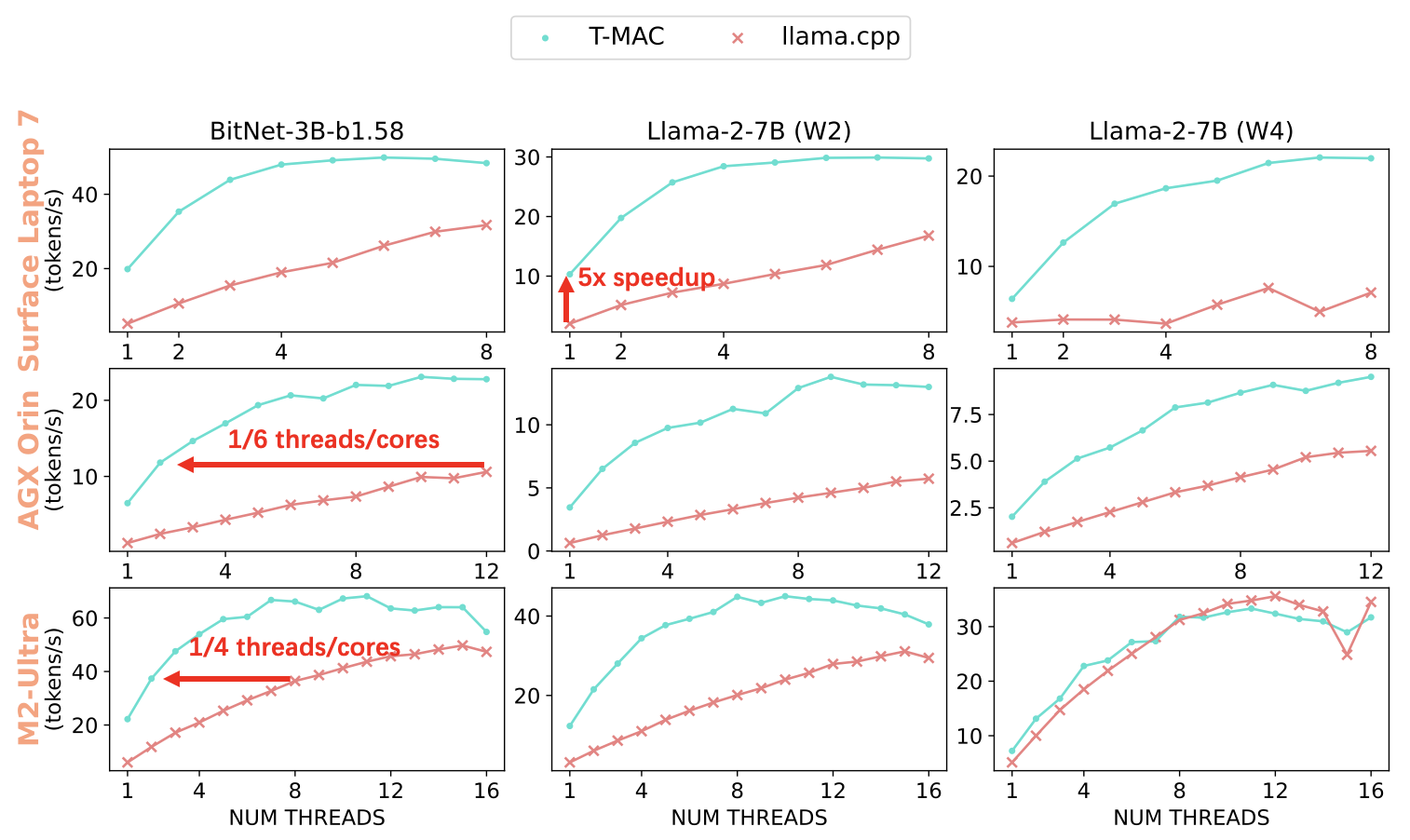
这些性能数据充分展示了T-MAC在低比特LLM推理方面的巨大潜力。通过使用更少的CPU核心就能达到更高的吞吐量,T-MAC不仅提高了推理速度,还为其他应用保留了计算资源,同时显著降低了功耗和能耗,这对边缘设备尤为重要。
节能先锋:T-MAC的能效优势
除了性能提升,T-MAC在能耗方面也展现出显著优势。通过将繁重的融合乘加指令替换为轻量级的表查找指令,T-MAC大幅降低了功耗。结合其带来的速度提升,最终实现了总能耗的大幅下降。
以M2-Ultra芯片为例,对于7B参数的Llama-2模型(4位量化),T-MAC在8线程下的功耗仅为17.3W,而llama.cpp则高达25.7W。考虑到T-MAC更快的推理速度,其每token的能耗仅为llama.cpp的37%。这一优势在2位量化时更为显著,T-MAC的每token能耗仅为llama.cpp的29%。
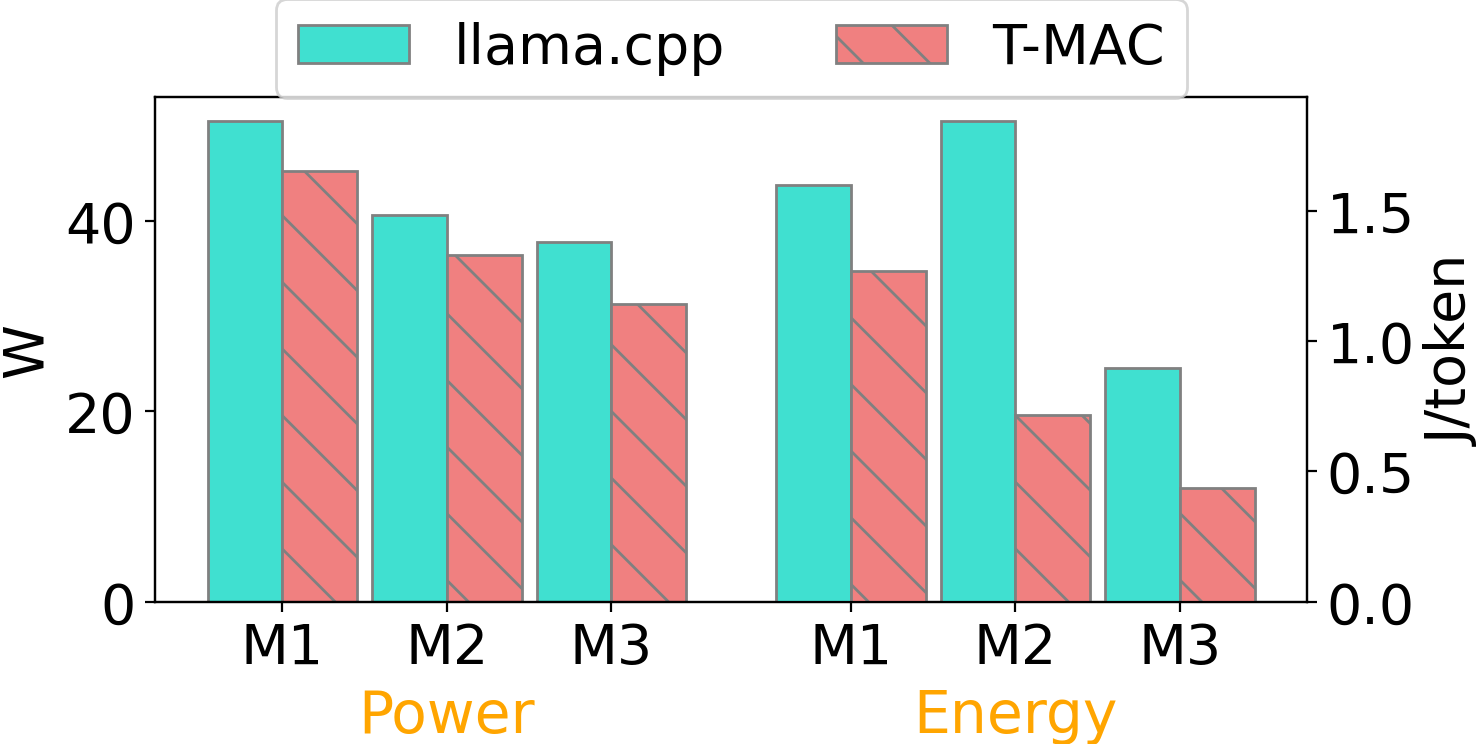
这种显著的能效优势使T-MAC成为边缘AI部署的理想选择,尤其是在功耗敏感的场景中。
广泛兼容:T-MAC的模型支持
T-MAC目前已经支持多种低比特模型,包括:
- GPTQ/gguf格式的W4A16模型
- BitDistiller/EfficientQAT的W2A16模型
- BitNet的W1(.58)A8模型
这些模型可以在搭载ARM/Intel CPU的OSX/Linux/Windows系统上运行。T-MAC团队正在持续扩大其支持的模型范围,未来还将添加更多主流LLM模型的支持。
使用T-MAC:从安装到推理
要开始使用T-MAC,首先需要安装必要的依赖:
brew install cmake zlib libomp # 针对OSX系统
然后从源码安装T-MAC(建议在虚拟环境中进行):
git clone --recursive https://github.com/microsoft/T-MAC.git
pip install -e . -v
source build/t-mac-envs.sh
安装完成后,可以使用以下命令验证安装:
python -c "import t_mac; print(t_mac.__version__); from tvm.contrib.clang import find_clang; print(find_clang())"
T-MAC提供了一个一体化脚本,方便用户快速开始使用:
pip install 3rdparty/llama.cpp/gguf-py
huggingface-cli download 1bitLLM/bitnet_b1_58-3B --local-dir ${model_dir}
python tools/run_pipeline.py -o ${model_dir}
此外,T-MAC还支持GPTQ格式的模型,例如EfficientQAT发布的Llama-3-8b-instruct-w2-g128:
huggingface-cli download ChenMnZ/Llama-3-8b-instruct-EfficientQAT-w2g128-GPTQ --local-dir ${model_dir}
python tools/run_pipeline.py -o ${model_dir} -m llama-3-8b-2bit
用户可以通过各种参数来自定义运行过程,如选择特定步骤、使用预编译内核等。
未来展望:T-MAC的发展方向
T-MAC团队正在积极开发新功能,计划在近期实现以下目标:
- 添加
I4格式,简化4位模型的部署流程。 - 将T-MAC GEMM内核嵌入llama.cpp,加速prefill/prompt处理。
- 提供Android交叉编译指南。
- 合并最新的llama.cpp,提升多线程性能并增加更多功能。
- 针对搭载SME2的ARMv9 CPU进行优化,通过LUTI4提升性能。
这些计划的实现将进一步提升T-MAC的性能和易用性,使其成为更加全面和强大的低比特LLM部署工具。
结语:T-MAC开启边缘AI新纪元
T-MAC的出现无疑为低比特LLM在边缘设备上的部署开辟了新的可能性。通过创新的查找表技术,T-MAC不仅显著提升了推理性能,还大幅降低了能耗,使得在资源受限的环境中运行复杂的语言模型成为可能。随着T-MAC的持续发展和优化,我们有理由相信,它将在推动边缘AI技术普及和应用方面发挥越来越重要的作用。
对于研究人员和开发者而言,T-MAC提供了一个强大而灵活的工具,可以帮助他们更高效地部署和优化低比特LLM。而对于终端用户来说,T-MAC的应用意味着他们可以在更多设备上体验到AI带来的便利,无论是智能手机、平板电脑还是其他边缘设备。
展望未来,随着T-MAC技术的不断成熟和应用范围的扩大,我们期待看到更多创新性的AI应用在边缘设备上落地,为人们的日常生活带来更多智能化的体验。T-MAC不仅是一个技术创新,更是推动AI民主化的重要一步,让更多人能够便捷地接触和使用先进的AI技术。
AI技术的发展永无止境,而T-MAC无疑为这一领域注入了新的活力。让我们共同期待T-MAC在未来带来更多惊喜,为AI技术的普及和创新贡献力量。









