
TTTS: 下一代文本转语音系统的训练框架
在人工智能和语音合成技术飞速发展的今天,一个名为TTTS(Train the next generation of TTS systems)的开源项目正在为下一代文本转语音(TTS)系统的开发铺平道路。该项目由GitHub用户adelacvg创建并维护,旨在通过结合多种先进技术来训练更加自然、灵活的TTS模型。
创新的方法与架构
TTTS的核心创新在于其独特的建模方法。项目创始人表示,TTTS是首个采用这种方法的TTS框架。其主要思想源于对音频"细节"的建模,这解决了基于矢量量化(VQ)方法在音频重建方面的局限性。
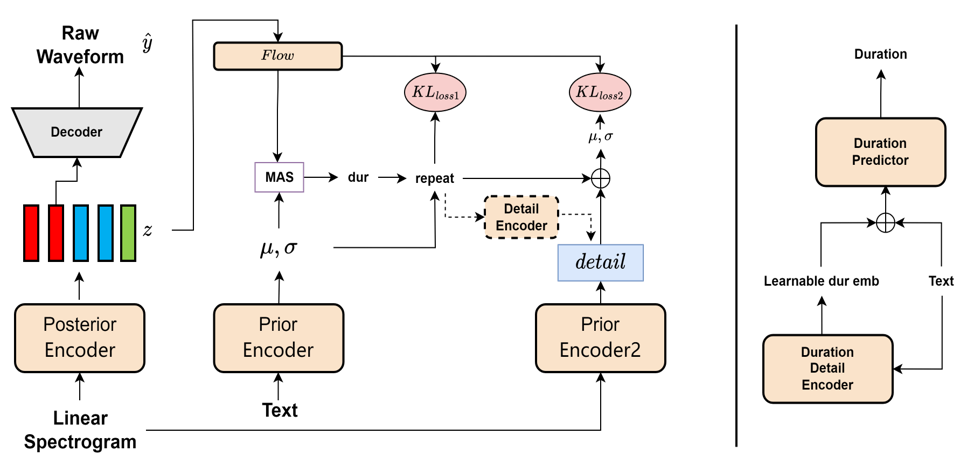
如上图所示,TTTS的架构包含了多个关键组件,包括:
- 文本编码器:将输入文本转换为语音特征表示
- VQVAE(Vector Quantized Variational Autoencoder):用于音频编码和解码
- 扩散模型:生成高质量的语音波形
- 多任务学习模块:优化模型在多个相关任务上的性能
这种创新架构使TTTS能够在保持高质量音频输出的同时,实现更灵活的语音合成。
多语言支持
TTTS的一大特色是其广泛的多语言支持。目前,该框架已经支持中文、英文、日语和韩语,并且可以通过简单的两步过程扩展到任何其他语言:
- 收集目标语言的大量文本数据
- 使用这些数据训练
ttts/gpt/voice_tokenizer模块,生成该语言的字典
对于不同语言,TTTS采用了灵活的处理方式。例如,英语可以直接使用原文,而中文需要转换为拼音,日语则需要转换为罗马字。这种方法确保了发音信息能够准确地包含在文本中。
训练与微调
TTTS的训练过程主要包括两个阶段:
-
分词器训练:使用
ttts/prepare/bpe_all_text_to_one_file.py合并所有收集的文本,然后训练分词器。 -
VQVAE训练:使用
1_vad_asr_save_to_jsonl.py和2_romanize_text.py预处理数据集,然后运行:accelerate launch ttts/vqvae/train_v3.py
对于模型微调,用户可以通过修改train_v3.py中的加载路径来使用预训练模型,然后继续训练。数据预处理步骤可以参考ttts/prepare/2_romanize_text.py。
推理与应用
TTTS提供了简单易用的API接口,方便开发者将其集成到各种应用中。详细的推理过程可以在项目的api.py文件中找到。此外,项目还提供了一个Jupyter Notebook演示,可以在Google Colab上直接运行,让用户快速体验TTTS的功能。
开源社区与未来发展
作为一个开源项目,TTTS得到了GitHub社区的广泛关注。截至目前,该项目已获得159颗星和16次分叉,显示出其在TTS领域的潜力和影响力。项目采用MPL-2.0许可证,鼓励更多开发者参与贡献和改进。
TTTS的创新性和灵活性为下一代TTS系统的发展指明了方向。随着人工智能和深度学习技术的不断进步,我们可以期待TTTS在未来会带来更多令人兴奋的功能和性能提升。无论是在学术研究还是实际应用中,TTTS都将是一个值得关注的重要项目。
总结
TTTS作为一个创新的TTS训练框架,通过其独特的架构设计和多语言支持,为下一代语音合成技术的发展提供了新的可能性。它不仅解决了传统方法中的一些局限性,还为研究人员和开发者提供了一个灵活、强大的工具。随着项目的不断发展和社区的积极参与,我们有理由相信TTTS将在TTS领域发挥越来越重要的作用,推动语音交互技术向着更自然、更智能的方向前进。


















