
XTTS-2-UI:一个用于XTTS-2文本语音克隆的用户界面
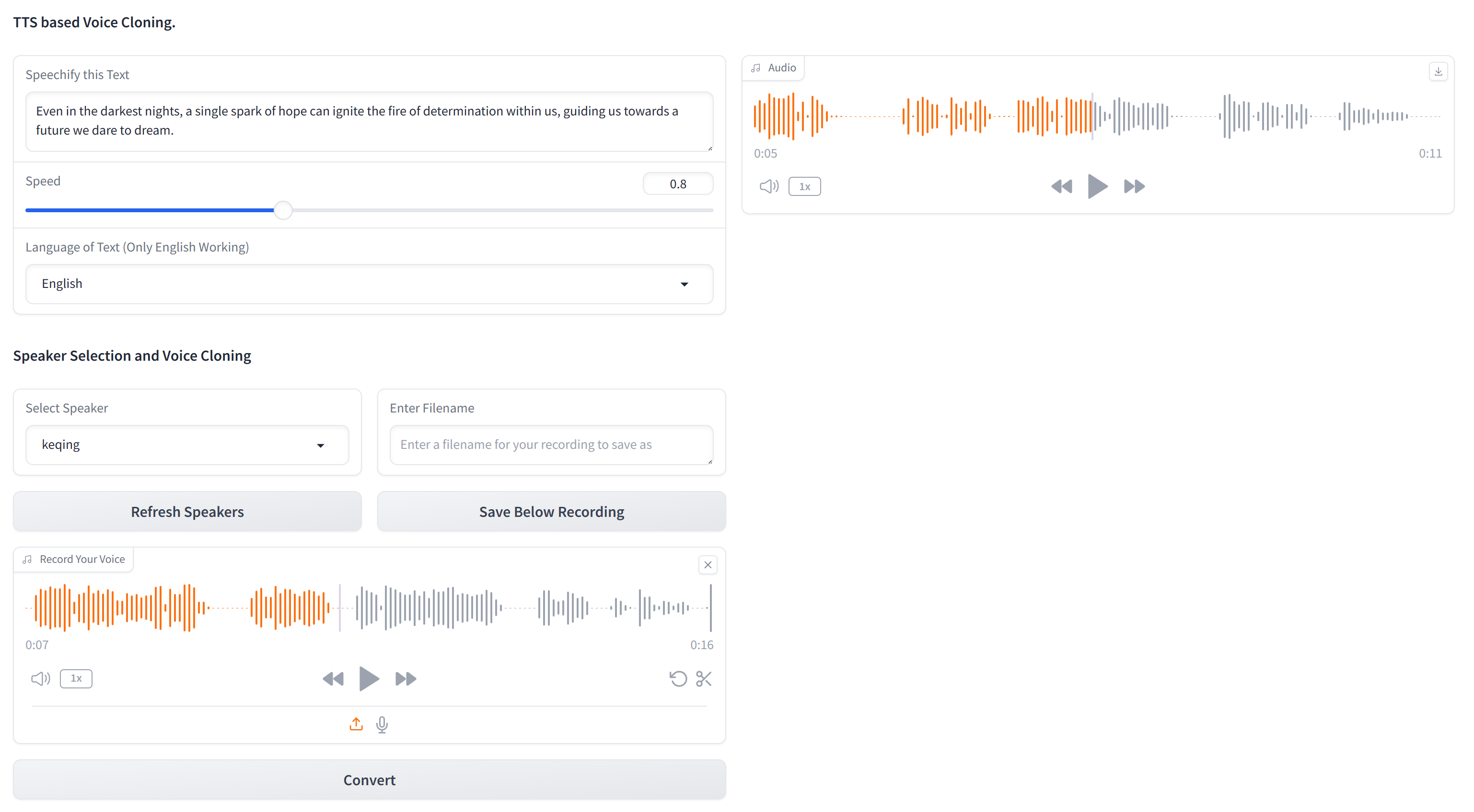
此存储库包含用于仅使用文本和目标语音的10秒音频样本克隆任何语音的基本代码。XTTS-2-UI 简单易用。 示例结果 🔊
支持 16 种语言 并具备内置的语音录制/上传功能。 注意:不要期望达到EL级别的质量,还没有达到这个水平。
模型
使用的模型是 tts_models/multilingual/multi-dataset/xtts_v2。有关更多详情,请参阅 Hugging Face - XTTS-v2及其特定版本 XTTS-v2 版本2.0.2。
目录
设置
要设置该项目,请按照终端中的以下步骤操作:
-
克隆存储库
- 将存储库克隆到本地机器。
git clone https://github.com/pbanuru/xtts2-ui.git cd xtts2-ui
- 将存储库克隆到本地机器。
-
创建一个虚拟环境:
- 运行以下命令创建一个Python虚拟环境:
python -m venv venv - 激活虚拟环境:
-
Windows:
# cmd prompt venv\Scripts\activate或
# git bash source venv/Scripts/activate -
Linux/Mac:
source venv/bin/activate
-
- 运行以下命令创建一个Python虚拟环境:
-
安装PyTorch:
- 如果您有Nvidia CUDA支持的GPU,请选择适当的PyTorch安装命令:
- 在安装PyTorch之前,通过运行检查您的CUDA版本:
nvcc --version - 对于CUDA 12.1:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 - 对于CUDA 11.8:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
- 在安装PyTorch之前,通过运行检查您的CUDA版本:
- 如果您没有CUDA支持的GPU: 请按照PyTorch官网上的说明为您的系统安装适当版本的PyTorch。
- 如果您有Nvidia CUDA支持的GPU,请选择适当的PyTorch安装命令:
-
安装其他必需的软件包:
- 安装直接依赖项:
pip install -r requirements.txt - 将TTS包升级到最新版本:
pip install --upgrade TTS
- 安装直接依赖项:
在完成这些步骤后,您的设置应该完成,您可以开始使用该项目。
模型将在第一次使用时自动下载。
下载路径:
- MacOS:
/Users/USR/Library/Application Support/tts/tts_models--multilingual--multi-dataset--xtts_v2 - Windows:
C:\Users\ YOUR-USER-ACCOUNT \AppData\Local\tts\tts_models--multilingual--multi-dataset--xtts_v2 - Linux:
/home/${USER}/.local/share/tts/tts_models--multilingual--multi-dataset--xtts_v2
推理
要运行应用程序:
python app.py
或
streamlit run app2.py
或者,您也可以直接从终端运行,通过提供 texts.json 中的示例输入文本,并用多种语音生成多个音频(您可能需要在 appTerminal.py 中进行调整):
python appTerminal.py
初次使用时,您需要同意条款:
[XTTS] 加载 XTTS...
> tts_models/multilingual/multi-dataset/xtts_v2 已更新,清理模型缓存...
> 您必须同意服务条款才能使用此模型。
| > 请查看服务条款 https://coqui.ai/cpml.txt
| > "我已阅读、理解并同意条款和条件。" - [y/n]
| | >
如果您的模型每次运行时都会重新下载,请查看 GitHub上的Issue 4723。
目标语音数据集
该数据集包含一个名为 targets 的文件夹,预装有几个用于测试的语音。
要添加更多语音(如果您不想通过GUI进行操作),请创建一个约10秒的24KHz WAV文件,并将其放置在 targets 文件夹下。
您可以使用 yt-dlp 从YouTube下载语音进行克隆:
yt-dlp -x --audio-format wav "https://www.youtube.com/watch?"
音频示例:
语言支持
阿拉伯语、中文、捷克语、荷兰语、英语、法语、德语、匈牙利语、意大利语、日语(见设置)、韩语、波兰语、葡萄牙语、俄语、西班牙语、土耳其语
注意事项
如果您想选择日语作为目标语言,您需要安装字典。
# 精简版
pip install fugashi[unidic-lite]
或者对于更深入的处理:
# 完整版
pip install fugashi[unidic]
python -m unidic download
更多细节见此。









