
TACO数据集简介
TACO(Topics in Algorithmic COde generation dataset)是由北京智源人工智能研究院(BAAI)、山东师范大学和北京大学联合开发的一个专注于算法代码生成的大规模数据集。它旨在为代码生成模型领域提供更具挑战性的训练数据集和评估基准。TACO数据集的问题来源于编程竞赛,这些问题比传统的代码生成任务更加困难,更接近实际的编程场景。

TACO数据集的主要特点包括:
- 大规模: TACO包含25,443个训练问题和1,000个测试问题,是目前最大的代码生成数据集。
- 高质量: 每个问题都配有多样化的解答方案,解答规模高达1.55M,确保模型在训练过程中不会过拟合,并验证评估结果的有效性。
- 细粒度标签: 每个问题都包含任务主题、算法、技能和难度级别等细粒度标签,为代码生成模型的训练和评估提供更精确的参考。
TACO数据集的使用方法
下载和加载数据集
TACO数据集可以通过Hugging Face或BAAI DataHub下载使用。以下是使用Python的datasets库加载TACO数据集的示例代码:
from datasets import load_dataset
# 加载整个数据集
taco = load_dataset('BAAI/TACO', token=YOUR_HF_TOKEN)
# 加载特定分割(训练集或测试集)
taco_train = load_dataset('BAAI/TACO', split='train', token=YOUR_HF_TOKEN)
# 根据难度级别加载数据集
taco_difficulties = load_dataset('BAAI/TACO', difficulties=['EASY'], token=YOUR_HF_TOKEN)
# 根据编程技能加载数据集
taco_skills = load_dataset('BAAI/TACO', skills=['Sorting', 'Range queries'], token=YOUR_HF_TOKEN)
使用TACO进行模型评估
要使用TACO对代码生成模型进行评估,首先需要初始化模型、分词器以及要使用的难度级别或技能。以下是一个使用CodeLlama-7b模型进行评估的示例:
from transformers import AutoTokenizer, AutoModelForCausalLM
# 初始化模型和分词器
model_name = 'codellama/CodeLlama-7b-hf'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
device = "cuda:0"
model = model.to(device)
# 初始化评估数据集
difficulties = ['ALL']
taco = load_dataset('BAAI/TACO', split='test', difficulties=difficulties)
# 运行生成
n_samples = 200
temperature = 0.2
top_p = 0.95
output = []
for idx, sample in enumerate(taco):
prompt = sample['question']
results = {"task_id": idx, "prompt": prompt}
generations = []
for i in range(n_samples):
seed = i
generation = predict(device, model, tokenizer, prompt, seed, top_p, temperature, max_length=2048)
clean_code = truncate_after_eof_strings(generation)
generations.append(clean_code)
results["output"] = generations
output.append(results)
完整的评估过程包括代码生成和指标计算两个步骤。TACO项目提供了generation.py和compute_metric.py两个脚本,分别用于生成代码样本和计算pass@k指标。
TACO数据集的统计特征
TACO数据集在多个维度上都优于现有的代码生成数据集。以下是TACO与其他数据集的对比:
| 对比维度 | TACO | CodeContest | APPS | HumanEval(/-X) | MBP(/X)P |
|---|---|---|---|---|---|
| 问题规模 (训练/开发/测试) | 25443/-/1000 | 13328/117/165 | 5000/-/5000 | -/-/164 | 374/-/500 |
| 测试集中无答案数量 | 0 | 43/165 | 1235/5000 | 0 | 0 |
| 问题重复 | 无重复 | 无重复 | 无重复 | 已移除重复 | 已移除重复 |
| 答案重复 | 已移除重复 | 无重复 | 无重复 | 已移除重复 | 已移除重复 |
| 每个问题的测试用例数 | 202.3 | 203.7 | 20.99 | 7.77 | 3 |
| 任务主题 | 有 | 有 | 无 | 无 | 无 |
| 算法标签 | 有 | 无 | 无 | 无 | 无 |
| 编程技能 | 有 | 无 | 无 | 无 | 无 |
| 难度标签 | 有 | 有 | 有 | 无 | 无 |
TACO数据集中的算法标签和编程技能分布如下:
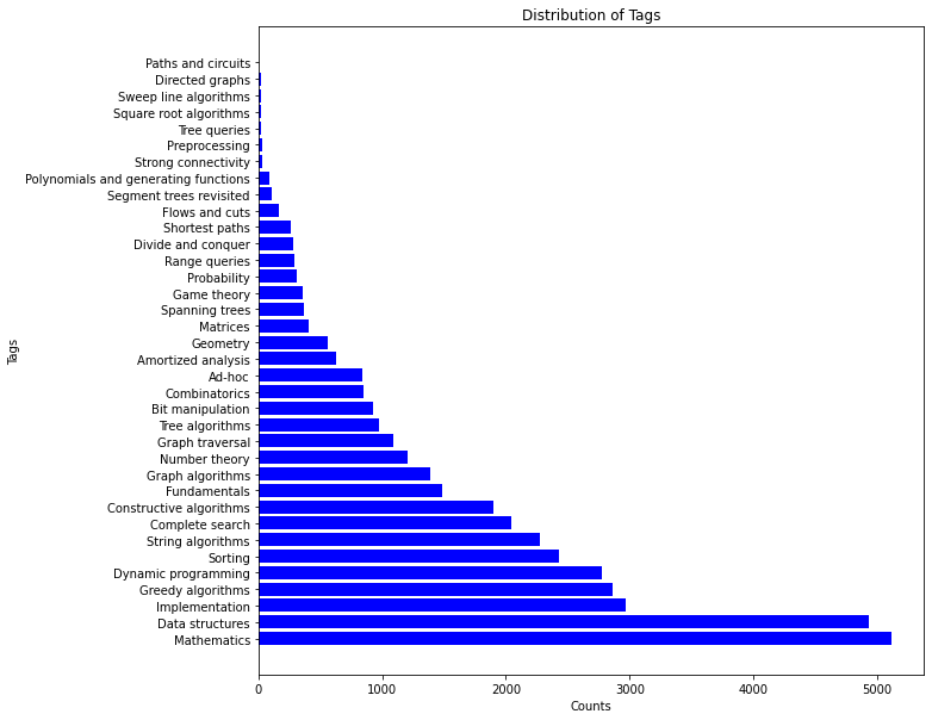
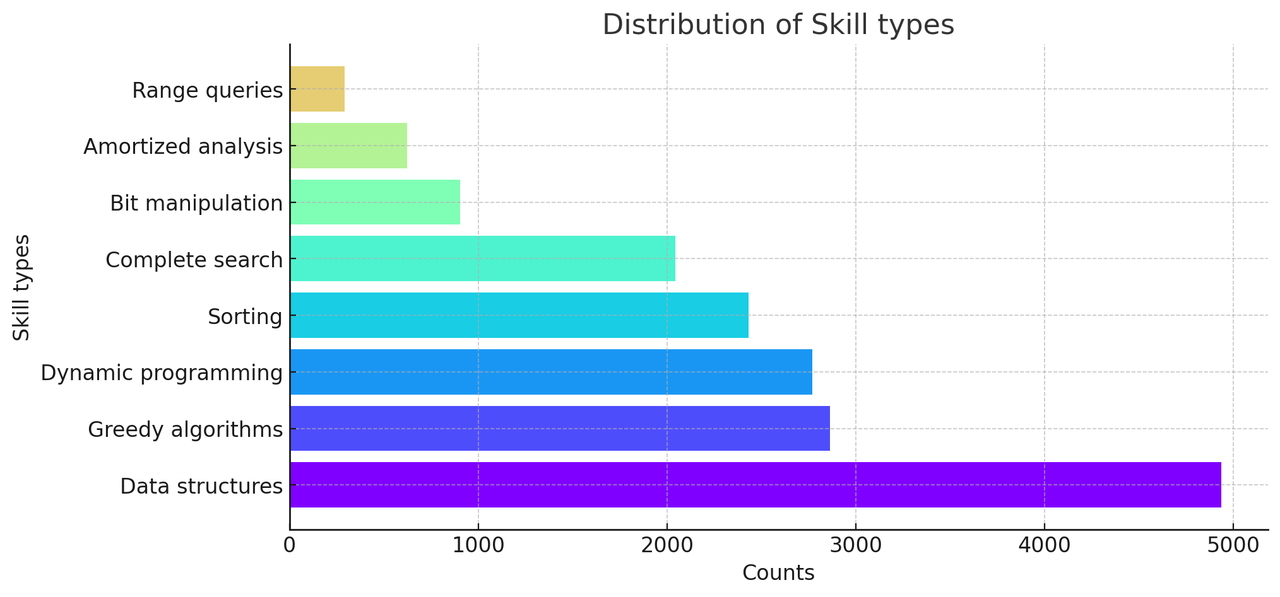
使用TACO进行模型微调
TACO数据集不仅可以用于评估,还可以用于模型微调。以下是使用TACO训练集进行模型微调的步骤:
- 预处理和标记化数据:
python pretokenizing.py \
--tokenizer_dir codellama/CodeLlama-7b-hf \
--cache_dir . \
--dataset_name codellama_tokenized
- 使用预处理后的数据进行微调:
torchrun --nproc_per_node=8 --nnodes=1 train.py \
--model_name_or_path codellama/CodeLlama-7b-hf \
--data_path codellama_tokenized \
--bf16 True \
--output_dir codellama_ft \
--num_train_epochs 2 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 500 \
--save_total_limit 1 \
--learning_rate 5e-5 \
--weight_decay 0.1 \
--warmup_ratio 0.1 \
--logging_steps 1 \
--resume_from_checkpoint True \
--gradient_checkpointing True \
--deepspeed ds_configs/deepspeed_z2_config_bf16.json
TACO评估结果
研究团队使用TACO测试集和训练集对GPT-4和一个在大量代码数据上训练的代码生成模型进行了实验。结果显示:
- TACO测试集具有高度挑战性。即使是GPT-4,在简单难度级别上的pass@1分数也仅为31.5%。除GPT-4外,其他代码模型在五个难度级别上的pass@1分数普遍低于10%。
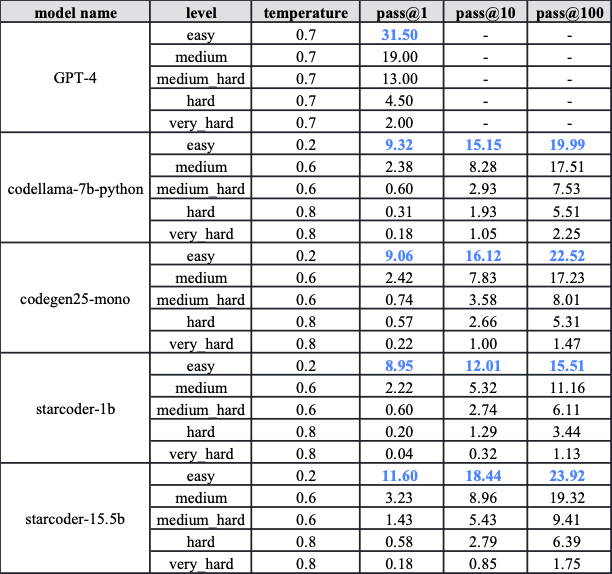
- 利用TACO训练集的细粒度标签可以有选择性地提高代码生成模型的性能。例如,在使用TACO训练集对starcoder-1b进行特定技能的微调后,性能有明显提升。
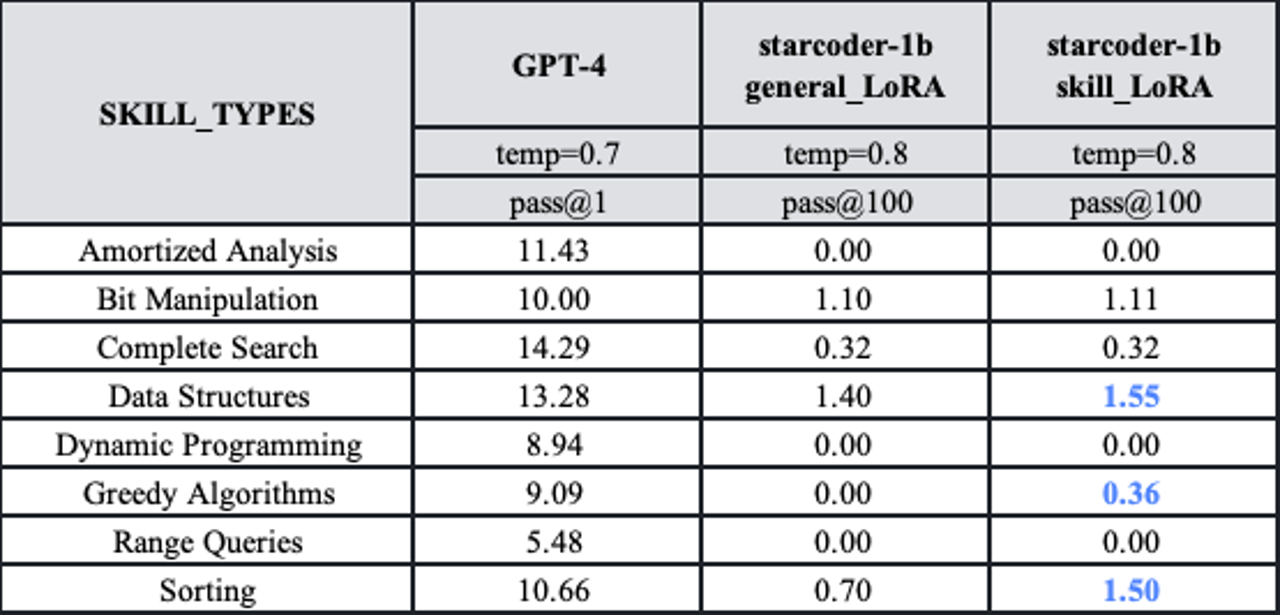
TACO的意义和影响
TACO数据集的发布对代码生成领域具有重要意义:
- 提供更高挑战性的基准: TACO测试集的高难度为评估和改进代码生成模型提供了新的标准。
- 促进模型能力的全面提升: 通过包含多样化的算法和编程技能,TACO有助于培养模型在实际编程场景中的综合能力。
- 支持精细化的模型训练: 细粒度的标签使研究人员能够针对特定难度或技能进行有针对性的模型优化。
- 推动代码生成技术的实际应用: TACO的问题更接近实际编程挑战,有助于缩小模型性能与实际应用需求之间的差距。
结语
TACO数据集的发布标志着算法代码生成领域迈出了重要一步。它不仅为研究人员提供了一个高质量、大规模的评估基准,还为提高代码生成模型的实际应用能力提供了宝贵的训练资源。随着TACO的广泛应用,我们有理由期待看到更多突破性的代码生成模型和技术的涌现,进一步推动人工智能辅助编程的发展。
研究人员和开发者可以通过GitHub仓库访问TACO项目,获取最新的数据集、评估工具和相关资源。同时,TACO团队也鼓励社区贡献者参与到数据集的改进和应用中来,共同推动代码生成技术的进步。









