
Tango简介
Tango是由新加坡科技设计大学(SUTD)的研究团队开发的一种革命性的文本到音频生成技术。它基于潜在扩散模型(Latent Diffusion Model, LDM),结合了大型语言模型(Large Language Model, LLM)的强大文本理解能力和扩散模型的高质量生成能力,能够从文本描述生成逼真的音频,包括人声、动物声、自然声音、人工声音和音效等。
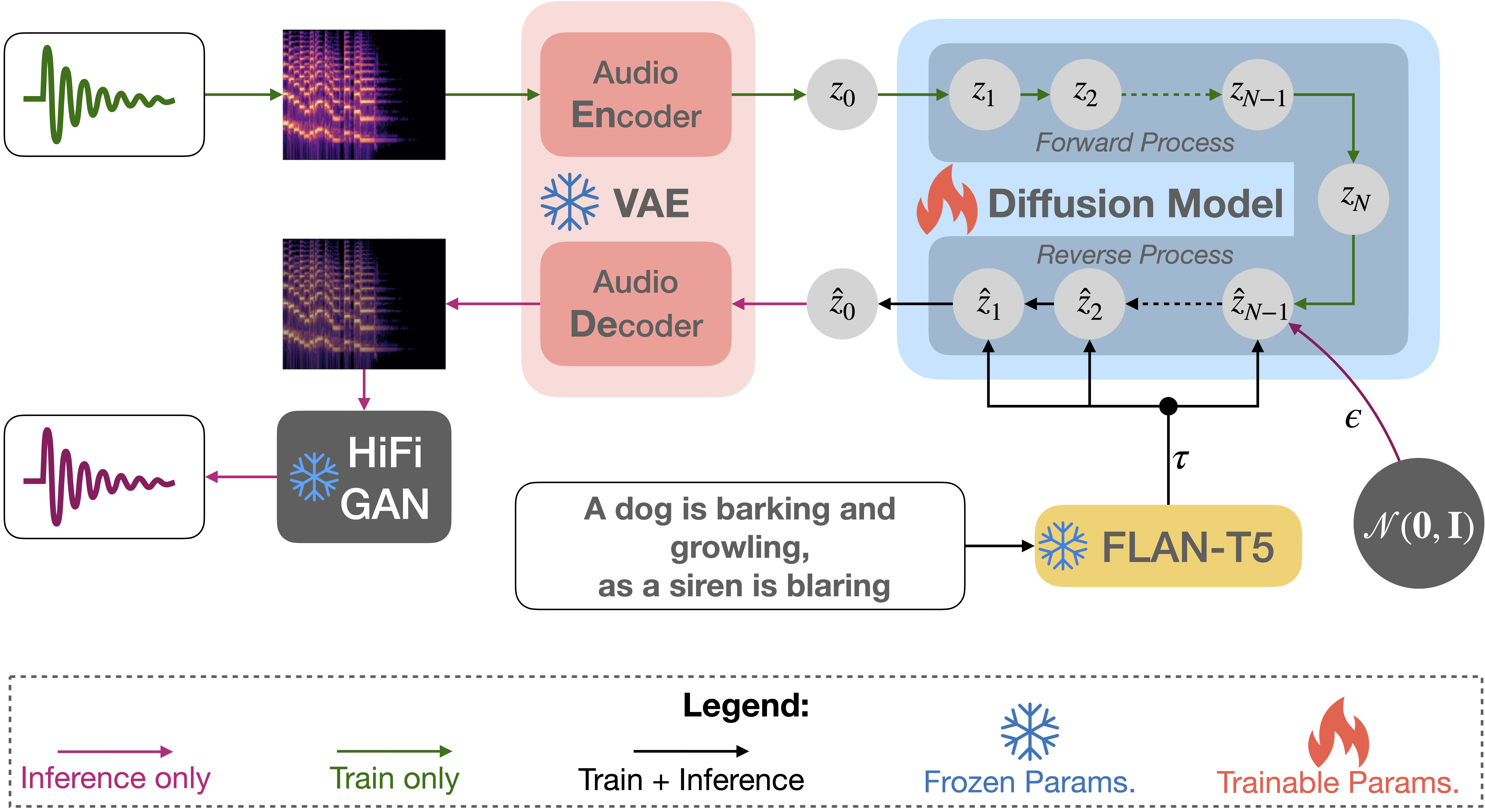
Tango的核心优势在于:
- 使用冻结的指令调优LLM(Flan-T5)作为文本编码器,提高了对文本提示的理解能力。
- 采用基于UNet的扩散模型进行音频生成,保证了生成音频的质量和多样性。
- 在较小的数据集上训练,但性能可与当前最先进的模型相媲美。
- 开源模型、训练和推理代码,推动了音频生成领域的研究进展。
Tango的发展历程
Tango 1.0
Tango的第一个版本在AudioCaps数据集上进行训练,主要聚焦于从文本生成通用的音频内容。它在客观和主观指标上都取得了不错的表现,特别是在保真度(FD)、KL散度(KL)和频谱特征距离(FAD)等指标上表现突出。
Tango 2.0
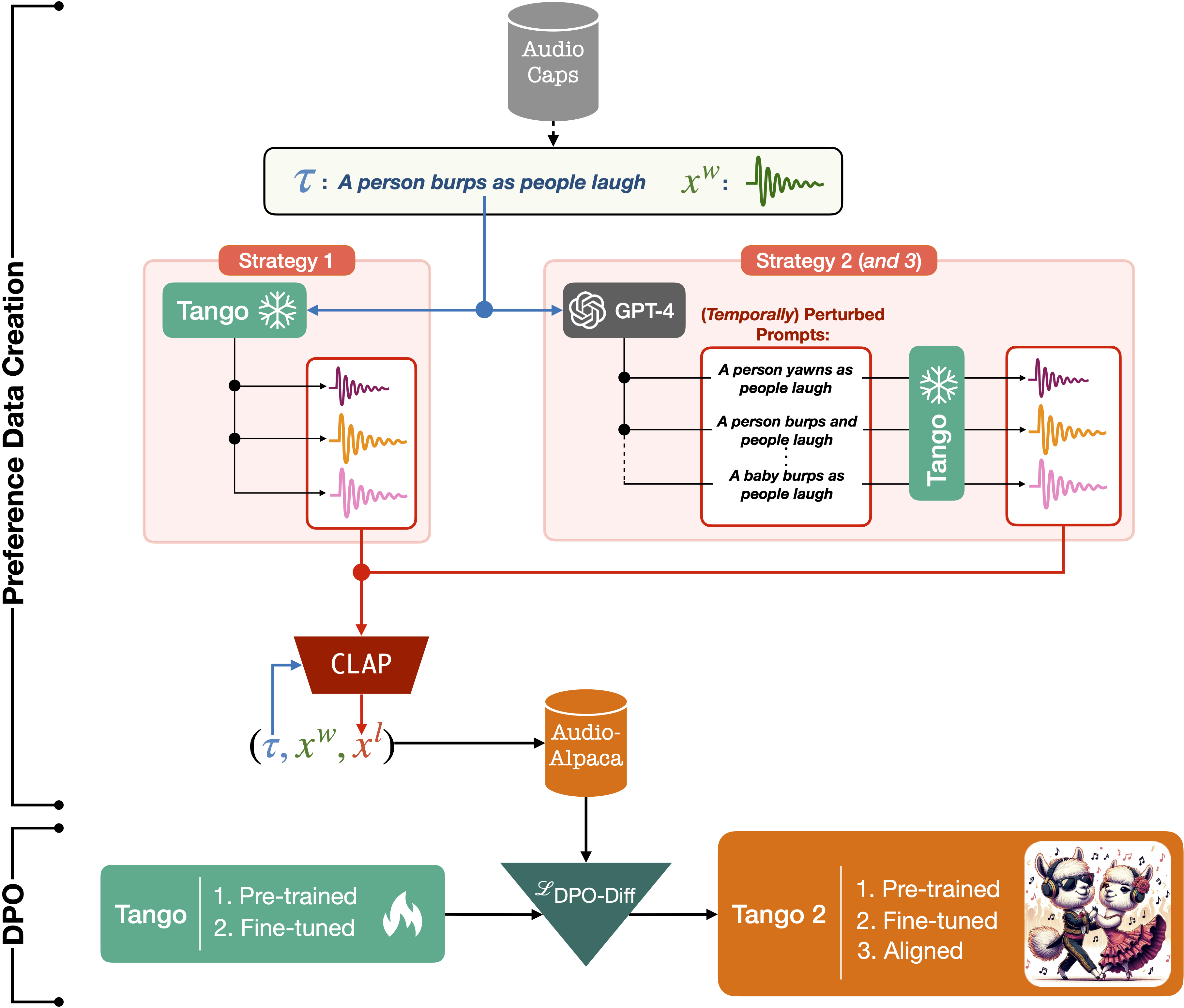
Tango 2.0是在Tango 1.0的基础上进行了进一步的改进和优化:
- 使用Tango-full-ft检查点进行初始化。
- 在Audio-alpaca数据集上进行对齐训练,这是一个包含约15,000个(提示,优选音频,非优选音频)三元组的成对偏好数据集。
- 采用直接偏好优化(Direct Preference Optimization, DPO)技术进行训练,提高了生成音频的质量和相关性。
Tango 2.0在多项指标上都取得了显著的进步,特别是在CLAP评分、整体质量(OVL)和相关性(REL)等方面表现优异。
Tango的技术原理
Tango的核心技术包括:
-
文本编码器:使用冻结的Flan-T5模型作为文本编码器,将文本提示转换为高维向量表示。
-
潜在扩散模型:采用UNet架构的扩散模型,在潜在空间中生成音频表示。
-
音频解码器:将潜在空间的表示解码为实际的音频波形。
-
对比语言-音频预训练(CLAP):用于评估生成音频与文本提示的相关性。
-
直接偏好优化(DPO):在Tango 2.0中引入,用于优化模型生成结果的质量和相关性。
Tango的应用场景
Tango在多个领域都有潜在的应用价值:
-
多媒体制作:为视频、游戏、动画等提供定制的音效和背景音乐。
-
辅助技术:为视障人士生成场景描述的音频。
-
教育培训:生成各种声音样本,用于语音识别、音乐理论学习等。
-
创意艺术:为艺术家提供新的音频创作工具。
-
虚拟现实(VR)和增强现实(AR):生成逼真的环境音效,提升沉浸感。
Tango的使用方法
快速开始
使用Tango生成音频非常简单。以下是一个基本示例:
import IPython
import soundfile as sf
from tango import Tango
tango = Tango("declare-lab/tango2")
prompt = "An audience cheering and clapping"
audio = tango.generate(prompt)
sf.write(f"{prompt}.wav", audio, samplerate=16000)
IPython.display.Audio(data=audio, rate=16000)
这段代码将自动下载Tango模型,并根据给定的文本提示生成相应的音频。
高级用法
- 批量生成:使用
generate_for_batch函数可以一次性生成多个音频样本:
prompts = [
"A car engine revving",
"A dog barks and rustles with some clicking",
"Water flowing and trickling"
]
audios = tango.generate_for_batch(prompts, samples=2)
- 调整采样步数:增加采样步数可以提高音频质量,但会增加运行时间:
audio = tango.generate(prompt, steps=200)
Tango的训练和微调
研究人员和开发者可以使用提供的训练脚本对Tango进行进一步的训练和微调:
- 基础训练:
accelerate launch train.py \
--text_encoder_name="google/flan-t5-large" \
--scheduler_name="stabilityai/stable-diffusion-2-1" \
--unet_model_config="configs/diffusion_model_config.json" \
--freeze_text_encoder --augment --snr_gamma 5
- 从预训练检查点继续训练:
accelerate launch train.py \
--hf_model "declare-lab/tango" \
--unet_model_config="configs/diffusion_model_config.json" \
--freeze_text_encoder --augment --snr_gamma 5
- Tango 2.0的训练:
accelerate launch tango2/tango2-train.py --hf_model "declare-lab/tango-full-ft-audiocaps" \
--unet_model_config="configs/diffusion_model_config.json" \
--freeze_text_encoder \
--learning_rate=9.6e-7 \
--num_train_epochs=5 \
--num_warmup_steps=200 \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--gradient_accumulation_steps=4 \
--beta_dpo=2000 \
--sft_first_epochs=1 \
--dataset_dir={PATH_TO_DOWNLOAD_WAV_FILE}
Tango的评估结果
Tango在多项客观和主观指标上都取得了优秀的表现:
| 模型 | 参数量 | FAD ↓ | KL ↓ | IS ↑ | CLAP ↑ | OVL ↑ | REL ↑ |
|---|---|---|---|---|---|---|---|
| AudioLDM 2-Full-Large | 712M | 2.11 | 1.54 | 8.29 | 0.44 | 3.56 | 3.19 |
| Tango-full-FT | 866M | 2.51 | 1.15 | 7.87 | 0.54 | 3.81 | 3.77 |
| Tango 2 | 866M | 2.69 | 1.12 | 9.09 | 0.57 | 3.99 | 4.07 |
从表中可以看出,Tango 2在多个指标上都优于其他模型,特别是在整体质量(OVL)和相关性(REL)方面表现突出。
Tango的未来发展
尽管Tango已经取得了显著的成果,但在音频生成领域仍有许多值得探索的方向:
-
多模态融合:结合视觉信息,实现更全面的场景理解和音频生成。
-
实时生成:优化模型性能,实现实时的文本到音频转换。
-
个性化定制:允许用户根据特定需求调整生成的音频风格和特征。
-
长时间音频生成:提高模型生成长时间、复杂结构音频的能力。
-
跨语言支持:扩展模型以支持多语言的文本到音频生成。
结论
Tango作为一种创新的文本到音频生成技术,展示了深度学习在音频领域的巨大潜力。通过结合大型语言模型和扩散模型的优势,Tango能够从简单的文本描述生成高质量、多样化的音频内容。随着技术的不断发展和完善,我们可以期待Tango在未来为更多领域带来创新和变革,为音频创作和应用开辟新的可能性。
研究者和开发者可以通过GitHub上的Tango项目获取更多信息,包括代码、模型和详细文档。随着开源社区的共同努力,我们相信Tango将继续推动文本到音频生成技术的边界,为人工智能和创意产业带来更多令人兴奋的应用。










