
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文

TACO(算法代码生成数据集)
🤗 Hugging Face |  BAAI数据中心 | 论文
BAAI数据中心 | 论文
TACO (算法代码生成数据集) 是一个专注于算法代码生成的数据集,旨在为代码生成模型领域提供更具挑战性的训练数据集和评估基准。该数据集由更加困难且更贴近实际编程场景的编程竞赛问题组成。它强调在实际应用场景中提高或评估模型的理解和推理能力,而不仅仅是实现预定义的功能。
- 规模更大:TACO包含训练集(25,443个问题)和测试集(1,000个问题),是目前最大的代码生成数据集。
- 质量更高:TACO数据集中的每个问题都设计匹配多样化的解答,解答规模高达1.55M。这确保了模型在训练过程中不易过拟合,并验证了评估结果的有效性。
- 标签更细致:TACO数据集中的每个问题都包含细粒度的标签,如任务主题、算法、技能和难度级别。这些标签为代码生成模型的训练和评估提供了更准确的参考。
新闻和更新
-
🚀🚀🚀[2024/06/19] 宣布测试框架更新:修复错误并增强功能! 我们很高兴宣布在大量人工验证和调试努力后发布我们的第一个版本。在此更新中,我们解决了引用的APPS基准测试框架中的几个错误。我们重新检查了测试用例,并将TACO测试集更新到新版本。
有关修复的详细信息可以在这里找到。
-
🔥🔥🔥[2024/04/11] 宣布在Hugging Face上发布部分TACO(算法代码主题)项目模型! 我们对顶级代码模型如CodeLlama和Starcoder进行了全面微调,参数范围从1B到15B,专门针对竞争性算法挑战进行了定制。查看我们在Hugging Face上的FlagOpen下的模型。加入我们,推进代码和LLM社区的发展!🏋️♂️👩💻
下载和使用
首先,安装datasets包。
pip install -U datasets
然后,使用以下程序加载数据集。
from datasets import load_dataset
taco = load_dataset('BAAI/TACO', token=YOUR_HF_TOKEN)
- 您还可以通过以下方式指定拆分("train"或"test")
from datasets import load_dataset taco = load_dataset('BAAI/TACO', split='train', token=YOUR_HF_TOKEN) - 您还可以通过传递难度列表(从["EASY", "MEDIUM", "MEDIUM_HARD", "HARD", "VERY_HARD"]中选择,或默认为["ALL"])或技能列表(从["Data structures", "Sorting", "Range queries", "Complete search", "Amortized analysis", "Dynamic programming", "Bit manipulation", "Greedy algorithms"]中选择,或默认为["ALL"])来指定难度或技能。
from datasets import load_dataset taco_difficulties = load_dataset('BAAI/TACO', difficulties=['EASY'], token=YOUR_HF_TOKEN)from datasets import load_dataset taco_skills = load_dataset('BAAI/TACO', skills=['Sorting', 'Range queries'], token=YOUR_HF_TOKEN)
BAAI数据中心
首先,下载数据集并解压到名为"BAAI-TACO"的文件夹中。
然后,使用以下程序加载数据集。
from datasets import load_from_disk
taco = load_from_disk(PATH_TO_BAAI-TACO)
- 您还可以通过以下方式指定拆分("train"或"test")
from datasets import load_from_disk taco = load_from_disk(PATH_TO_BAAI-TACO)['train'] - 您还可以通过传递难度列表(从["EASY", "MEDIUM", "MEDIUM_HARD", "HARD", "VERY_HARD"]中选择,或默认为["ALL"])或技能列表(从["Data structures", "Sorting", "Range queries", "Complete search", "Amortized analysis", "Dynamic programming", "Bit manipulation", "Greedy algorithms"]中选择,或默认为["ALL"])来指定难度或技能。
from datasets import load_from_disk difficulties=['EASY'] taco = load_from_disk(PATH_TO_BAAI-TACO) taco_difficulties = taco.filter(lambda entry: entry['difficulty'] in difficulties)from datasets import load_from_disk skills=set(['Sorting', 'Range queries']) taco = load_from_disk(PATH_TO_BAAI-TACO) taco_skills = taco.filter(lambda entry: set(eval(entry['skill_types'])) & skills)
TACO的统计数据
| 比较维度 | TACO | CodeContest | APPS | HumanEval(/-X) | MBP(/X)P |
|---|---|---|---|---|---|
| 问题规模 (训练/开发/测试) | 25443/-/1000 | 13328/117/165 | 5000/-/5000 | -/-/164 | 374/-/500 |
| 测试集中无答案 | 0 | 43/165 | 1235/5000 | 0 | 0 |
| 重复问题 | 无重复 | 无重复 | 无重复 | 已删除重复 | 已删除重复 |
| 重复答案 | 已删除重复 | 无重复 | 无重复 | 已删除重复 | 已删除重复 |
| 每个问题的测试用例数 | 202.3 | 203.7 | 20.99 | 7.77 | 3 |
| 任务主题 | 有 | 有 | 无 | 无 | 无 |
| 算法标签 | 有 | 无 | 无 | 无 | 无 |
| 编程技能 | 有 | 无 | 无 | 无 | 无 |
| 难度标签 | 有 | 有 | 有 | 无 | 无 |
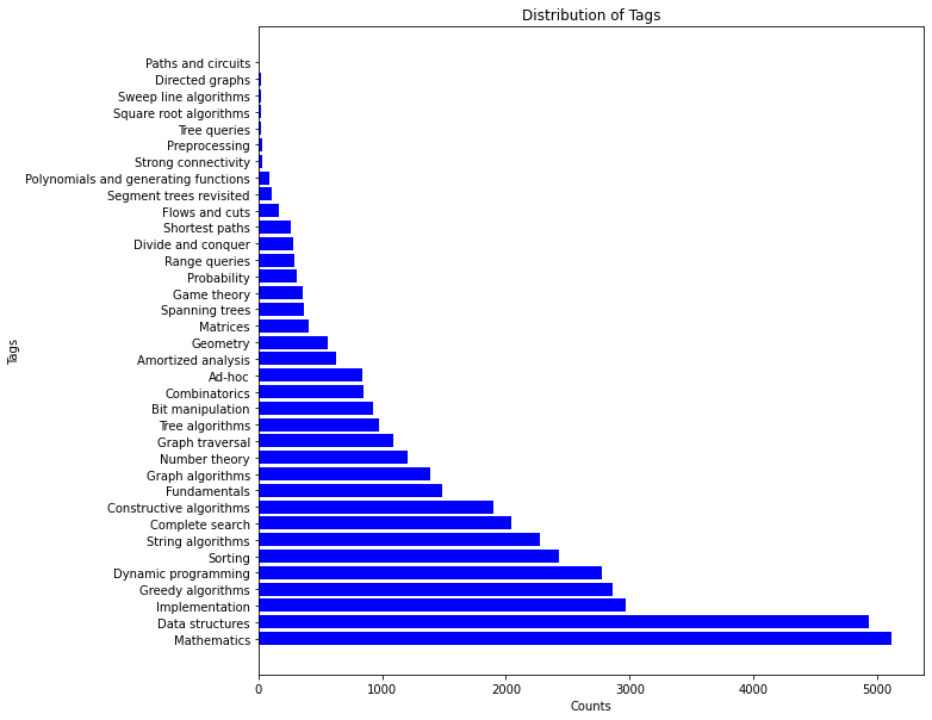
TACO中算法标签的分布如下:
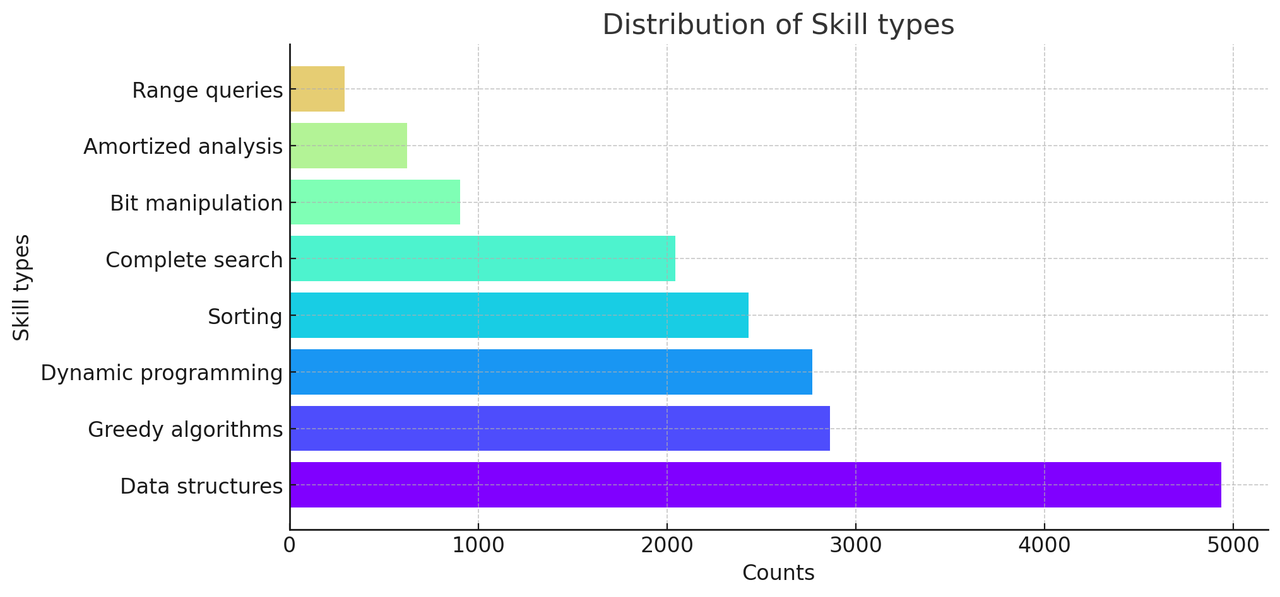
TACO中编程技能的分布如下:
使用TACO进行评估
首先,您应该初始化模型、分词器以及要使用的难度或技能来使用TACO。
# 初始化模型和分词器
model_name = 'codellama/CodeLlama-7b-hf'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
device = "cuda:0"
model = model.to(device)
# 初始化评估数据集
difficulties = ['ALL']
# difficulties = ["EASY", "MEDIUM", "MEDIUM_HARD", "HARD", "VERY_HARD"]
# skills = ['ALL']
# skills = ["Data structures", "Sorting", "Range queries", "Complete search", "Amortized analysis", "Dynamic programming", "Bit manipulation", "Greedy algorithms"]
from datasets import load_dataset
taco = load_dataset('BAAI/TACO', split='test', difficulties=difficulties)
# taco = load_dataset('BAAI/TACO', split='test', skills=skills)
然后,使用代码模型运行生成。
# 设置运行次数
n_samples = 200
temperature = 0.2
top_p = 0.95
output = []
for idx, sample in enumerate(taco):
prompt = sample['question']
results = {"task_id": idx, "prompt": prompt}
generations = []
for i in range(n_samples):
seed = i
generation = predict(device, model, tokenizer, prompt, seed, top_p, temperature, max_length=2048)
clean_code = truncate_after_eof_strings(generation)
generations.append(clean_code)
results["output"] = generations
output.append(results)
generation.py提供了使用CodeLlama生成TACO结果样本的完整示例,它输出一个JSON格式的文件generation.json。
[
{
"task_id": 0,
"prompt": "IT城市的城市公园包含n个从东到...",
"output": [
"\ndef solve(n):\n return n**5 - 10*n**4 + 40*n**3 ...",
"\ndef solve(n):\n return n**5 - 10*n**4 + 40*n**3 ...",
...
]
},
{
"task_id": "1",
"prompt": "动物园管理员正在购买一箱水果来喂养...",
"output": [
"\ndef solve(n, s):\n pre, suf, ans = [0]*n, [0]*n, ...",
"\ndef solve(n, s):\n pre, suf, ans = [0]*n, [0]*n, ...",
...
]
},
...
]
最后,执行生成的代码并计算指标。
compute_metric.py提供了使用上一步的generation.json进行代码执行和pass@k计算的完整示例。
结果文件 taco_metrics.json 的格式如下:
{
"pass@1": 0.0932,
"pass@10": 0.1515,
"pass@100": 0.1999,
"detail" : {
"pass@1": {
"0": ...,
"1": ...,
...
},
"pass@10": {
"0": ...,
"1": ...,
...
},
"pass@100": {
"0": ...,
"1": ...,
...
},
}
}
使用TACO进行微调
首先,你需要对TACO的训练集进行分词。我们提供了一个Python脚本 pretokenizing.py 和一个示例shell脚本 pretokenize.sh 来帮助你。这一步会在 cache_dir 目录下输出一个预分词的训练数据,文件名为 dataset_name。以下是使用CodeLlama-7b进行分词的示例:
python pretokenizing.py \
--tokenizer_dir codellama/CodeLlama-7b-hf \
--cache_dir . \
--dataset_name codellama_tokenized
然后,使用预分词的训练数据进行微调。我们提供了一个Python脚本 train.py 和一个示例shell脚本 finetune.sh 来帮助你。这一步会在 output_dir 目录下输出检查点。以下是微调CodeLlama-7b的示例:
torchrun --nproc_per_node=8 --nnodes=1 train.py \
--model_name_or_path codellama/CodeLlama-7b-hf \
--data_path codellama_tokenized \
--bf16 True \
--output_dir codellama_ft \
--num_train_epochs 2 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 500 \
--save_total_limit 1 \
--learning_rate 5e-5 \
--weight_decay 0.1 \
--warmup_ratio 0.1 \
--logging_steps 1 \
--resume_from_checkpoint True \
--gradient_checkpointing True \
--deepspeed ds_configs/deepspeed_z2_config_bf16.json
评估结果
我们使用TACO测试集和训练集对GPT-4以及一个在大量代码数据上训练的代码生成模型进行了实验。结果显示:
-
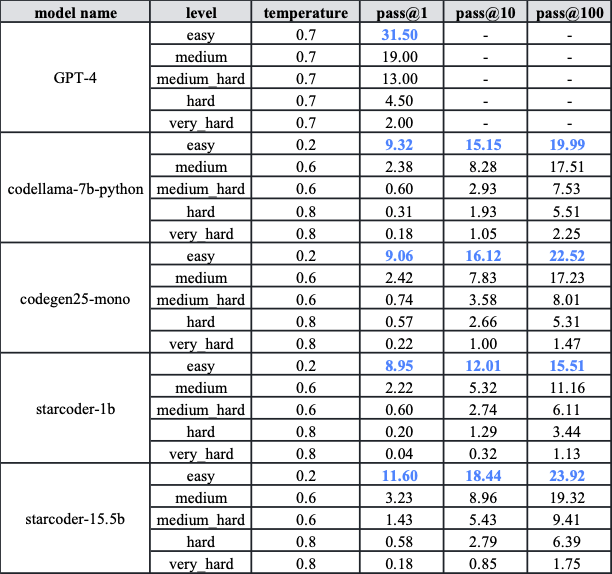
TACO测试集具有高度挑战性,GPT-4在简单级别上的pass@1分数仅为31.5。除GPT-4外,各种代码模型在五个难度级别上的pass@1分数普遍低于10。即使是pass@100的分数也不如GPT-4的pass@1高。
-
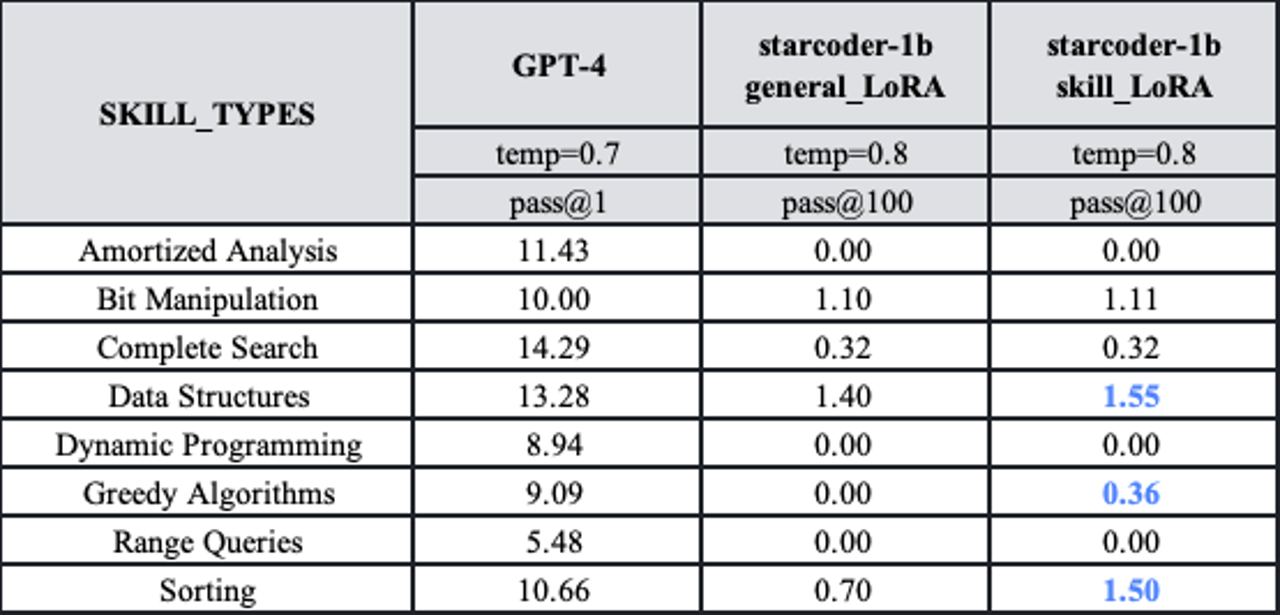
利用TACO训练集中的细粒度标签可以有选择地提高代码生成模型的性能。例如,在使用TACO训练集对starcoder-1b进行特定技能的微调后,性能有明显提升。
引用
如果您使用了本项目的模型、数据或代码,请引用原始论文:
@article{li2023taco,
title={TACO: Topics in Algorithmic COde generation dataset},
author={Rongao Li and Jie Fu and Bo-Wen Zhang and Tao Huang and Zhihong Sun and Chen Lyu and Guang Liu and Zhi Jin and Ge Li},
journal={arXiv preprint arXiv:2312.14852},
year={2023}
}
许可证
由北京智源人工智能研究院、山东师范大学和北京大学编写的TACO数据集根据Apache 2.0许可证发布。然而,数据集也包含了根据其他宽松许可证(如MIT许可证)授权的内容,或根据CC BY 4.0许可证(知识共享署名4.0国际许可证)条款使用的网络爬取数据。
我们衷心感谢以下贡献:
- 部分AtCoder、Codeforces、CodeWars、Kattis、LeetCode材料来自APPS数据集(https://github.com/hendrycks/apps)
- 部分Aizu、AtCoder、CodeChef、Codeforces材料来自CodeContest数据集(https://github.com/google-deepmind/code_contests)
- Codeforces材料来源于http://codeforces.com
- CodeChef材料来源于https://www.codechef.com
- GeekforGeeks材料来源于https://www.geeksforgeeks.org
- HackerEarth材料来自: Description2Code数据集, 根据MIT开源许可证授权,版权未指明。
- HackerRank材料来源于https://www.hackerrank.com。我们不了解HackerRank的法律权利或数据许可。如果有数据许可问题,请与我们联系。











