
引言
随着深度学习技术的快速发展,自然语言处理领域取得了长足的进步。其中,文本摘要作为一项重要的NLP任务,受到了研究人员的广泛关注。文本摘要旨在将长文本压缩成简短而信息丰富的摘要,可以帮助人们快速获取关键信息,提高信息处理效率。传统的文本摘要方法主要分为抽取式和生成式两类。抽取式方法通过选择原文中的重要句子或短语来构建摘要,而生成式方法则能够生成全新的摘要内容。近年来,随着Transformer模型的兴起,基于Transformer的抽象文本摘要方法取得了显著的进展,成为了该领域的研究热点。
本文将深入探讨Transformer模型在抽象文本摘要任务中的应用及最新进展。我们将从以下几个方面进行详细介绍:首先,概述Transformer模型的基本架构及其在文本摘要中的优势;其次,探讨预训练与微调策略在提升摘要质量中的作用;然后,分析数据处理和模型优化技巧;最后,总结当前研究中存在的挑战并展望未来发展方向。
Transformer模型架构
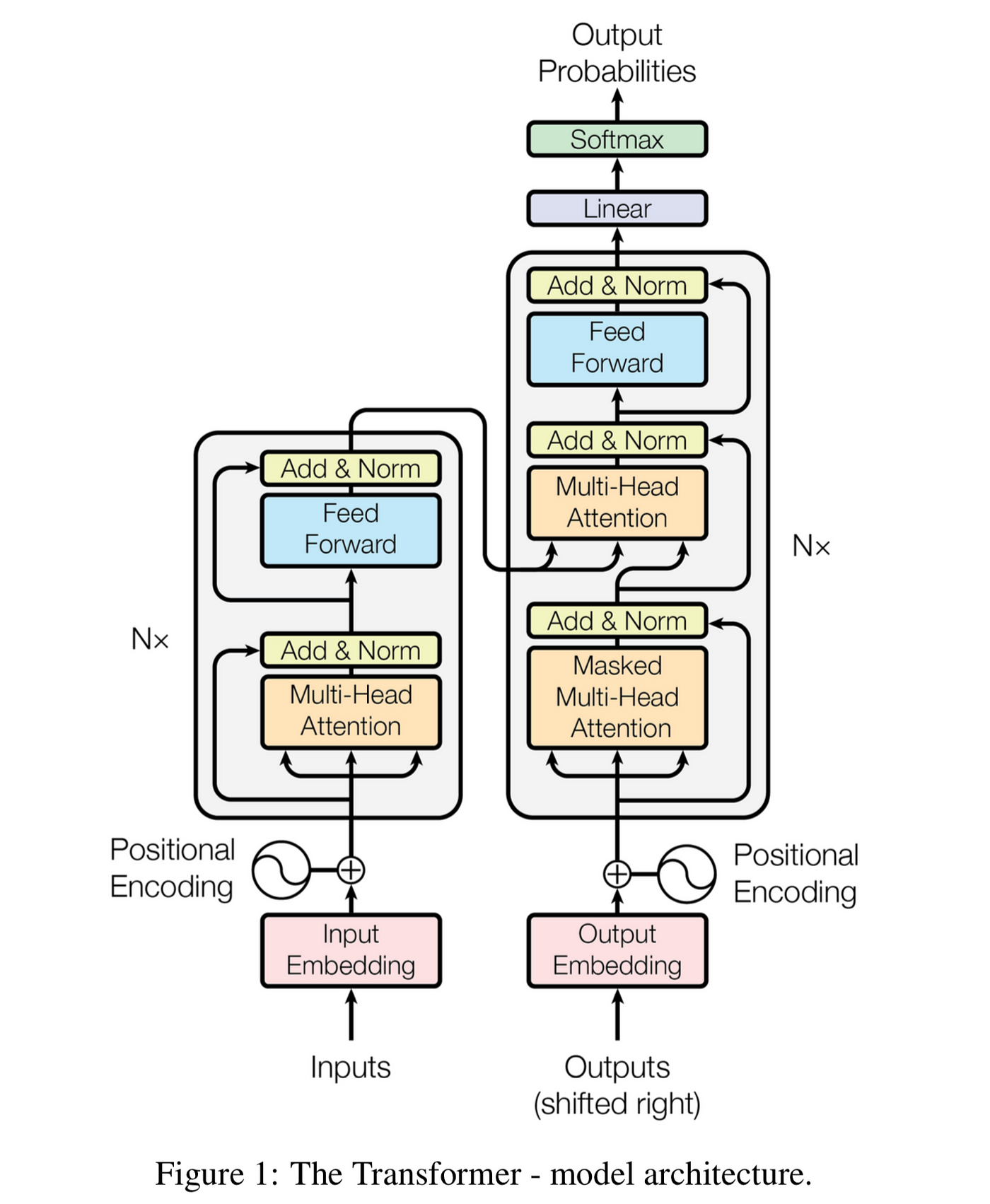
Transformer模型最初由Vaswani等人在2017年提出,其核心创新在于完全基于注意力机制的序列转换模型架构。相比传统的循环神经网络(RNN)和长短期记忆网络(LSTM),Transformer具有并行计算能力强、可捕获长距离依赖关系等优势,在多项NLP任务中取得了突破性进展。
自注意力机制
Transformer的核心组件是自注意力(Self-Attention)机制。它允许模型在处理序列数据时,动态计算序列中每个位置与其他所有位置的关联程度。具体来说,自注意力机制通过查询(Query)、键(Key)和值(Value)三个向量的交互来实现:
- 对输入序列中的每个元素,计算查询向量Q、键向量K和值向量V。
- 计算查询向量与所有键向量的点积,得到注意力分数。
- 对注意力分数进行softmax归一化,得到注意力权重。
- 将注意力权重与对应的值向量相乘并求和,得到该位置的输出表示。
这种机制使得模型能够灵活地关注到序列中的重要信息,有效地捕捉长距离依赖关系。
多头注意力
为了进一步增强模型的表达能力,Transformer引入了多头注意力(Multi-Head Attention)机制。多头注意力将输入投影到多个子空间,并在每个子空间中独立计算自注意力,最后将结果拼接起来。这种设计使得模型能够从不同的表示子空间中捕获diverse的信息,提高了特征提取的丰富性。
位置编码
由于Transformer模型不含有循环或卷积结构,无法天然地捕捉序列的顺序信息。为了解决这个问题,Transformer引入了位置编码(Positional Encoding)技术。位置编码通过给每个位置赋予一个唯一的向量表示,使得模型能够区分不同位置的信息。常用的位置编码方法包括正弦余弦函数编码和可学习的位置嵌入等。
编码器-解码器架构
在文本摘要任务中,Transformer通常采用编码器-解码器(Encoder-Decoder)架构。编码器负责将输入文本编码为隐藏表示,解码器则基于这些表示生成摘要。编码器和解码器均由多层Transformer块堆叠而成,每一层包含自注意力层、前馈神经网络层以及层标准化等组件。
预训练与微调策略
随着大规模预训练语言模型的兴起,研究人员发现将预训练模型应用于文本摘要任务能够显著提升性能。常见的策略包括:
-
直接微调:以BERT、RoBERTa等预训练模型作为编码器,随机初始化解码器,然后在摘要数据集上进行微调。
-
两阶段训练:先在大规模无标注语料上进行自监督预训练,如掩码语言模型(MLM)任务;然后在目标摘要数据集上进行有监督微调。
-
多任务学习:在微调阶段同时优化多个相关任务的目标函数,如摘要生成、关键词提取等,以增强模型的泛化能力。
-
连续学习:在多个领域或数据集上逐步微调模型,以适应不同类型的摘要任务。
研究表明,合理的预训练与微调策略能够显著提升摘要模型的性能。例如,Liu和Lapata(2019)提出的BERT-based Abstractive Summarization (BAS)模型,通过在CNN/Daily Mail数据集上微调预训练的BERT模型,取得了当时最先进的摘要效果。
数据处理与模型优化技巧
除了模型架构和训练策略,数据处理和模型优化技巧也在提升摘要质量中发挥着重要作用。以下是一些常用的技巧:
-
长文本处理:对于超长文档,可采用分块编码、滑动窗口等技术来处理超出模型最大输入长度的文本。
-
复制机制:引入指针网络(Pointer Network)等机制,允许模型直接从源文本中复制词语,有助于生成更准确的专有名词和罕见词。
-
覆盖度惩罚:通过引入覆盖度向量和相应的损失函数,鼓励模型关注尚未被摘要的源文本部分,减少重复生成问题。
-
强化学习:将ROUGE等评价指标作为奖励信号,通过策略梯度等方法直接优化这些非可微的目标。
-
对比学习:通过构造正负样本对,学习更具判别性的文本表示,提高摘要的相关性和连贯性。
-
知识融合:引入外部知识库或常识推理能力,增强模型对文本内容的理解和推理能力。
案例分析:PEGASUS模型
PEGASUS(Pre-training with Extracted Gap-sentences for Abstractive SUmmarization Sequence-to-sequence models)是Google Research在2020年提出的一个专门针对抽象摘要任务的预训练模型。该模型在大规模文本语料上通过模拟摘要任务进行自监督学习,展现了出色的few-shot学习能力。
PEGASUS的核心创新在于其预训练目标:Gap Sentence Generation (GSG)。具体来说,模型会从输入文档中选择一些重要句子移除,然后尝试重建这些句子。这种任务设计很好地模拟了真实的摘要过程,使得模型在预训练阶段就能学习到提取关键信息和生成摘要的能力。
在多个摘要数据集上的实验表明,PEGASUS在低资源场景下表现尤为出色。例如,在XSum数据集上,仅使用1000个训练样本就能达到与使用全量数据集(约20万样本)训练的BART模型相当的性能。这种高效的迁移学习能力,使PEGASUS在实际应用中具有很大的潜力。
存在的挑战与未来方向
尽管基于Transformer的抽象文本摘要方法取得了显著进展,但仍然存在一些挑战需要解决:
-
摘要的事实一致性:生成的摘要可能包含与原文不一致的事实,如何提高摘要的忠实度是一个重要问题。
-
长文本摘要:对于超长文档(如学术论文、技术报告等),如何有效处理和总结仍是一个挑战。
-
多模态摘要:如何结合图像、视频等多模态信息进行更全面的摘要生成。
-
可解释性和可控性:如何增强模型的可解释性,并允许用户控制摘要的风格、长度等属性。
-
评价指标:现有的自动评价指标(如ROUGE)存在局限性,如何更准确地评估摘要质量仍需探索。
-
计算效率:大型Transformer模型的训练和推理成本较高,如何提高模型效率是一个重要方向。
针对这些挑战,未来的研究可能会朝以下方向发展:
-
结合知识图谱和常识推理,提高摘要的准确性和一致性。
-
开发更高效的长文本处理技术,如层次化编码、稀疏注意力等。
-
探索跨模态预训练和迁移学习方法,实现更全面的信息摘要。
-
引入可解释的注意力机制和可控生成技术,增强模型的透明度和灵活性。
-
设计更合理的自动评价指标,并结合人工评估方法。
-
研究模型压缩、知识蒸馏等技术,提高模型的效率。
结论
Transformer模型凭借其强大的特征提取能力和灵活的架构设计,在抽象文本摘要任务中展现出了巨大的潜力。通过合理的预训练策略、精细的模型优化和创新的应用方法,研究人员不断推动着这一领域的发展。虽然仍面临一些挑战,但我们有理由相信,随着技术的不断进步,基于Transformer的抽象文本摘要方法将在信息处理和知识管理领域发挥越来越重要的作用。
未来,随着大规模语言模型的持续演进和多模态技术的融合,我们有望看到更智能、更精确、更贴近人类认知的自动摘要系统。这不仅将极大地提高信息获取和处理的效率,也可能为人工智能理解和生成自然语言的研究带来新的突破。
参考文献
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
-
Liu, Y., & Lapata, M. (2019). Text summarization with pretrained encoders. arXiv preprint arXiv:1908.08345.
-
Zhang, J., Zhao, Y., Saleh, M., & Liu, P. (2020). Pegasus: Pre-training with extracted gap-sentences for abstractive summarization. In International Conference on Machine Learning (pp. 11328-11339). PMLR.
-
Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., ... & Zettlemoyer, L. (2020). Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461.
-
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., ... & Liu, P. J. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140), 1-67.


















