
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
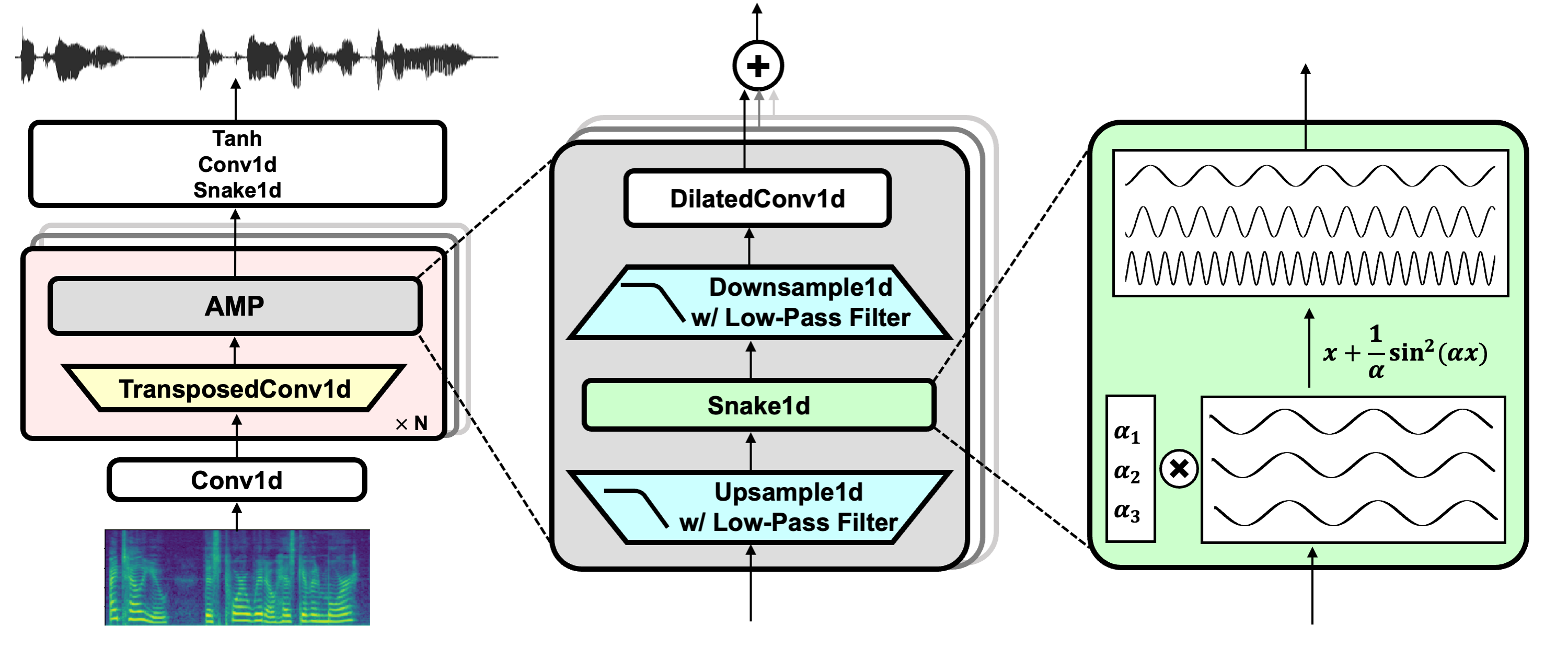
论文BigVGAN:一种基于大规模训练的通用神经声码器
Sang-gil Lee, Wei Ping, Boris Ginsburg, Bryan Catanzaro, Sungroh Yoon
[论文] - [代码] - [展示] - [项目主页] - [权重] - [演示]
![]()
新闻
-
2024年7月 (v2.3):
- 进行了全面的重构和代码改进,以提高可读性。
- 完全融合的CUDA核心,实现抗锯齿激活(上采样 + 激活 + 下采样),并提供推理速度基准测试。
-
2024年7月 (v2.2): 该仓库现在包含一个使用gradio的交互式本地演示。
-
2024年7月 (v2.1): BigVGAN现已集成到🤗 Hugging Face Hub,可以使用预训练的检查点轻松进行推理。我们还在Hugging Face Spaces上提供了一个交互式演示。
-
2024年7月 (v2): 我们发布了BigVGAN-v2以及预训练的检查点。以下是亮点:
- 用于推理的自定义CUDA核心:我们提供了一个用CUDA编写的融合上采样 + 激活核心,以加速推理。我们的测试显示在单个A100 GPU上速度提升了1.5 - 3倍。
- 改进的判别器和损失函数:BigVGAN-v2使用多尺度子带CQT判别器和多尺度梅尔谱图损失进行训练。
- 更大的训练数据:BigVGAN-v2使用包含多种音频类型的数据集进行训练,包括多种语言的语音、环境声音和乐器声音。
- 我们提供了使用不同音频配置的BigVGAN-v2预训练检查点,支持高达44 kHz采样率和512倍上采样比率。
安装
代码库已在Python 3.10和PyTorch 2.3.1 conda包上进行了测试,使用pytorch-cuda=12.1或pytorch-cuda=11.8。以下是创建conda环境的示例命令:
conda create -n bigvgan python=3.10 pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
conda activate bigvgan
克隆仓库并安装依赖项:
git clone https://github.com/NVIDIA/BigVGAN
cd BigVGAN
pip install -r requirements.txt
使用🤗 Hugging Face Hub进行快速推理
以下示例描述了如何使用BigVGAN:从Hugging Face Hub加载预训练的BigVGAN生成器,从输入波形计算梅尔谱图,并使用梅尔谱图作为模型的输入生成合成波形。
device = 'cuda'
import torch
import bigvgan
import librosa
from meldataset import get_mel_spectrogram
# 实例化模型。您可以选择设置use_cuda_kernel=True以获得更快的推理速度。
model = bigvgan.BigVGAN.from_pretrained('nvidia/bigvgan_v2_24khz_100band_256x', use_cuda_kernel=False)
# 移除模型中的权重归一化并设置为评估模式
model.remove_weight_norm()
model = model.eval().to(device)
# 加载wav文件并计算梅尔谱图
wav_path = '/path/to/your/audio.wav'
wav, sr = librosa.load(wav_path, sr=model.h.sampling_rate, mono=True) # wav是形状为[T_time]的np.ndarray,值在[-1, 1]之间
wav = torch.FloatTensor(wav).unsqueeze(0) # wav是形状为[B(1), T_time]的FloatTensor
# 从真实音频计算梅尔谱图
mel = get_mel_spectrogram(wav, model.h).to(device) # mel是形状为[B(1), C_mel, T_frame]的FloatTensor
# 从梅尔谱图生成波形
with torch.inference_mode():
wav_gen = model(mel) # wav_gen是形状为[B(1), 1, T_time]的FloatTensor,值在[-1, 1]之间
wav_gen_float = wav_gen.squeeze(0).cpu() # wav_gen是形状为[1, T_time]的FloatTensor
# 您可以将生成的波形转换为16位线性PCM
wav_gen_int16 = (wav_gen_float * 32767.0).numpy().astype('int16') # wav_gen现在是形状为[1, T_time]的np.ndarray,dtype为int16
本地gradio演示 
您可以使用以下命令运行本地gradio演示:
pip install -r demo/requirements.txt
python demo/app.py
训练
创建指向数据集根目录的符号链接。代码库使用相对于数据集的文件列表。以下是LibriTTS数据集的示例命令:
cd filelists/LibriTTS && \
ln -s /path/to/your/LibriTTS/train-clean-100 train-clean-100 && \
ln -s /path/to/your/LibriTTS/train-clean-360 train-clean-360 && \
ln -s /path/to/your/LibriTTS/train-other-500 train-other-500 && \
ln -s /path/to/your/LibriTTS/dev-clean dev-clean && \
ln -s /path/to/your/LibriTTS/dev-other dev-other && \
ln -s /path/to/your/LibriTTS/test-clean test-clean && \
ln -s /path/to/your/LibriTTS/test-other test-other && \
cd ../..
训练BigVGAN模型。以下是使用LibriTTS数据集在24kHz采样率下训练BigVGAN-v2的示例命令,输入为完整的100频带梅尔谱图:
python train.py \
--config configs/bigvgan_v2_24khz_100band_256x.json \
--input_wavs_dir filelists/LibriTTS \
--input_training_file filelists/LibriTTS/train-full.txt \
--input_validation_file filelists/LibriTTS/val-full.txt \
--list_input_unseen_wavs_dir filelists/LibriTTS filelists/LibriTTS \
--list_input_unseen_validation_file filelists/LibriTTS/dev-clean.txt filelists/LibriTTS/dev-other.txt \
--checkpoint_path exp/bigvgan_v2_24khz_100band_256x
合成
从BigVGAN模型进行合成。以下是从模型生成音频的示例命令。
它使用--input_wavs_dir中的wav文件计算梅尔谱图,并将生成的音频保存到--output_dir。
python inference.py \
--checkpoint_file /path/to/your/bigvgan_v2_24khz_100band_256x/bigvgan_generator.pt \
--input_wavs_dir /path/to/your/input_wav \
--output_dir /path/to/your/output_wav
inference_e2e.py 支持直接从保存为 .npy 格式的梅尔频谱图进行合成,形状为 [1, 通道, 帧] 或 [通道, 帧]。
它从 --input_mels_dir 加载梅尔频谱图,并将生成的音频保存到 --output_dir。
请确保梅尔频谱图的 STFT 超参数与模型相同,这些参数在相应模型的 config.json 中定义。
python inference_e2e.py \
--checkpoint_file /path/to/your/bigvgan_v2_24khz_100band_256x/bigvgan_generator.pt \
--input_mels_dir /path/to/your/input_mel \
--output_dir /path/to/your/output_wav
使用自定义 CUDA 内核进行合成
在实例化 BigVGAN 时,可以通过使用 use_cuda_kernel 参数来应用快速 CUDA 推理内核:
generator = BigVGAN(h, use_cuda_kernel=True)
您还可以在运行 inference.py 和 inference_e2e.py 时传递 --use_cuda_kernel 参数来启用此功能。
首次应用时,它会使用 nvcc 和 ninja 构建内核。如果构建成功,内核将被保存到 alias_free_activation/cuda/build 目录,模型会自动加载该内核。代码库已使用 CUDA 12.1 进行测试。
请确保您的系统中安装了这两个工具,并且系统中安装的 nvcc 版本与您的 PyTorch 构建所使用的版本匹配。
我们建议先运行 test_cuda_vs_torch_model.py 来构建并检查 CUDA 内核的正确性。以下是示例命令及其输出,其中返回 [Success] test CUDA fused vs. plain torch BigVGAN inference:
python tests/test_cuda_vs_torch_model.py \
--checkpoint_file /path/to/your/bigvgan_generator.pt
loading plain Pytorch BigVGAN
...
loading CUDA kernel BigVGAN with auto-build
Detected CUDA files, patching ldflags
Emitting ninja build file /path/to/your/BigVGAN/alias_free_activation/cuda/build/build.ninja..
Building extension module anti_alias_activation_cuda...
...
Loading extension module anti_alias_activation_cuda...
...
Loading '/path/to/your/bigvgan_generator.pt'
...
[Success] test CUDA fused vs. plain torch BigVGAN inference
> mean_difference=0.0007238413265440613
...
如果看到 [Fail] test CUDA fused vs. plain torch BigVGAN inference,则表示 CUDA 内核推理不正确。请检查系统中安装的 nvcc 是否与您的 PyTorch 版本兼容。
预训练模型
我们在 Hugging Face Collections 上提供了预训练模型。
您可以在列出的模型库中下载生成器权重(名为 bigvgan_generator.pt)和其判别器/优化器状态(名为 bigvgan_discriminator_optimizer.pt)的检查点。
| 模型名称 | 采样率 | Mel 频带 | fmax | 上采样比率 | 参数量 | 数据集 | 步数 | 是否微调 |
|---|---|---|---|---|---|---|---|---|
| bigvgan_v2_44khz_128band_512x | 44 kHz | 128 | 22050 | 512 | 122M | 大规模编译 | 3M | 否 |
| bigvgan_v2_44khz_128band_256x | 44 kHz | 128 | 22050 | 256 | 112M | 大规模编译 | 3M | 否 |
| bigvgan_v2_24khz_100band_256x | 24 kHz | 100 | 12000 | 256 | 112M | 大规模编译 | 3M | 否 |
| bigvgan_v2_22khz_80band_256x | 22 kHz | 80 | 11025 | 256 | 112M | 大规模编译 | 3M | 否 |
| bigvgan_v2_22khz_80band_fmax8k_256x | 22 kHz | 80 | 8000 | 256 | 112M | 大规模编译 | 3M | 否 |
| bigvgan_24khz_100band | 24 kHz | 100 | 12000 | 256 | 112M | LibriTTS | 5M | 否 |
| bigvgan_base_24khz_100band | 24 kHz | 100 | 12000 | 256 | 14M | LibriTTS | 5M | 否 |
| bigvgan_22khz_80band | 22 kHz | 80 | 8000 | 256 | 112M | LibriTTS + VCTK + LJSpeech | 5M | 否 |
| bigvgan_base_22khz_80band | 22 kHz | 80 | 8000 | 256 | 14M | LibriTTS + VCTK + LJSpeech | 5M | 否 |
论文的结果基于在 LibriTTS 数据集上训练的原始 24kHz BigVGAN 模型(bigvgan_24khz_100band 和 bigvgan_base_24khz_100band)。
我们还提供了带有限频带设置(即 fmax=8000)的 22kHz BigVGAN 模型,用于 TTS 应用。
请注意,这些检查点使用具有对数尺度参数化的 snakebeta 激活函数,整体质量最佳。
您可以通过以下方式微调模型:
- 下载检查点(包括生成器权重和其判别器/优化器状态)
- 通过在启动
train.py时指定包含检查点的--checkpoint_path,使用您的音频数据集恢复训练
BigVGAN-v2 的训练细节
与原始 BigVGAN 相比,BigVGAN-v2 的预训练检查点使用了 batch_size=32 和更长的 segment_size=65536,并使用 8 个 A100 GPU 进行训练。
请注意,./configs 中的 BigVGAN-v2 json 配置文件默认使用 batch_size=4,以适应单个 A100 GPU 进行训练。您可以根据您的 GPU 调整 batch_size 来微调模型。
从头开始训练 BigVGAN-v2 时,如果使用小批量大小,可能会遇到论文中提到的早期发散问题。在这种情况下,我们建议在早期训练迭代(例如 20000 步)中降低 clip_grad_norm 值(例如 100),然后将其增加到默认值 500。
BigVGAN-v2 的评估结果
以下是24kHz模型(bigvgan_v2_24khz_100band_256x)在LibriTTS dev集上获得的客观结果。BigVGAN-v2在各项指标上都有显著改进。该模型还减少了感知上的伪音,特别是对于非语音音频。
| 模型 | 数据集 | 步数 | PESQ(↑) | M-STFT(↓) | MCD(↓) | 周期性(↓) | V/UV F1(↑) |
|---|---|---|---|---|---|---|---|
| BigVGAN | LibriTTS | 1M | 4.027 | 0.7997 | 0.3745 | 0.1018 | 0.9598 |
| BigVGAN | LibriTTS | 5M | 4.256 | 0.7409 | 0.2988 | 0.0809 | 0.9698 |
| BigVGAN-v2 | 大规模编译数据集 | 3M | 4.359 | 0.7134 | 0.3060 | 0.0621 | 0.9777 |
速度基准测试
以下是BigVGAN从tests/test_cuda_vs_torch_model.py得出的速度和显存使用基准测试结果,使用bigvgan_v2_24khz_100band_256x作为参考模型。
| GPU | mel帧数 | 使用CUDA内核 | 速度 (kHz) | 实时倍数 | 显存 (GB) |
|---|---|---|---|---|---|
| NVIDIA A100 | 256 | 否 | 1672.1 | 69.7x | 1.3 |
| 是 | 3916.5 | 163.2x | 1.3 | ||
| 2048 | 否 | 1899.6 | 79.2x | 1.7 | |
| 是 | 5330.1 | 222.1x | 1.7 | ||
| 16384 | 否 | 1973.8 | 82.2x | 5.0 | |
| 是 | 5761.7 | 240.1x | 4.4 | ||
| NVIDIA GeForce RTX 3080 | 256 | 否 | 841.1 | 35.0x | 1.3 |
| 是 | 1598.1 | 66.6x | 1.3 | ||
| 2048 | 否 | 929.9 | 38.7x | 1.7 | |
| 是 | 1971.3 | 82.1x | 1.6 | ||
| 16384 | 否 | 943.4 | 39.3x | 5.0 | |
| 是 | 2026.5 | 84.4x | 3.9 | ||
| NVIDIA GeForce RTX 2080 Ti | 256 | 否 | 515.6 | 21.5x | 1.3 |
| 是 | 811.3 | 33.8x | 1.3 | ||
| 2048 | 否 | 576.5 | 24.0x | 1.7 | |
| 是 | 1023.0 | 42.6x | 1.5 | ||
| 16384 | 否 | 589.4 | 24.6x | 5.0 | |
| 是 | 1068.1 | 44.5x | 3.2 |
致谢
我们感谢Vijay Anand Korthikanti和Kevin J. Shih在实现推理CUDA内核方面给予的慷慨支持。
参考文献
- HiFi-GAN(用于生成器和多周期判别器)
- Snake(用于周期性激活)
- Alias-free-torch(用于抗锯齿)
- Julius(用于低通滤波器)
- UnivNet(用于多分辨率判别器)
- descript-audio-codec和vocos(用于多频带多尺度STFT判别器和多尺度梅尔谱图损失)
- Amphion(用于多尺度子频带CQT判别器)











