
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文SpeechTokenizer:语音语言模型的统一语音标记器
简介
这是SpeechTokenizer:语音语言模型的统一语音标记器中提出的SpeechTokenizer的代码。SpeechTokenizer是一个用于语音语言模型的统一语音标记器,它采用了带有残差向量量化(RVQ)的编码器-解码器架构。SpeechTokenizer统一了语义和声学标记,在不同的RVQ层次中分层解耦了语音信息的不同方面。具体来说,RVQ第一个量化器输出的代码索引可以被视为语义标记,而其余量化器的输出主要包含音色信息,作为第一个量化器丢失信息的补充。我们提供了以下模型:
- 一个在Librispeech上训练的16khz单声道语音模型,以所有HuBERT层的平均表示作为语义教师。
- 一个使用Snake激活函数的16khz单声道语音模型,在Librispeech和Common Voice上训练,以所有HuBERT层的平均表示作为语义教师。

概览
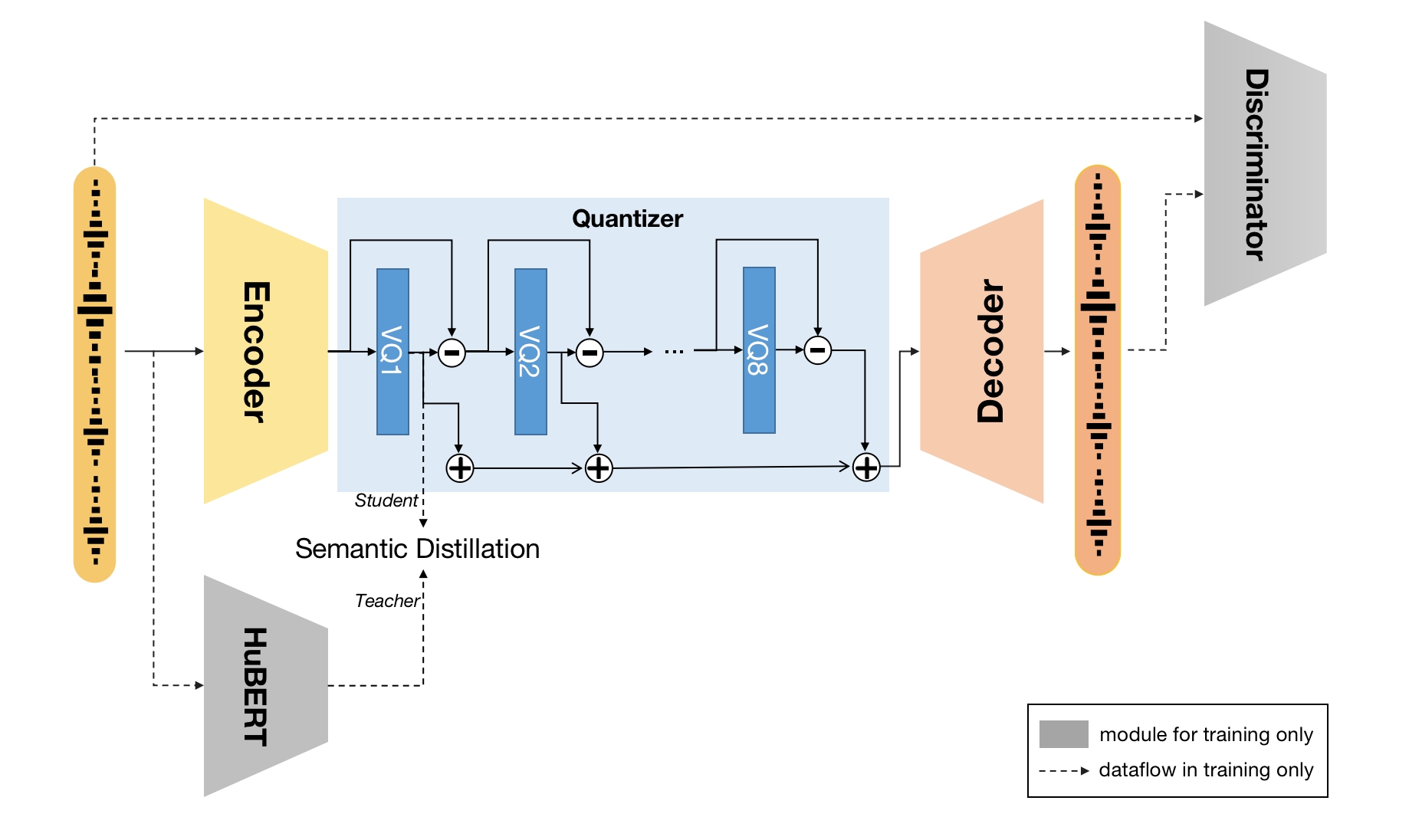
SpeechTokenizer框架
欢迎尝试我们的SLMTokBench,我们还将开源我们的USLM!
快速链接
发布
- [2024/6/9] 🔥 我们发布了SpeechTokenizer的训练代码。
- [2024/3] 🔥 我们发布了一个在LibriSpeech和Common Voice上训练的使用Snake激活函数的SpeechTokenizer检查点。
- [2023/9/11] 🔥 我们发布了soundstorm_speechtokenizer的代码。
- [2023/9/10] 🔥 我们发布了USLM的代码和检查点。
- [2023/9/1] 🔥 我们发布了SpeechTokenizer的代码和检查点。查看论文和演示。
样本
样本可在我们的演示页面上查看。
安装
SpeechTokenizer需要Python>=3.8,以及较新版本的PyTorch。 要安装SpeechTokenizer,你可以从此仓库运行:
pip install -U speechtokenizer
# 或者你可以克隆仓库并本地安装
git clone https://github.com/ZhangXInFD/SpeechTokenizer.git
cd SpeechTokenizer
pip install .
模型列表
| 模型 | 数据集 | 描述 |
|---|---|---|
| speechtokenizer_hubert_avg | LibriSpeech | 采用所有HuBERT层的平均表示作为语义教师 |
| speechtokenizer_snake | LibriSpeech + Common Voice | Snake激活函数,所有HuBERT层的平均表示 |
使用方法
加载模型
from speechtokenizer import SpeechTokenizer
config_path = '/path/config.json'
ckpt_path = '/path/SpeechTokenizer.pt'
model = SpeechTokenizer.load_from_checkpoint(config_path, ckpt_path)
model.eval()
提取离散表示
import torchaudio
import torch
# 加载并预处理语音波形
wav, sr = torchaudio.load('<SPEECH_FILE_PATH>')
# 单声道检查
if wav.shape(0) > 1:
wav = wav[:1,:]
if sr != model.sample_rate:
wav = torchaudio.functional.resample(wav, sr, model.sample_rate)
wav = wav.unsqueeze(0)
# 从SpeechTokenizer提取离散编码
with torch.no_grad():
codes = model.encode(wav) # codes: (n_q, B, T)
RVQ_1 = codes[:1, :, :] # 包含内容信息,可以被视为语义标记 RVQ_supplement = codes[1:, :, :] # 包含音色信息,补充第一个量化器丢失的信息
解码离散表示
# 将语义标记(RVQ_1)和补充音色标记连接在一起,然后进行解码
wav = model.decode(torch.cat([RVQ_1, RVQ_supplement], axis=0))
# 从第i个到第j个量化器的RVQ-i:j标记进行解码
wav = model.decode(codes[i: (j + 1)], st=i)
训练SpeechTokenizer
在以下部分,我们将描述如何使用我们的训练器来训练SpeechTokenizer模型。
数据预处理
要训练SpeechTokenizer,第一步是从原始音频波形中提取语义教师表示。我们在scripts/hubert_rep_extract.sh中提供了如何提取HuBERT表示的示例。我们解释以下参数:
--config:配置文件路径。示例在config/spt_base_cfg.json中提供。您可以修改此文件中的semantic_model_path和semantic_model_layer参数来更改Hubert模型和目标层。--audio_dir:包含所有音频文件的文件夹路径。--rep_dir:存储所有语义表示文件的文件夹路径。--exts:音频文件的扩展名。如果存在多个扩展名,请使用','分隔。--split_seed:划分训练集和验证集的随机种子。--valid_set_size:验证集的大小。当这个数字在0和1之间时,它表示用于验证集的总数据集比例。
训练
您可以使用SpeechTokenizerTrainer来训练SpeechTokenizer,如下所示:
from speechtokenizer import SpeechTokenizer, SpeechTokenizerTrainer
from speechtokenizer.discriminators import MultiPeriodDiscriminator, MultiScaleDiscriminator, MultiScaleSTFTDiscriminator
import json
# 加载模型和训练器配置
with open('<CONFIG_FILE_PATH>') as f:
cfg = json.load(f)
# 初始化SpeechTokenizer
generator = SpeechTokenizer(cfg)
# 初始化判别器。您可以添加任何尚未在此存储库中实现的判别器,只要输出格式与`speechtokenizer.discriminators`中的判别器保持一致。
discriminators = {'mpd':MultiPeriodDiscriminator(), 'msd':MultiScaleDiscriminator(), 'mstftd':MultiScaleSTFTDiscriminator(32)}
# 初始化训练器
trainer = SpeechTokenizerTrainer(generator=generator,
discriminators=discriminators,
cfg=cfg)
# 开始训练
trainer.train()
# 从检查点继续训练
trainer.continue_train()
我们在scripts/train_example.sh中提供了示例训练脚本。SpeechTokenizerTrainer的所有参数都在config/spt_base_cfg.json中定义。以下我们解释一些重要的参数:
train_files和valid_files:训练文件路径和验证文件路径。这些文件应该是文本文件,列出训练/验证集中所有音频文件及其对应的语义表示文件的路径。每行应遵循以下格式:"<音频文件路径>\t<语义文件路径>"。如果您使用scripts/hubert_rep_extract.sh提取语义表示,这两个文件将自动生成。distill_type:使用"d_axis"表示论文中提到的D轴蒸馏损失,使用"t_axis"表示T轴蒸馏损失。
快速开始
如果您想完全遵循我们的实验设置,只需在config/spt_base_cfg.json中设置semantic_model_path,在scripts/hubert_rep_extract.sh中设置AUDIO_DIR、REP_DIR、EXTS以及其他可选参数,然后执行以下代码:
cd SpeechTokenizer
# 提取语义表示
bash scripts/hubert_rep_extract.sh
# 训练
bash scripts/train_example.sh
引用
如果您在论文中使用了此代码或结果,请引用我们的工作:
@misc{zhang2023speechtokenizer,
title={SpeechTokenizer: Unified Speech Tokenizer for Speech Language Models},
author={Xin Zhang and Dong Zhang and Shimin Li and Yaqian Zhou and Xipeng Qiu},
year={2023},
eprint={2308.16692},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
许可证
本存储库中的代码根据LICENSE文件中的Apache 2.0许可证发布。











