
USLM模型简介
USLM (Unified Speech Language Model) 是由复旦大学研究团队开发的一个创新性统一语音语言模型。它建立在SpeechTokenizer的基础之上,通过结合自回归(AR)和非自回归(NAR)模型,实现了对语音信息的分层建模。这种独特的架构设计使USLM能够更全面地捕捉语音中的内容信息和副语言信息,为语音识别、合成等任务带来了新的可能性。
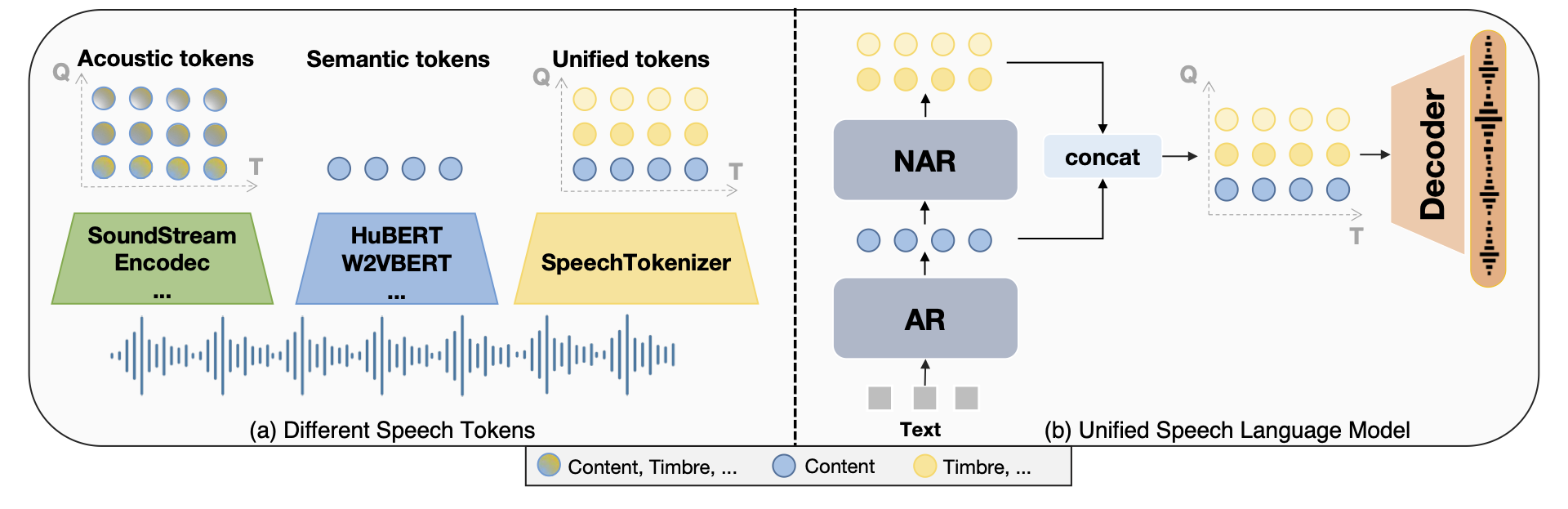
如上图所示,USLM模型的核心思想是分层建模语音信息。自回归(AR)模型主要负责捕捉语音内容信息,它通过对第一个RVQ量化器生成的token进行建模来实现这一目标。而非自回归(NAR)模型则专注于补充副语言信息,它基于第一层token的条件,生成后续量化器的token。这种分层设计使得USLM能够更加全面和细致地理解和生成语音信息。
USLM的技术特点
-
分层建模: USLM通过AR和NAR模型的结合,实现了对语音内容和副语言信息的分层建模,这使得模型能够更全面地理解语音数据。
-
灵活性: 模型架构的设计允许在不同任务中灵活调整AR和NAR模型的比重,以适应不同的应用场景。
-
可扩展性: USLM的设计理念使其易于扩展到更大规模的数据集和更复杂的任务上。
-
效率: 通过并行处理和优化的算法,USLM在保证性能的同时也提高了计算效率。
USLM的安装与使用
要开始使用USLM,您需要按照以下步骤进行安装:
- 首先,安装PyTorch和相关依赖:
pip install torch==1.13.1 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install torchmetrics==0.11.1
pip install librosa==0.8.1
- 安装语音处理相关的库:
apt-get install espeak-ng
pip install phonemizer==3.2.1 pypinyin==0.48.0
- 安装最新版本的lhotse:
pip uninstall lhotse
pip install git+https://github.com/lhotse-speech/lhotse
- 安装k2库:
pip install https://huggingface.co/csukuangfj/k2/resolve/main/cuda/k2-1.23.4.dev20230224+cuda11.6.torch1.13.1-cp310-cp310-linux_x86_64.whl
- 安装icefall:
git clone https://github.com/k2-fsa/icefall
cd icefall
pip install -r requirements.txt
export PYTHONPATH=`pwd`/../icefall:$PYTHONPATH
echo "export PYTHONPATH=`pwd`/../icefall:\$PYTHONPATH" >> ~/.zshrc
echo "export PYTHONPATH=`pwd`/../icefall:\$PYTHONPATH" >> ~/.bashrc
cd -
source ~/.zshrc
- 安装SpeechTokenizer和USLM:
pip install -U speechtokenizer
git clone https://github.com/0nutation/USLM
cd USLM
pip install -e .
完成上述步骤后,您就可以开始使用USLM进行各种语音处理任务了。
USLM在零样本文本转语音中的应用
USLM在零样本文本转语音(Zero-shot TTS)任务中展现出了强大的能力。以下是使用USLM进行零样本TTS的步骤:
- 下载预训练的SpeechTokenizer模型:
st_dir="ckpt/speechtokenizer/"
mkdir -p ${st_dir}
cd ${st_dir}
wget "https://huggingface.co/fnlp/SpeechTokenizer/resolve/main/speechtokenizer_hubert_avg/SpeechTokenizer.pt"
wget "https://huggingface.co/fnlp/SpeechTokenizer/resolve/main/speechtokenizer_hubert_avg/config.json"
cd -
- 下载预训练的USLM模型:
uslm_dir="ckpt/uslm/"
mkdir -p ${uslm_dir}
cd ${uslm_dir}
wget "https://huggingface.co/fnlp/USLM/resolve/main/USLM_libritts/USLM.pt"
wget "https://huggingface.co/fnlp/USLM/resolve/main/USLM_libritts/unique_text_tokens.k2symbols"
cd -
- 运行推理脚本:
out_dir="output/"
mkdir -p ${out_dir}
python3 bin/infer.py --output-dir ${out_dir}/ \
--model-name uslm --norm-first true --add-prenet false \
--share-embedding true --norm-first true --add-prenet false \
--audio-extractor SpeechTokenizer \
--speechtokenizer-dir "${st_dir}" \
--checkpoint=${uslm_dir}/USLM.pt \
--text-tokens "${uslm_dir}/unique_text_tokens.k2symbols" \
--text-prompts "mr Soames was a tall, spare man, of a nervous and excitable temperament." \
--audio-prompts prompts/1580_141083_000002_000002.wav \
--text "Begin with the fundamental steps of the process. This will give you a solid foundation to build upon and boost your confidence. "
通过上述步骤,USLM能够生成高质量的语音输出,即使对于未见过的文本和说话人也能取得不错的效果。
USLM的未来发展方向
尽管USLM已经展现出了强大的能力,但研究团队表示,目前的版本主要在LibriTTS数据集上进行了训练,因此在某些方面的表现可能还不够optimal。未来,USLM的发展方向可能包括:
-
扩大训练数据集: 使用更大规模、更多样化的语音数据集进行训练,以提升模型的泛化能力。
-
优化模型架构: 进一步改进AR和NAR模型的设计,提高模型的性能和效率。
-
多语言支持: 扩展USLM以支持更多语言,使其成为一个真正的多语言语音处理模型。
-
实时处理: 优化模型推理速度,使USLM能够支持实时语音处理任务。
-
应用拓展: 探索USLM在更多语音相关任务中的应用,如语音翻译、多说话人分离等。
总结
USLM作为一个创新的统一语音语言模型,通过其独特的分层建模方法,为语音处理领域带来了新的可能性。它不仅在零样本文本转语音等任务中表现出色,还为未来更多语音相关应用的发展奠定了基础。随着研究的深入和技术的不断优化,我们可以期待USLM在语音识别、合成、翻译等多个领域发挥更大的作用,推动语音处理技术的进步。
对于研究人员和开发者来说,USLM提供了一个强大而灵活的工具,可以用于探索和开发各种创新的语音应用。通过GitHub上的开源代码和详细文档,任何人都可以轻松地开始使用USLM,并为其发展做出贡献。
在人工智能和语音技术快速发展的今天,USLM无疑是一个值得关注的项目。它不仅代表了语音处理技术的最新进展,也为未来更智能、更自然的人机交互铺平了道路。随着更多研究者和开发者的加入,我们有理由相信USLM将继续evolve,为语音技术的未来带来更多惊喜。
参考链接
通过深入了解和使用USLM,我们不仅能够掌握最新的语音处理技术,还能为未来更智能、更自然的人机交互贡献自己的力量。无论您是研究人员、开发者还是对语音技术感兴趣的爱好者,USLM都为您提供了一个极具潜力的平台,让我们一起探索语音技术的无限可能吧! 🎙️🤖💬









