
检索增强生成(RAG)技术概述
检索增强生成(Retrieval-Augmented Generation, RAG)是一种新兴的人工智能技术,旨在通过结合外部知识来增强大型语言模型(LLM)的能力。RAG技术的核心思想是在生成回答之前,先从外部数据源中检索相关信息,然后将检索到的信息与用户的问题一起输入到语言模型中,从而生成更准确、更及时、更全面的回答。
RAG技术主要解决了传统大型语言模型面临的三个主要问题:
-
准确性:通过限制模型使用已知的可靠数据集,RAG可以提高回答的准确性,减少"幻觉"的产生。
-
时效性:通过引入最新的外部数据,RAG可以生成更加及时和up-to-date的回答。
-
完整性:通过纳入组织的专有数据,RAG可以回答特定领域或业务相关的问题。

RAG管道的工作原理
一个典型的RAG管道通常包含以下几个关键组件:
-
数据仓库:包含与问答任务相关的各种数据源,如文档、表格等。
-
向量检索:给定一个问题,找出与问题最相似的前K个数据块。这通常通过向量数据库(如Faiss)来实现。
-
响应生成:将检索到的前K个最相似的数据块作为上下文,使用大型语言模型(如GPT-4)生成最终回答。
RAG管道的核心秘诀在于,每个组件都由一个精心设计的提示模板驱动的单个LLM调用来实现。整个管道本质上是一系列具有特定提示模板的LLM调用。这些提示模板是使RAG管道能够执行复杂任务的关键。
构建高级RAG管道
以子问题查询引擎为例,我们可以将其分解为三个主要任务:
-
子问题生成:将复杂问题分解为一系列子问题,并为每个子问题确定适当的数据源和检索函数。
-
向量/摘要检索:对每个子问题使用选定的检索函数从相应数据源中检索相关信息。
-
响应聚合:将子问题的回答聚合成最终响应。
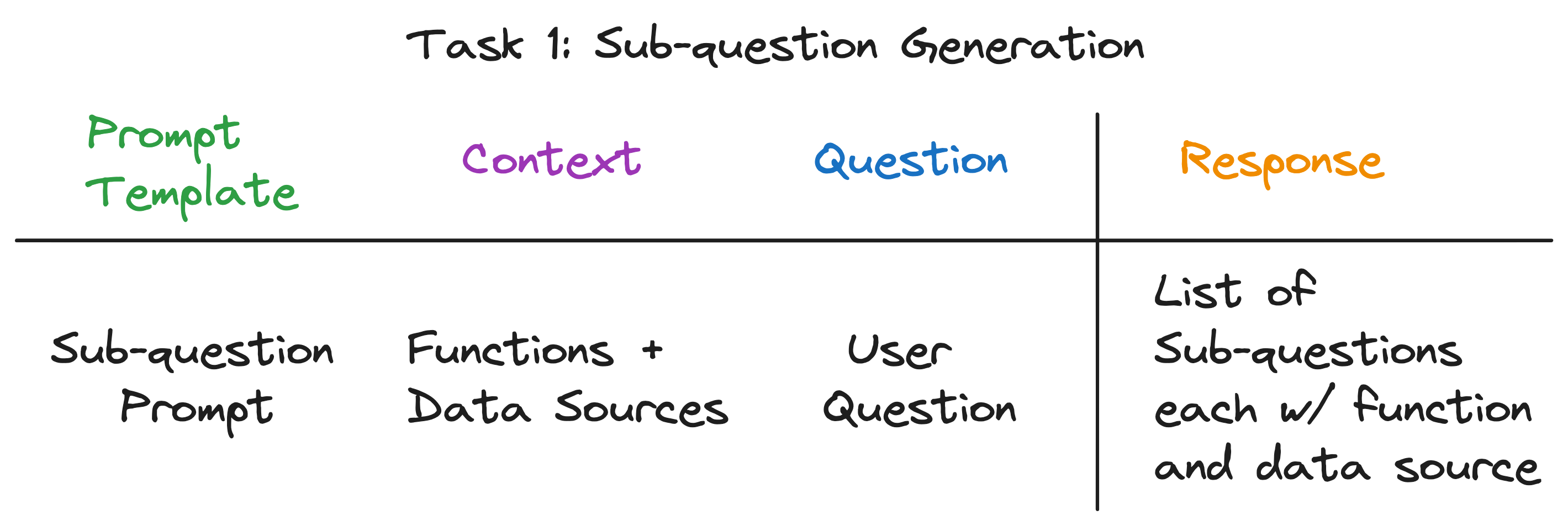
子问题生成
子问题生成任务通过一个精心设计的"子问题提示模板"来实现:
你是一个专门将复杂问题分解为更简单、可管理的子问题的AI助手。
当遇到复杂的用户问题时,你的任务是生成一系列子问题,这些子问题在回答后将全面解答原始问题。
你可以使用预定义的一组函数和数据源来回答每个子问题。
如果用户问题很直接,你的任务是返回原始问题,并确定用于解决它的适当函数和数据源。
请记住,你只能使用提供的函数和数据源,每个子问题都应该是一个完整的问题,可以使用单个函数和单个数据源来回答。
向量/摘要检索
对于每个子问题,我们使用选定的检索函数从相应的数据源中检索相关信息。这一步骤使用了流行的RAG提示模板:
你是一个问答任务的助手。使用以下检索到的上下文来回答问题。如果你不知道答案,就说你不知道。最多使用三个句子,保持答案简洁。
问题: {question}
上下文: {context}
回答:

响应聚合
这是将子问题的回答聚合成最终响应的最后一步。同样,RAG提示模板在这一步骤中也表现出色。

RAG技术面临的挑战
尽管RAG技术带来了许多优势,但它也面临一些挑战:
-
问题敏感性:LLM对用户问题极为敏感,管道可能会对某些用户问题出现意外失败。例如:
- 生成不正确的子问题
- 选择错误的检索函数
-
成本:RAG管道的最终成本取决于生成的子问题数量、使用的检索函数以及查询的数据源数量。由于LLM对提示敏感,问题的成本可能会因问题和LLM输出而显著变化。
结论
检索增强生成(RAG)技术为构建更强大、更可靠的问答系统开辟了新的可能性。通过将外部知识与大型语言模型的能力相结合,RAG能够生成更准确、更及时、更全面的回答。然而,正如我们所看到的,RAG并非万能解决方案。它依赖于精心设计的提示模板和多个链式LLM调用,可能对问题敏感,且在成本动态方面不够透明。
理解RAG的内部工作原理对于充分发挥其潜力至关重要。随着技术的不断发展,我们可以期待看到更加健壮和高效的RAG系统的出现,这将进一步推动人工智能问答技术的进步。
对于希望实践RAG技术的开发者,本文介绍的rag-demystified项目提供了一个很好的起点。通过深入研究该项目的代码实现,你可以更好地理解RAG管道的各个组成部分,并探索如何将RAG技术应用到自己的项目中。
随着人工智能技术的不断进步,我们可以预见RAG将在未来的智能问答系统中扮演越来越重要的角色。通过不断优化和改进RAG技术,我们有望构建出更加智能、更加可靠的AI系统,为用户提供更优质的问答体验。










