
 访问官网
访问官网 Github
Github 论文
论文P-Flow: 通过语音提示实现快速高效的零样本文本转语音
作者: Sungwon Kim, Kevin J Shih, Rohan Badlani, Joao Felipe Santos, Evelina Bhakturina, Mikyas Desta, Rafael Valle, Sungroh Yoon, Bryan Catanzaro
机构: NVIDIA
状态: 添加了具有更好韵律和发音的新样本。请查看samples文件夹。LJSpeech预训练检查点 - GDrive链接
NVIDIA论文P-Flow: 通过语音提示实现快速高效的零样本文本转语音的非官方实现。
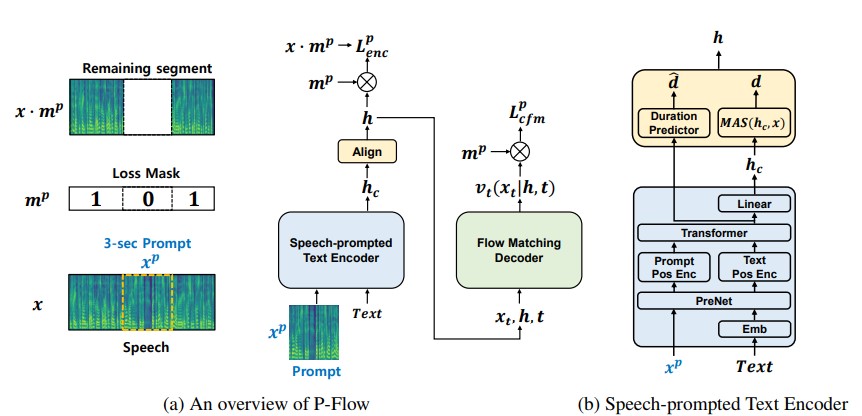
尽管最近的大规模神经编解码语言模型通过训练数千小时的数据在零样本TTS方面显示出显著改进,但它们存在一些缺点,如缺乏鲁棒性、采样速度慢(类似于之前的自回归TTS方法),以及依赖预训练的神经编解码表示。我们的工作提出了P-Flow,一种快速且数据高效的零样本TTS模型,使用语音提示进行说话人适应。P-Flow包括一个用于说话人适应的语音提示文本编码器和一个用于高质量快速语音合成的流匹配生成解码器。我们的语音提示文本编码器使用语音提示和文本输入生成说话人条件的文本表示。流匹配生成解码器使用说话人条件输出合成高质量的个性化语音,速度明显快于实时。与神经编解码语言模型不同,我们专门在LibriTTS数据集上使用连续mel表示训练P-Flow。通过我们使用连续语音提示的训练方法,P-Flow在训练数据量少两个数量级的情况下,达到了大规模零样本TTS模型的说话人相似度性能,并且采样速度提高了20多倍。我们的结果表明,P-Flow具有更好的发音,并且在人类真实性和说话人相似度方面优于最近的最先进对手,因此将P-Flow定义为一种有吸引力且理想的替代方案。
致谢
- 当然要感谢论文的作者花时间向我解释了一些我一开始没有理解的论文细节。
- 我们将基于VITS2 repo、MATCHA-TTS repo和VoiceFlow-TTS repo构建这个仓库。
- LMNT-com的朋友们。可以在lmnt-com试用他们的超快速、逼真的TTS模型。如果你喜欢我们在这里构建的内容,来加入LMNT吧。
快速运行
cd pflowtts_pytorch/notebooks
import sys
sys.path.append('..')
from pflow.models.pflow_tts import pflowTTS
import torch
from dataclasses import dataclass
@dataclass
class DurationPredictorParams:
filter_channels_dp: int
kernel_size: int
p_dropout: float
@dataclass
class EncoderParams:
n_feats: int
n_channels: int
filter_channels: int
filter_channels_dp: int
n_heads: int
n_layers: int
kernel_size: int
p_dropout: float
spk_emb_dim: int
n_spks: int
prenet: bool
@dataclass
class CFMParams:
name: str
solver: str
sigma_min: float
# 示例用法
duration_predictor_params = DurationPredictorParams(
filter_channels_dp=256,
kernel_size=3,
p_dropout=0.1
)
encoder_params = EncoderParams(
n_feats=80,
n_channels=192,
filter_channels=768,
filter_channels_dp=256,
n_heads=2,
n_layers=6,
kernel_size=3,
p_dropout=0.1,
spk_emb_dim=64,
n_spks=1,
prenet=True
)
cfm_params = CFMParams(
name='CFM',
solver='euler',
sigma_min=1e-4
)
@dataclass
class EncoderOverallParams:
encoder_type: str
encoder_params: EncoderParams
duration_predictor_params: DurationPredictorParams
encoder_overall_params = EncoderOverallParams(
encoder_type='RoPE Encoder',
encoder_params=encoder_params,
duration_predictor_params=duration_predictor_params
)
@dataclass
class DecoderParams:
channels: tuple
dropout: float
attention_head_dim: int
n_blocks: int
num_mid_blocks: int
num_heads: int
act_fn: str
decoder_params = DecoderParams(
channels=(256, 256),
dropout=0.05,
attention_head_dim=64,
n_blocks=1,
num_mid_blocks=2,
num_heads=2,
act_fn='snakebeta',
)
model = pflowTTS(
n_vocab=100,
n_feats=80,
encoder=encoder_overall_params,
decoder=decoder_params.__dict__,
cfm=cfm_params,
data_statistics=None,
)
x = torch.randint(0, 100, (4, 20))
x_lengths = torch.randint(10, 20, (4,))
y = torch.randn(4, 80, 500)
y_lengths = torch.randint(300, 500, (4,))
dur_loss, prior_loss, diff_loss, attn = model(x, x_lengths, y, y_lengths)
# 反向传播损失
# 现在进行合成
x = torch.randint(0, 100, (1, 20))
x_lengths = torch.randint(10, 20, (1,))
y_slice = torch.randn(1, 80, 264)
model.synthesise(x, x_lengths, y_slice, n_timesteps=10)
在Google Colab上快速运行

运行说明
- 创建环境(建议但非必需)
conda create -n pflowtts python=3.10 -y
conda activate pflowtts
保持在根目录(当然先要克隆仓库!)
cd pflowtts_pytorch
pip install -r requirements.txt
- 构建单调对齐搜索
# Cython版本的单调对齐搜索
python setup.py build_ext --inplace
假设我们使用LJ Speech进行训练
- 从这里下载数据集,解压到
data/LJSpeech-1.1,并准备文件列表以指向解压的数据,如NVIDIA Tacotron 2仓库设置中的第5项所示。
3a. 转到configs/data/ljspeech.yaml并更改
train_filelist_path: data/filelists/ljs_audio_text_train_filelist.txt
valid_filelist_path: data/filelists/ljs_audio_text_val_filelist.txt
3b. 懒人的辅助命令
!mkdir -p /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists
!wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_test_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_test_filelist.txt
!wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_train_filelist.txt
!wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_val_filelist.txt
!sed -i -- 's,DUMMY,/home/ubuntu/LJSpeech/LJSpeech-1.1/wavs,g' /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/*.txt
!sed -i -- 's,train_filelist_path: data/filelists/ljs_audio_text_train_filelist.txt,train_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt,g' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml
!sed -i -- 's,valid_filelist_path: data/filelists/ljs_audio_text_val_filelist.txt,valid_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt,g' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml
- 使用数据集配置的yaml文件生成标准化统计
cd pflowtts_pytorch/pflow/utils
python generate_data_statistics.py -i ljspeech.yaml
# 输出:
#{'mel_mean': -5.53662231756592, 'mel_std': 2.1161014277038574}
在configs/data/ljspeech.yaml中的data_statistics键下更新这些值。
data_statistics: # 为ljspeech数据集计算得出
mel_mean: -5.536622
mel_std: 2.116101
到你的训练和验证文件列表的路径。
- 运行训练脚本
python pflow/train.py experiment=ljspeech
- 对于多GPU训练,运行
python pflow/train.py experiment=ljspeech trainer.devices=[0,1]
架构细节
- 带有Prenet和RoPE Transformer的语音提示文本编码器
- 带有MAS的持续时间预测器
- 带有CFM的流匹配生成解码器(论文使用wavenet解码器;我们使用修改的wavenet,并包含可选的U-NET解码器进行实验)
- 语音提示输入目前切片输入频谱图并与文本嵌入连接。可以支持外部语音提示输入(在训练期间也可以)
- 用于训练的pflow提示掩码损失
- HiFiGan作为声码器
- 采样的指导
待办事项、功能和更新说明
- (2023/11/12) 目前这是一个实验性仓库,许多功能都采用了我在网上找到的快速架构实现。我将很快添加原始架构。
- (2023/11/12) 查看
notebooks文件夹以快速运行和测试模型架构。 -
(2023/11/12) 目前在我的数据集上训练失败,我会尽快调试并修复。但训练代码运行时没有错误。 - (2023/11/13)
- 修复了单调对齐构建中的重大错误
- 模型内部可以有多种组合
- 架构的整体框架与论文相同,但内部实现不同
- 如果模型无法收敛,最终会采用论文中的确切架构
- (2023/11/13) Tensorboard截图
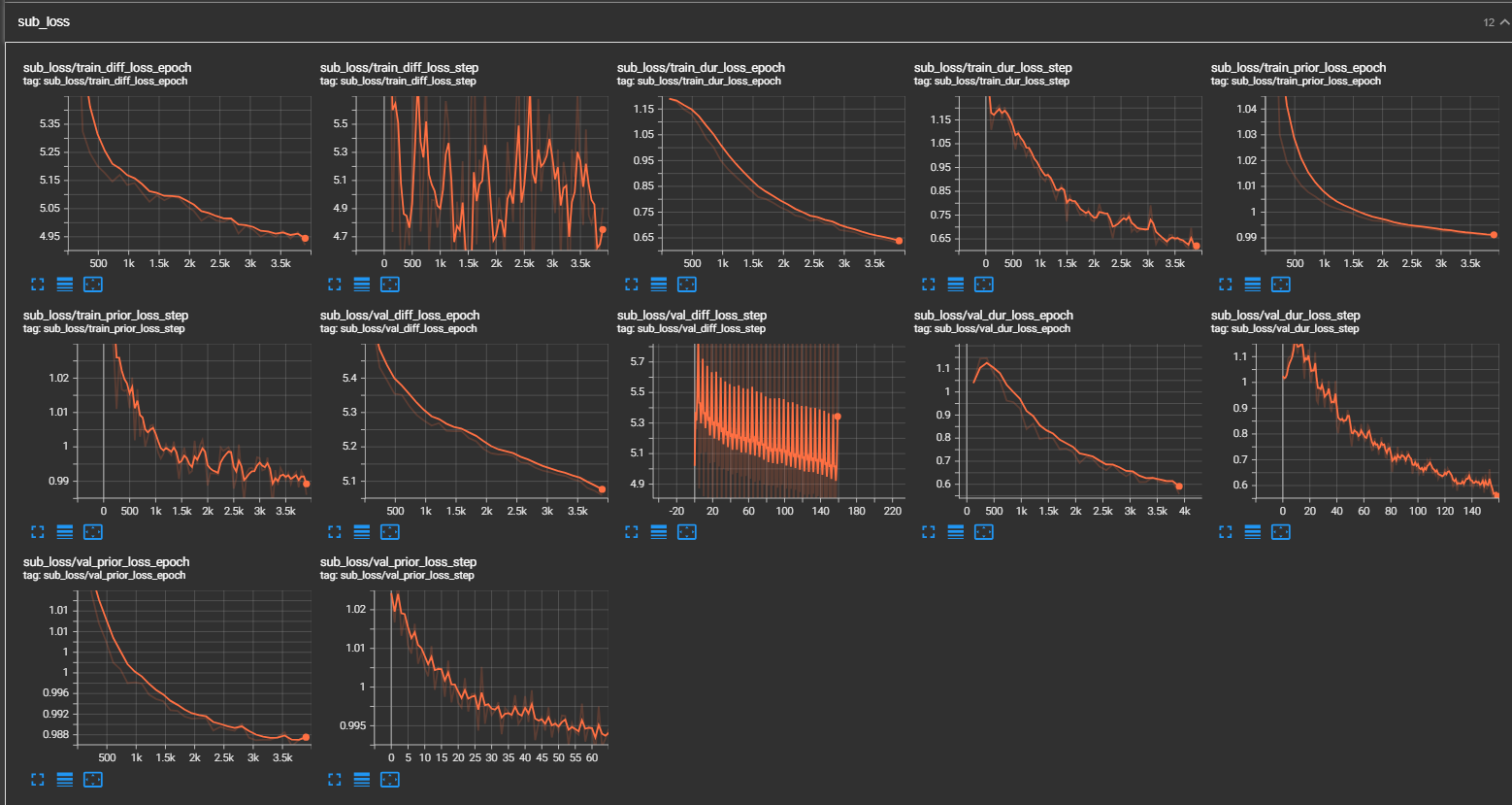
- (2023/11/13)
- 添加了安装说明
- (2023/11/13)
- 看起来模型正在学习,并且走上了正轨。
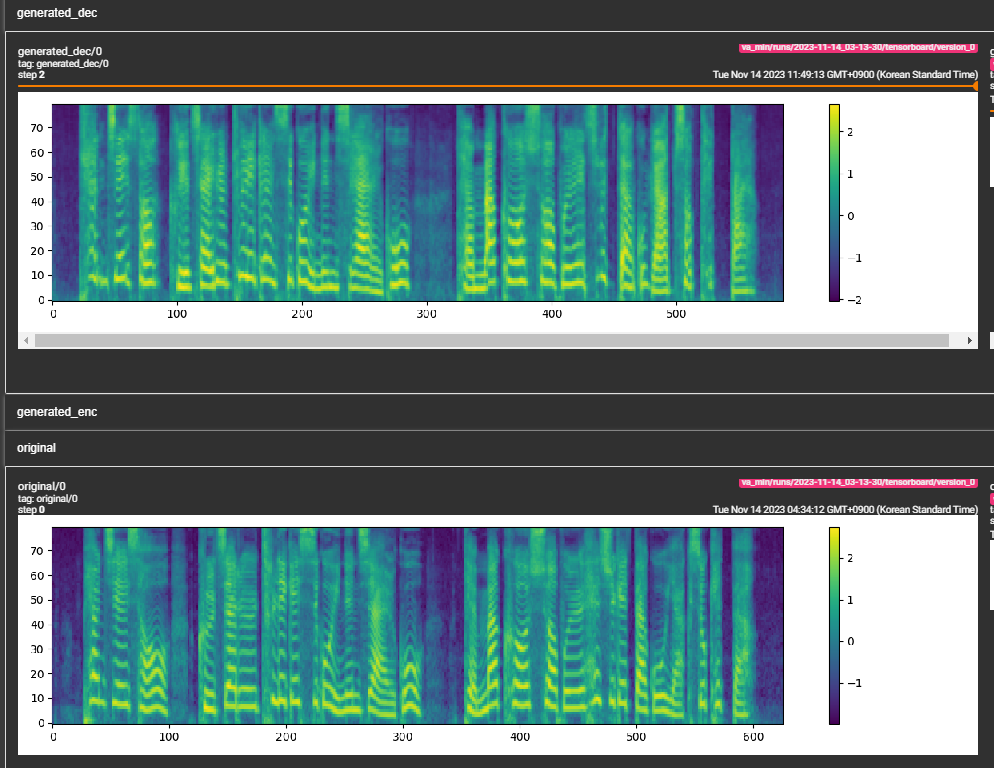
- 看起来模型正在学习,并且走上了正轨。
- (2023/11/14)
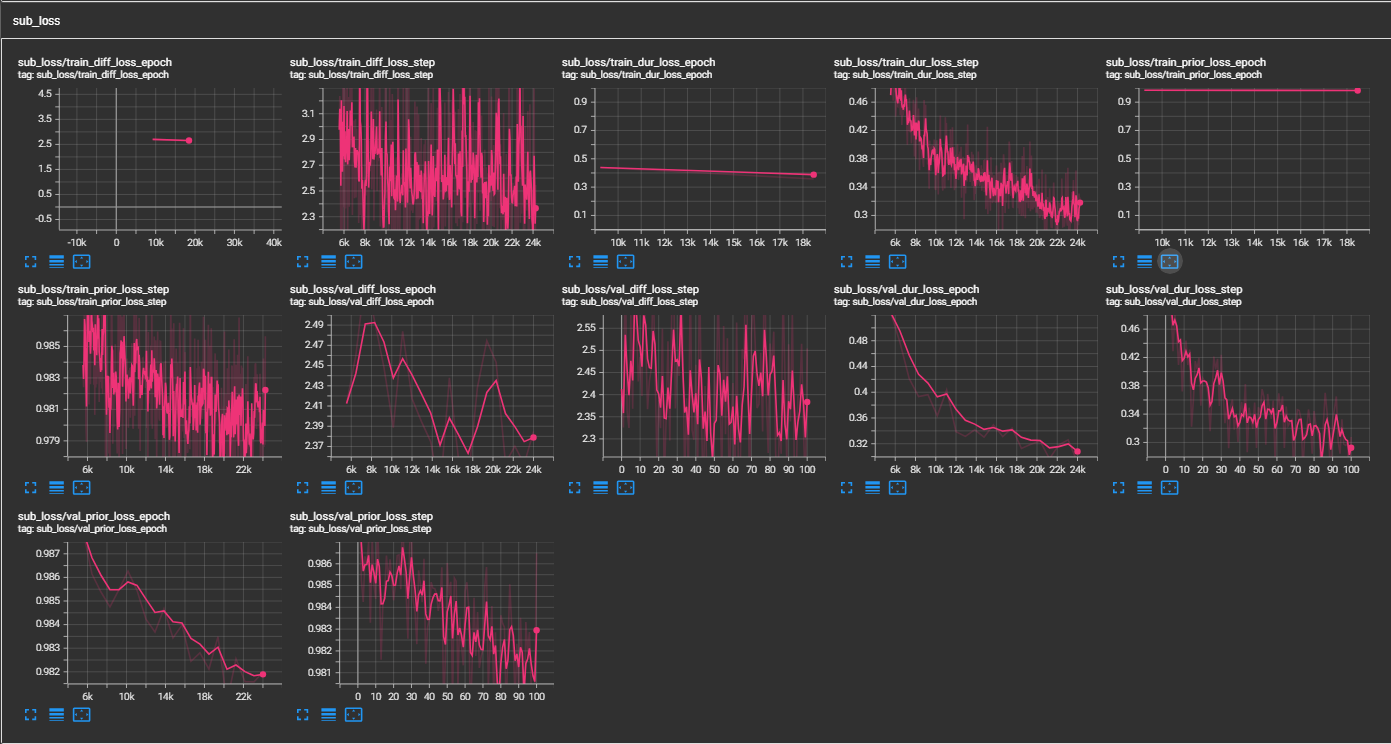
- (2023/11/14)
- 添加了Google Colab笔记本以便快速运行
- (2023/11/16)
- 添加了示例音频
- 进行了一些架构更改
- 我们知道模型在学习,现在需要尝试多说话人并检查韵律。
- (2023/11/17)
- 添加了3个新分支 ->
- dev/stochastic -> 对后验采样和文本编码器(先验)进行了一些更改,使其具有随机性
- dev/encodec -> 预测encodec连续潜在变量而不是梅尔频谱图;如果可行,使用encodec进行解码而不是hifi-gan
- exp/end2end -> pflow与hi-fi gan的端到端训练,直接从文本和语音提示输入生成音频;如果可行,vits-tts将被淘汰。
- 添加了3个新分支 ->
- (2023/11/17)
- 24轮encodec样本(虽然有机器人感,但这是概念验证)encodec_poc.wav
- (2023/11/20)
- 模型基本准备就绪。
- 为估计器添加了3种选择,需要将它们设为超参数并添加到配置文件中。
- 感谢@zidsi指出代码中的拼写错误。
- (2023/11/23)
- 添加了具有更好韵律和发音的新样本。查看
samples文件夹。(LJSpeech训练300k步)论文建议800k步。
- 添加了具有更好韵律和发音的新样本。查看
- (2023/12/02)
- 按照论文建议,为欧拉求解器添加了引导。这大大提高了音频质量。感谢discord上的@robbit指出这一点。
- (2023/12/03)
- 为好奇的人添加了descript-codec分支。(尚未测试)
- (2024/01/17)
- 在配置文件(data/[dataset].yaml)中添加了最小wav样本大小(秒)参数,
min_sample_size(默认为4秒;以确保提示至少3秒,预测至少1秒) - 在配置文件(models/pflow.yaml)中添加了
prompt_size,用于控制提示的大小。它是训练时从wav样本中使用的mel帧数。(默认约3秒;3*22050//256 = 258;在配置中四舍五入为264) - 在配置文件(models/pflow.yaml)中添加了
dur_p_use_log,用于控制是否使用持续时间预测的对数进行损失计算。(现在默认为False)我的假设是,对数持续时间的均方误差损失对较长的停顿等效果不佳(由于对数函数的性质)。因此,我们在计算损失之前对对数持续时间进行e的幂运算。另一种方法可以是使用relu而不是对数。 - 在配置文件(train.yaml)中添加了
transfer_ckpt_path,用于控制用于迁移学习的检查点路径。(默认为None)如果为None,则从头开始训练模型。如果不为None,则从检查点路径加载模型并从步骤0开始训练。如果ckpt_path也不为None,则从ckpt_path加载模型并从保存的步骤开始训练。transfer_ckpt_path可以处理检查点和模型之间的层大小不匹配。
- 在配置文件(data/[dataset].yaml)中添加了最小wav样本大小(秒)参数,
- (2024/01/28)
- 基于Matcha-TTS仓库添加了ONNX导出支持。(尚未测试,很快会测试){草稿}
- (2024/01/30)
- ONNX已测试并运行良好。使用
export.py和inference.py中的参数导出和测试模型。(参数是自解释的)
- ONNX已测试并运行良好。使用
- (2024/03/18)
- 在语音文本编码器中添加了位置嵌入。
- 欢迎任何人为这个仓库做出贡献。请随时提出问题或提交PR。











