
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文USLM: 统一语音语言模型
简介
USLM基于SpeechTokenizer构建,包含自回归和非自回归模型,可以分层建模语音中的信息。自回归(AR)模型通过对第一个RVQ量化器的标记进行建模来捕捉内容信息。非自回归(NAR)模型通过基于第一层标记生成后续量化器的标记来为AR模型补充副语言信息。
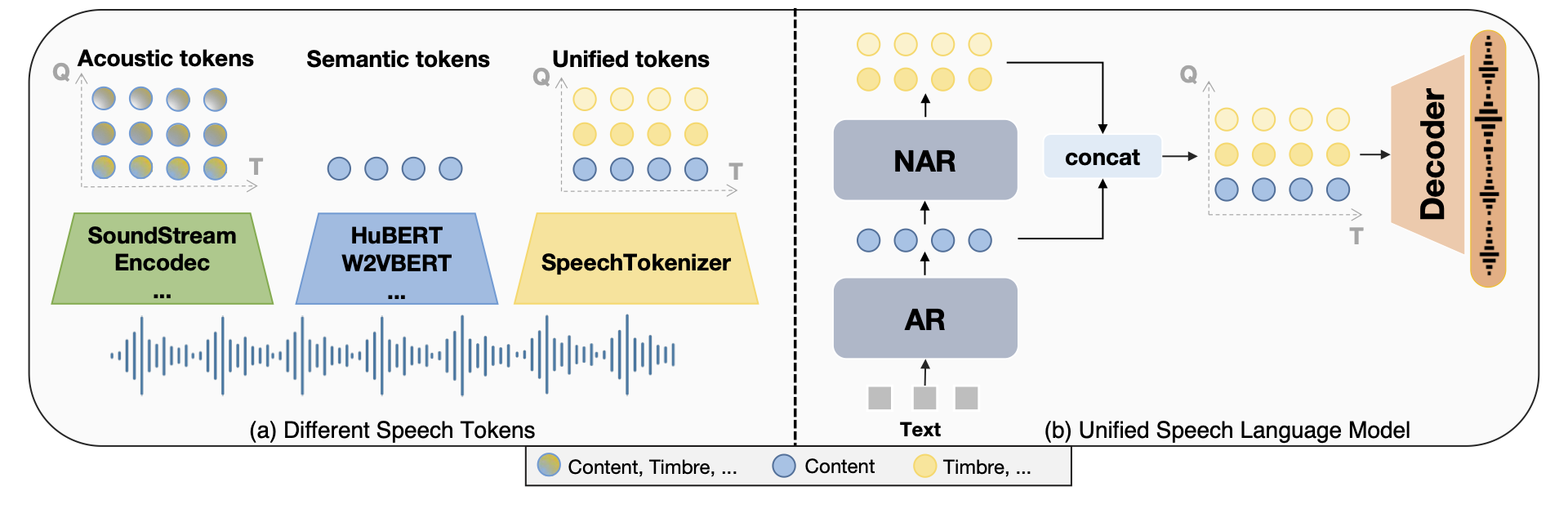
概览
安装
按照以下步骤快速开始:
# PyTorch
pip install torch==1.13.1 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install torchmetrics==0.11.1
# fbank
pip install librosa==0.8.1
# phonemizer pypinyin
apt-get install espeak-ng
## OSX: brew install espeak
pip install phonemizer==3.2.1 pypinyin==0.48.0
# lhotse更新至最新版本
# https://github.com/lhotse-speech/lhotse/pull/956
# https://github.com/lhotse-speech/lhotse/pull/960
pip uninstall lhotse
pip install git+https://github.com/lhotse-speech/lhotse
# k2
# 在https://huggingface.co/csukuangfj/k2找到正确版本
pip install https://huggingface.co/csukuangfj/k2/resolve/main/cuda/k2-1.23.4.dev20230224+cuda11.6.torch1.13.1-cp310-cp310-linux_x86_64.whl
# icefall
git clone https://github.com/k2-fsa/icefall
cd icefall
pip install -r requirements.txt
export PYTHONPATH=`pwd`/../icefall:$PYTHONPATH
echo "export PYTHONPATH=`pwd`/../icefall:\$PYTHONPATH" >> ~/.zshrc
echo "export PYTHONPATH=`pwd`/../icefall:\$PYTHONPATH" >> ~/.bashrc
cd -
source ~/.zshrc
#SpeechTokenizer
pip install -U speechtokenizer
# uslm
git clone https://github.com/0nutation/USLM
cd USLM
pip install -e .
USLM模型
此版本的USLM在LibriTTS数据集上训练,由于数据限制,性能可能不是最优的。
| 模型 | 数据集 | 描述 |
|---|---|---|
| USLM_libri | LibriTTS | 在LibriTTS数据集上训练的USLM |
使用USLM进行零样本TTS
下载预训练的SpeechTokenizer模型:
st_dir="ckpt/speechtokenizer/"
mkdir -p ${st_dir}
cd ${st_dir}
wget "https://huggingface.co/fnlp/SpeechTokenizer/resolve/main/speechtokenizer_hubert_avg/SpeechTokenizer.pt"
wget "https://huggingface.co/fnlp/SpeechTokenizer/resolve/main/speechtokenizer_hubert_avg/config.json"
cd -
下载预训练的USLM模型:
uslm_dir="ckpt/uslm/"
mkdir -p ${uslm_dir}
cd ${uslm_dir}
wget "https://huggingface.co/fnlp/USLM/resolve/main/USLM_libritts/USLM.pt"
wget "https://huggingface.co/fnlp/USLM/resolve/main/USLM_libritts/unique_text_tokens.k2symbols"
cd -
推理:
out_dir="output/"
mkdir -p ${out_dir}
python3 bin/infer.py --output-dir ${out_dir}/ \
--model-name uslm --norm-first true --add-prenet false \
--share-embedding true --norm-first true --add-prenet false \
--audio-extractor SpeechTokenizer \
--speechtokenizer-dir "${st_dir}" \
--checkpoint=${uslm_dir}/USLM.pt \
--text-tokens "${uslm_dir}/unique_text_tokens.k2symbols" \
--text-prompts "mr Soames was a tall, spare man, of a nervous and excitable temperament." \
--audio-prompts prompts/1580_141083_000002_000002.wav \
--text "Begin with the fundamental steps of the process. This will give you a solid foundation to build upon and boost your confidence. " \
或者你可以直接运行inference.sh
bash inference.sh
致谢
VALL-E:我们基于的代码库。
引用
如果你在论文中使用了这个代码或结果,请引用我们的工作:
@misc{zhang2023speechtokenizer,
title={SpeechTokenizer: Unified Speech Tokenizer for Speech Language Models},
author={Xin Zhang and Dong Zhang and Shimin Li and Yaqian Zhou and Xipeng Qiu},
year={2023},
eprint={2308.16692},
archivePrefix={arXiv},
primaryClass={cs.CL}
}











