
 Github
Github Huggingface
HuggingfaceStableTTS
使用流匹配和DiT的下一代TTS模型,灵感来自Stable Diffusion 3。
介绍
作为首个尝试结合流匹配和DiT的开源TTS模型,StableTTS是一个快速、轻量级的中英文语音生成TTS模型。它仅有1000万个参数。
预训练模型
我们提供了可用于推理、微调和网页界面的预训练模型。只需下载并将模型放置在./checkpoints目录中即可开始使用。
更大的模型、更好的预训练模型和多语言模型即将推出...
安装
-
设置pytorch:按照官方PyTorch指南安装pytorch和torchaudio。我们建议使用最新版本以获得最佳性能。
-
安装依赖:运行以下命令安装所需的Python包:
pip install -r requirements.txt
推理
有关详细的推理说明,请参阅inference.ipynb
我们还提供了基于gradio的网页界面,请参阅webui.py
训练
使用StableTTS训练您的模型设计得简单高效。以下是开始的方法:
准备数据
-
生成文本和音频对:生成文本和音频对文件列表,如
./filelists/example.txt。一些开源数据集的处理方法可以在./recipes中找到。 -
运行预处理:调整
preprocess.py中的DataConfig以设置输入和输出路径,然后运行脚本。这将根据您的列表处理音频和文本,输出包含梅尔特征和音素路径的JSON文件。注意:对于英语或日语文本处理,请确保在DataConfig中将language = 'chinese'更改为相应语言。
注意:由于我们在训练时使用reference encoder来捕捉说话人身份,因此在多说话人合成和训练中不需要说话人ID。
开始训练
-
调整训练配置:在
config.py中,修改TrainConfig以设置您的文件列表路径并根据需要调整训练参数。 -
启动训练过程:运行
train.py开始训练您的模型。
注意:对于微调,请下载预训练模型并将其放置在TrainConfig中指定的model_save_path目录中。训练脚本将自动检测并加载预训练的检查点。
实验配置
请随意探索和修改config.py中的设置以调整超参数!
模型结构
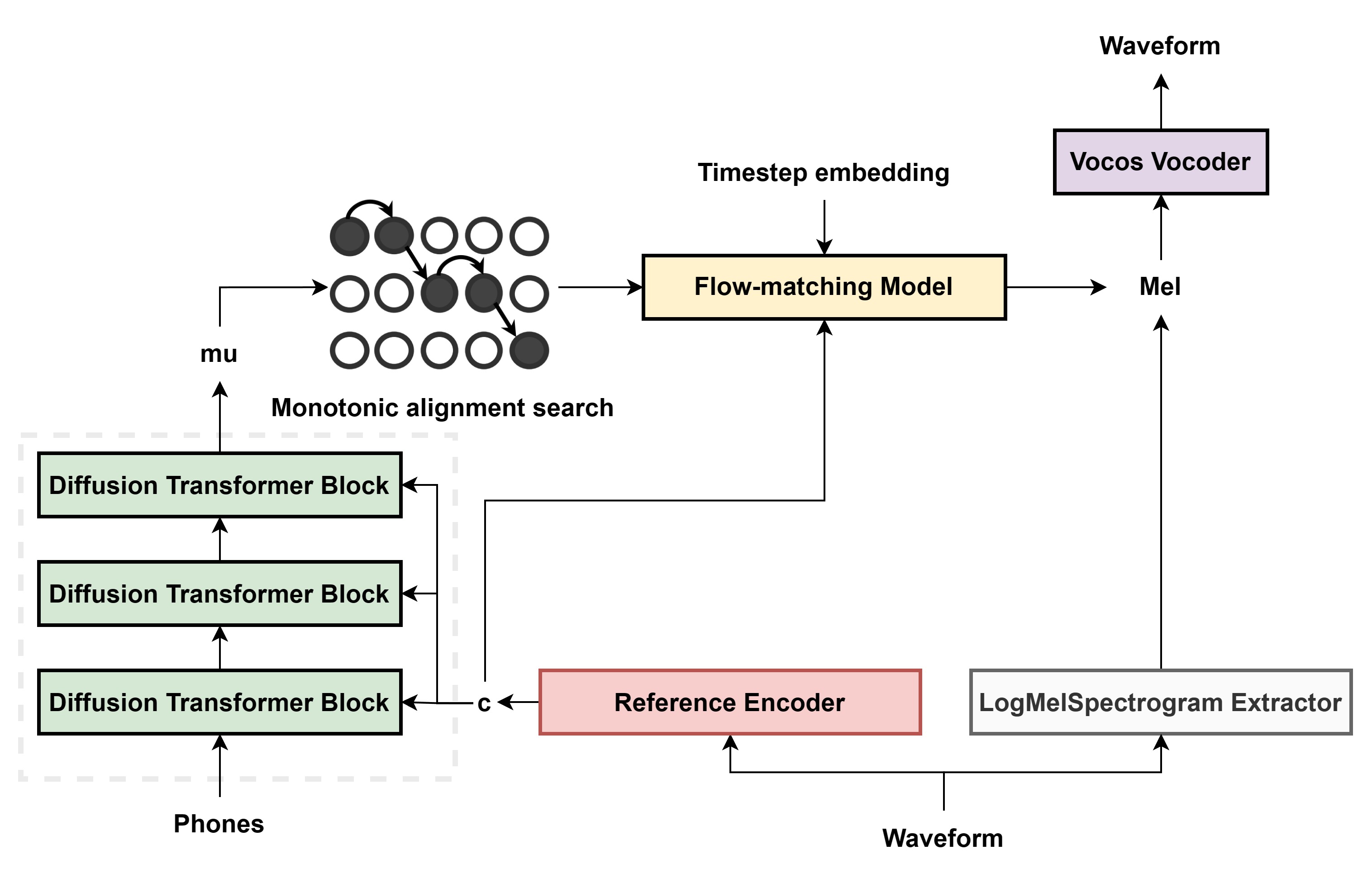
-
我们使用来自Hierspeech++的扩散卷积Transformer块,它是原始DiT和FFT(来自fastspeech的前馈Transformer)的组合,以获得更好的韵律。
-
在流匹配解码器中,我们在DiT块之前添加了一个FiLM层,以将时间步嵌入条件化到模型中。我们还在DiT之前添加了三个ConvNeXt块。我们发现这有助于模型收敛和提高音质。
参考文献
我们的模型开发在很大程度上依赖于来自各种项目的见解和代码。我们衷心感谢以下项目的创作者:
直接灵感来源
Matcha TTS:基本的流匹配代码。
Grad TTS:扩散模型结构。
Stable Diffusion 3:结合流匹配和DiT的想法。
Vits:代码风格和MAS见解,DistributedBucketSampler。
其他参考:
plowtts-pytorch:训练中MAS的代码
Bert-VITS2:MAS的numba版本和Vits的现代pytorch代码
fish-speech:数据类的使用和使用torchaudio的梅尔频谱图转换
gpt-sovits:用于声音克隆的melstyle编码器
diffsinger:中文g2p的三段式音素方案
coqui xtts:gradio网页界面
待办事项
- 发布预训练模型。
- 提供详细的微调说明。
- 支持日语。
- 用户友好的预处理和推理脚本。
- 增强文档和引用。
- 添加中文版README。
- 发布多语言检查点。
免责声明
禁止任何组织或个人使用本仓库中的任何技术在未经他人同意的情况下生成或编辑他人的语音,包括但不限于政府领导人、政治人物和名人。如果您不遵守此项,可能会违反版权法。











